

Add this project to your ML/GenAI Portfolio
Attach this project to your portfolio. Serving models the efficient way. 5 Large Scale Training Parallelism techniques.

Decoding ML Notes
Kickstart your next week and build an end-to-end project.
Too many resources on how to build stuff are theoretical and focus less on the practical side. Break that loop and use the actionable insights found in today’s notes session.
This week’s topics:
How to build a real-time news search engine
The best model serving framework
How to parallelize training efficiently?
Build a real-time Kafka & VectorDB Search Engine
This week, at Decoding ML I’ve developed a mini-course that showcases how one can use serverless Kafka, VectorDB, Bytewax, and Streamlit to build an end-to-end project - A real-time news Search Engine!
This is a great project one could add to its portfolio. It covers some of the most important underlying concepts of building LLM-centered applications.
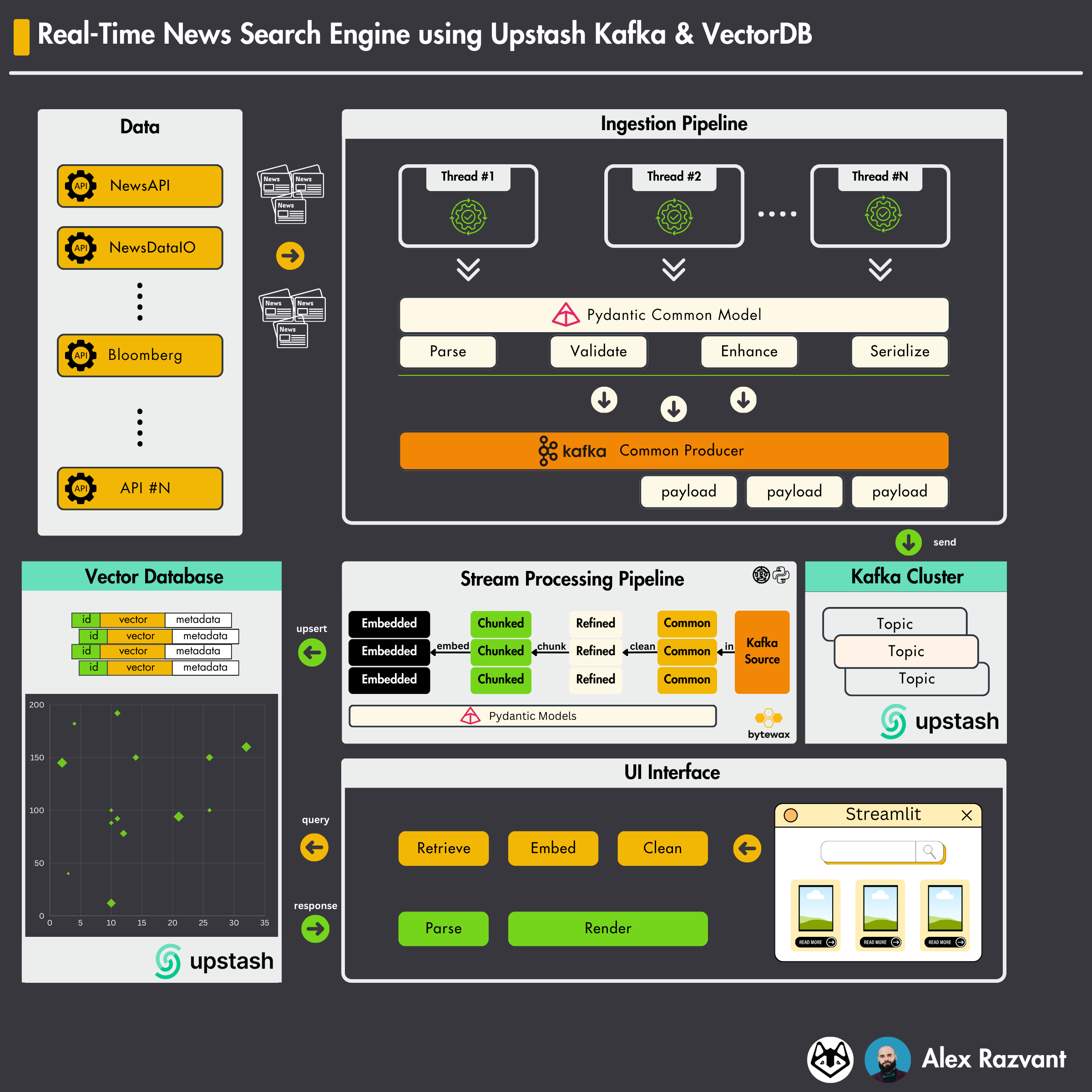
Even as a beginner, following this course you’ll learn about:
How to connect and use serverless Upstash Kafka.
