

#2. Your Best Friend - ML Monitoring
Part 2: Mastering the Art of Monitoring Deep Learning Systems That Use Unstructured Data


In the last newsletter, we covered how to monitor an ML system that uses structured data.
In that case, you can easily talk about distributions and leverage techniques such as PSI, KL Divergence, JS Divergence, etc.
Now let’s look at how to adapt what we’ve learned for unstructured data such as images or text.
As a short reminder from the last newsletter, when a model is in production, you can acquire the GT in 3 different scenarios:

Also, from your ML pipeline, you can analyze the following:
the model inputs
the model outputs
the actuals/ground truth
While in production, when you don’t have access in time to your GT, you can use drift metrics as a performance proxy.
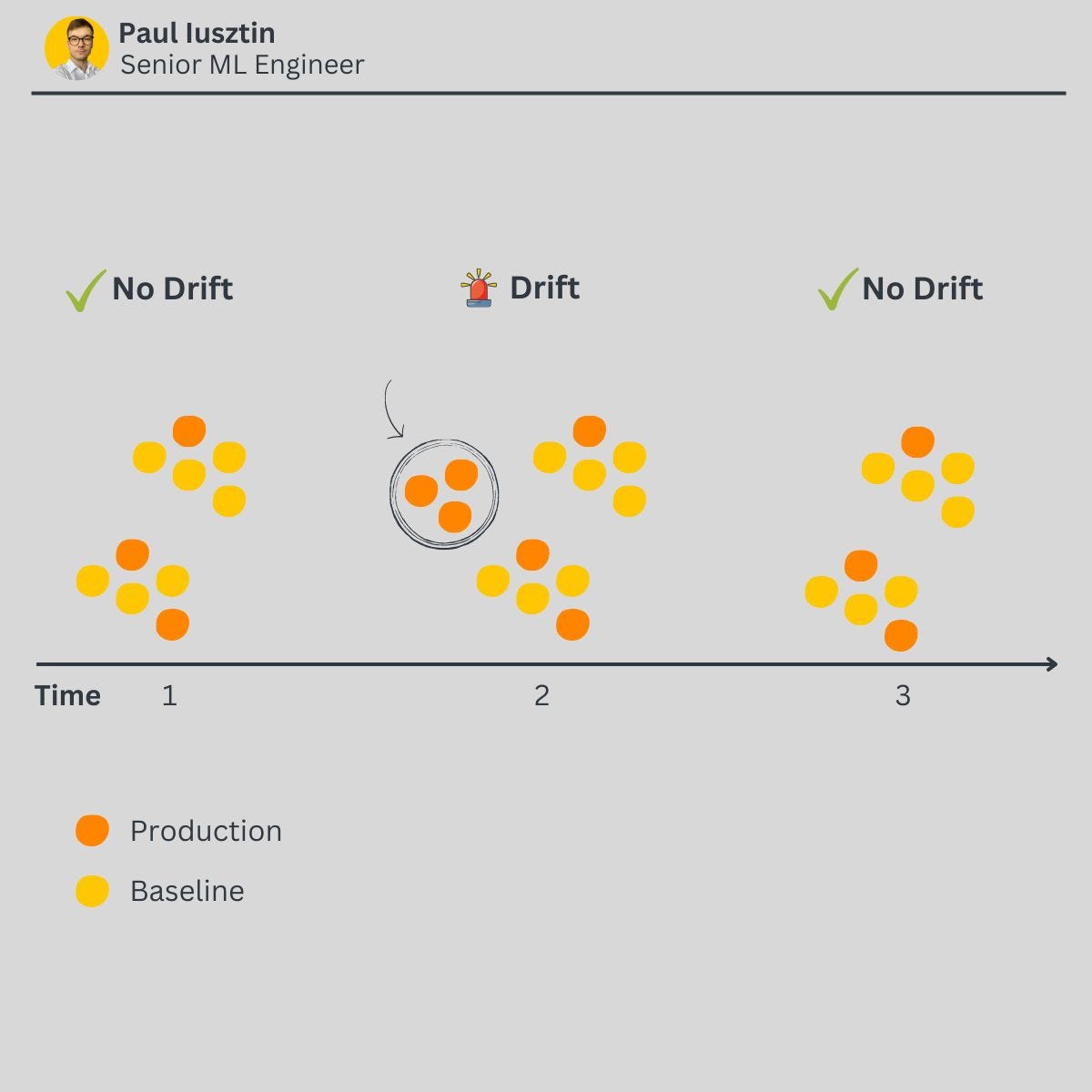
Drifts for Unstructured Data
When it comes to monitoring unstructured data, you have two main scenarios:
Computer Vision
Drift can occur in production due to the following:
- drastic changes in the pixel distribution due to blurry, spotted, lightened, darkened, rotated, and cropped images
- new objects
- new unique situations, events, and interactions
For example, your training dataset contained only bounding boxes with one cat and in production, the model encountered images with groups of cats or multiple animals.
NLP
Drift can occur in production due to the following:
- new words
- new category
- new language
- changes in terminology of words
Embeddings
When manipulating unstructured data, everything revolves around embeddings.
You can effortlessly encode the text, an image, a video, etc., using an embedding.
If you already have a model, you can use it to compute your embeddings (e.g., the output of the last fully connected layer before classification) or use a generic global model (e.g., BERT from HuggingFace, GPT from OpenAI, etc.).
After you set your baseline (e.g., your training dataset or a window from the past from your production dataset) and production window, you compute the average of the embeddings for every window.
Now you will have two averaged embeddings: one for the baseline and one for the production window.
The last step is to pick a metric to compare them, such as IOU, euclidean distance, cosine distance, or clustering-based group purity scores.
Using Euclidean distance would be a great start.
How to Compute Embeddings
When you think about embeddings, you might associate them with deep learning, but I have to tell you there are other ways to compute them, such as using SVD or PCA.
If you are familiar with recommender systems, you have often seen that in the matrix factorization techniques used for collaborative filtering.
There is nothing wrong with these techniques, but they have their limitations, such as not responding well to missing data.
There is where neural networks kick in.
One first well-known initiatives to compute embeddings is word2vec.
Again, nothing wrong with this method. Everything I mentioned above is still widely used in the industry.
But, unstructured data is most commonly processed by deep neural networks. Thus, I will boil it down to two prominent cases.
#1. You are using your own DL model
You have the most control; you must know and apply the proper method to extract the embedding from your model.
You don't have to implement additional models. You must understand the model's architecture and use the proper extraction techniques.
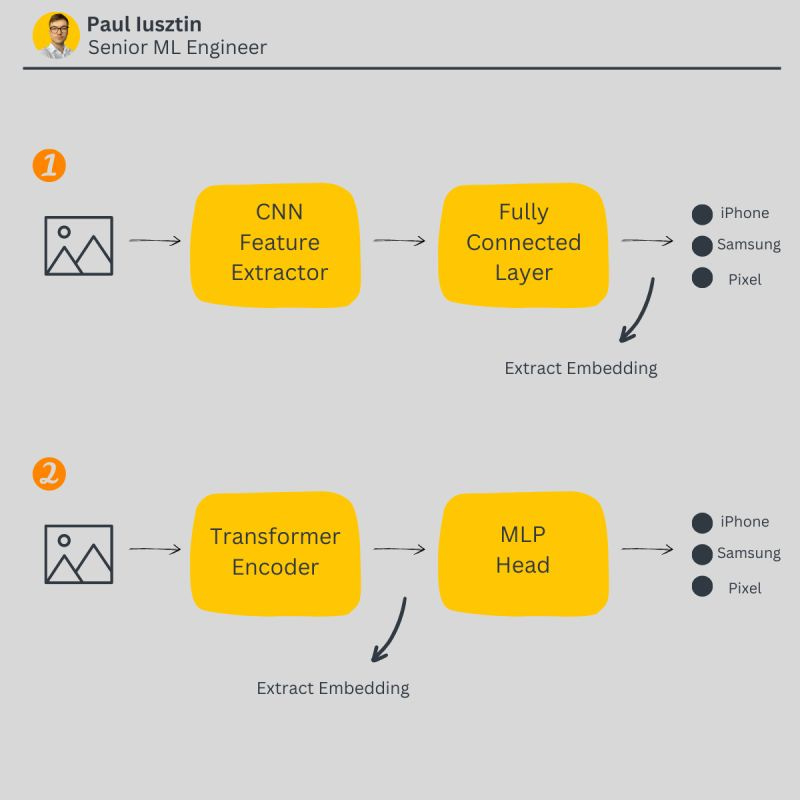
When we are aiming to embed an image, we can have these two scenarios:
1. When classifying with a CNN-based model, you can extract the embedding right before the last classification layer, as seen in Fig. 1.