How to connect and use the serverless Upstash Vector DB.
How to use threading and Singleton pattern to optimize I/O operations.
Validate data-exchange models using Pydantic.
Key concepts within a RAG (retrieval augmented generation).
Use Bytewax to build a fast and complex stream-processing pipeline.
How to build and render a stylish Streamlit UI interface.
Unit tests, Python PEP8 best practices.
⤵️⤵️⤵️
If you’re interested, make sure to check the article and build it step-by-step.👇
The best model serving framework
Model serving is an essential step in building machine-learning products. It comprises packaging models, building APIs, monitoring performance, and scaling to adjust to incoming requests.
Here are a few common ones:
TensorFlow Serving
TorchServe
Nvidia Triton Inference Server
BentoML
Seldon Core
Today we’ll talk about the NVIDIA Triton Server and why I recommend learning about it for mid-large scale deployments.
It’s true, that the learning curve might be slower compared to other methods because you have to grasp general NVIDIA ecosystem concepts, but here’s why Triton remains the king of DL / GenAI model serving:
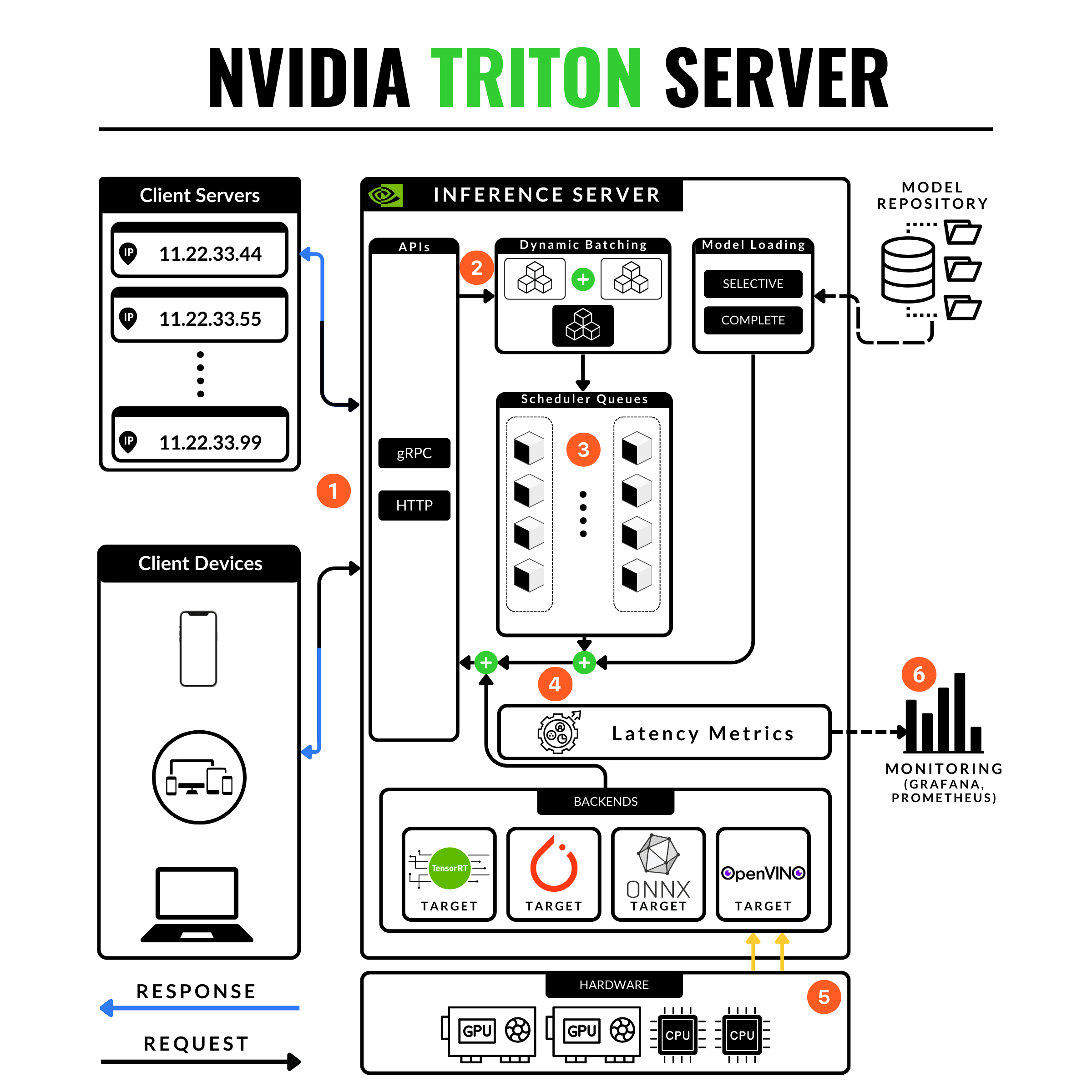
Concurrent model execution: Allows multiple instances of a model to be loaded onto a single GPU. This enables an increase in performance proportional to the number of replicas on the same hardware.
Framework support: Triton offers the most extensive ML framework support, native TensorRT, TensorFlow, PyTorch, ONNX formats, and even Python wrappers over ML models.
In-depth monitoring: Triton offers an embedded Prometheus service for GPU & Cluster monitoring.
Dynamic Batching: Smartly batches incoming requests to improve throughput, based on the specified parameters in the model deployment configuration file.
Simplified Management: Easy to integrate with Kubernetes for smooth scalability and management in production environments.
Cloud Integrations: For cloud deployments, Triton can be easily set up on AWS (SageMaker) or Azure Cloud.
GenerativeAI Formats: If you’re working with GenAI models (LLMs, StableDiffusion) you could use the TensorRT-LLM as the engine executor and optimize and deploy fast, low-latency LLM models at scale.