2. When classifying with a transformer-based model, you have to extract the embedding right before the MLP head, as seen in Fig. 2.
The network's output is a vector with rich information about the image at these extraction points.
#2. You are using a global pretrained model
This is the easiest method, as you can use pretrained models such as BERT from Hugging Face or GPT from OpenAI.
Unfortunately, you lack control using this method, and the embeddings won't be fine-tuned for your particular use case.
But this is a great starting point for many projects.
But why do we love embeddings so much?
Because embeddings became the most widely used interface between models, just like a REST interface between different microservices.
Also, you can quickly compose embeddings using simple operations such as distances, projections, additions, averages, etc., and they still keep their meaning in the vector space.
Why Data Versioning is Crucial When Using Different Extractions Methods
I showed you a few examples of extraction methods for various models.
But what happens if you want to change the extraction method or model to compare the performance?
Most probably, it will soon become a mess.
We all encountered situations such as: "final_model," "best_final_model," "best_final_final_model," etc. You get the idea... It is tough to keep track of our changes.
3 types of changes can occur when extracting embeddings:
#1. Change your model architecture
This is considered a major change: O.x.x
Changing your model architecture might change the semantics of the embeddings and their dimensionality. Also, as a by-product, it changes your extraction method, and you must retrain your model.
#2. Change your extraction type
This is considered a minor change: x.O.x
Again this might result in changes in your semantics or dimensionality, but you don't have to retrain your model.
#3. Retrain your model
This is considered a patch version change: x.x.O
This won't change your embedding structure, but by retraining, they won't be compatible with your old set of embeddings as the vector space might change.
As you see, your embeddings will change quite often, that is why you need to...
Version your data!
Data versioning is one key aspect of a clean ML system.
Every change will result in a new data version. Then, when you use a specific set of embeddings, you will know exactly how they were computed.
You can easily version your data directly in the feature store for structured data. You can quickly add data versioning for unstructured data using tools such as S3 + DVC/your custom software.

Top References to Continue Your Reading About ML Monitoring
I trimmed them for you to 3 key resources:
A series of excellent articles made by Arize AI will make you understand what ML monitoring is all about.
The Evidently AI Blog, where you can find answers to all your questions regarding ML monitoring.
The monitoring hands-on examples hosted by DataTalksClub will teach you how to implement an ML monitoring system.
After wasting a lot of time reading other resources...
Using these 3 resources is a solid start for learning about monitoring ML systems.
Final Thoughts
Thank you for reading my newsletter. I am excited to share my ML journey with you.
To conclude…
This week you learned about the following:
monitoring unstructured data
how to compute embeddings
why versioning your embeddings is crucial
Check your inbox on Thursday at 9:00 am CET to learn more.
Have a great weekend!
💡 My goal is to help machine learning engineers level up in designing and productionizing ML systems. Follow me on LinkedIn and Medium for more insights!
Creating content takes me a lot of time. To support me, you can:
Join Medium through my referral link - It won't cost you any additional $$$.
Thank you ✌🏼 !