Performance Profiling: Before deploying a model, the Triton Server SDK allows you to profile and test your model to identify bottlenecks (hardware & software) and optimize for throughput, footprint, latency, and data exchange.
Documentation: In-depth and comprehensive documentation, alongside the package compatibility matrix where you can find and link a Triton version with each other sub-service (Torch, TensorRT, CUDA, CUDNN, etc)
⤵️⤵️⤵️
If you’re interested in learning about how to deploy a model using NVIDIA Triton, this article I’ve written covers just that 👇
Open AI Model Training at Scale
In an extensive article from OpenAI Engineering, the research team discusses the various methods of efficient parallelization they’ve used to train the popular GPT models class at scale.
Here’s a summary:
✅ 𝗡𝗼 𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹𝗶𝘀𝗺
→ Fundamental approach without using parallel processing.
→ Involves training on a single GPU, limiting the model's size and speed.
✅ 𝗗𝗮𝘁𝗮 𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹𝗶𝘀𝗺
→ Distributes different subsets of data across multiple GPUs.
→ Requires synchronization of model parameters across GPUs to ensure consistency.
✅ 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲 𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹𝗶𝘀𝗺
→ Splits a neural network model into sequential segments across GPUs.
→ Reduces memory load / GPU but can lead to idle time.
→ Utilizes micro-batches to overlap computation and reduce wait times.
✅ 𝗧𝗲𝗻𝘀𝗼𝗿 𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹𝗶𝘀𝗺
→ Splits operations within a layer across multiple GPUs.
→For example, on transformer-based models it helps balance the compute load by dividing the matrix (matmul) into smaller, manageable segments.
✅ 𝗠𝗶𝘅𝘁𝘂𝗿𝗲 𝗼𝗳 𝗘𝘅𝗽𝗲𝗿𝘁𝘀 𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹𝗶𝘀𝗺
→ Using only a fraction of the network for each input, routing to different 'expert' subsets of the network.
→ Scales up model size without a proportional increase in computational cost.
→ Different experts can be hosted on different GPUs.
→ One example approach is to have many sets of weights and the network can choose which set to use via a gating mechanism at inference time.