

Agentic AI Engineering Guide
The 6 critical mistakes that silently destroy agentic systems


I have spent the past two years building and breaking AI agents in production. Along the way, I have seen the same patterns destroy systems over and over. This happens not because the models are bad, but because the system design is wrong.
Most agents fail silently. They work well in demos but drift unpredictably in production. Costs spike with no clear explanation.
Behavior becomes erratic, and every release feels risky. Ultimately, teams end up stuck in PoC purgatory, unable to ship, debug, or trust their own system.
The root cause is almost never the model. It is subtle system design mistakes that individually look small but compound into production disasters.
To fix this, together with Louis-François Bouchard, we created a diagnostic framework for six specific mistakes that cause agentic systems to break in production. Each has a clear problem, a reason why it happens, and a proven fix. Once you know what to look for, you can trace most production failures back to one of these patterns.
The first and most common failure starts right at the input level, where engineers mishandle the context window.
Mistake #1: Treating the Context Window as an Afterthought
When something breaks, the instinct is to add more context. Engineers add more rules, more history, more tools, and more examples. The assumption is that if the model sees everything, it will behave better.
But this turns the context window into a dumping ground instead of a carefully scoped working memory. As the context grows, the model starts to ignore instructions and apply constraints inconsistently. It hallucinates more and drifts across runs.
Latency spikes and costs compound. This is the lost in the middle problem. Many teams respond by splitting one giant prompt into dozens of smaller ones.
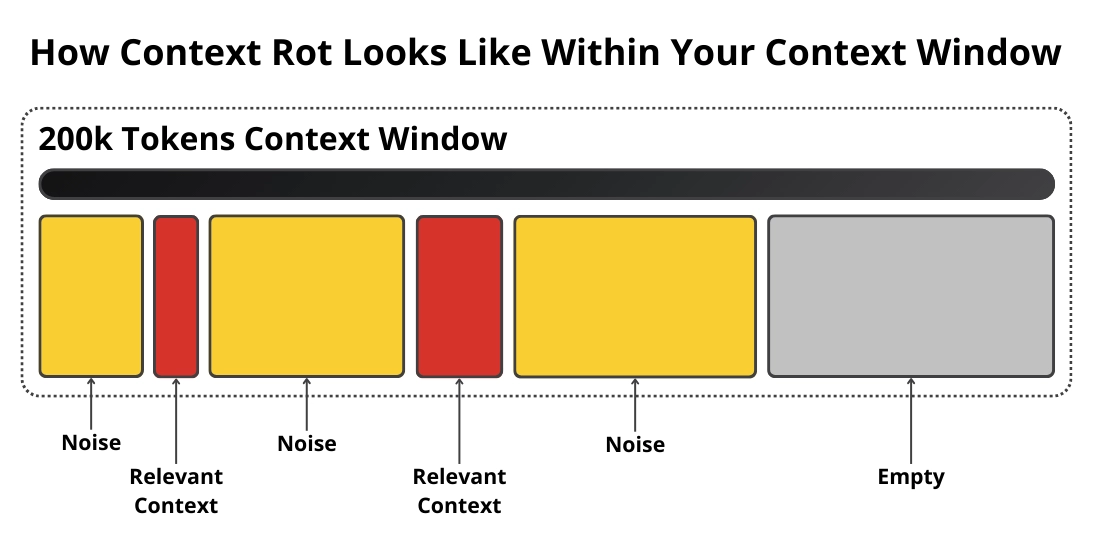
But that introduces its own problems, such as more LLM calls, higher latency, and harder debugging.
💡 Treat the context window as a scarce resource.
Every LLM call should have one clearly scoped job. You must curate context aggressively by selecting, compressing, and pruning before every call. Move persistence into a memory layer.
The context window holds only what matters for the next decision, and everything else lives in memory, which you write to and read from continuously.
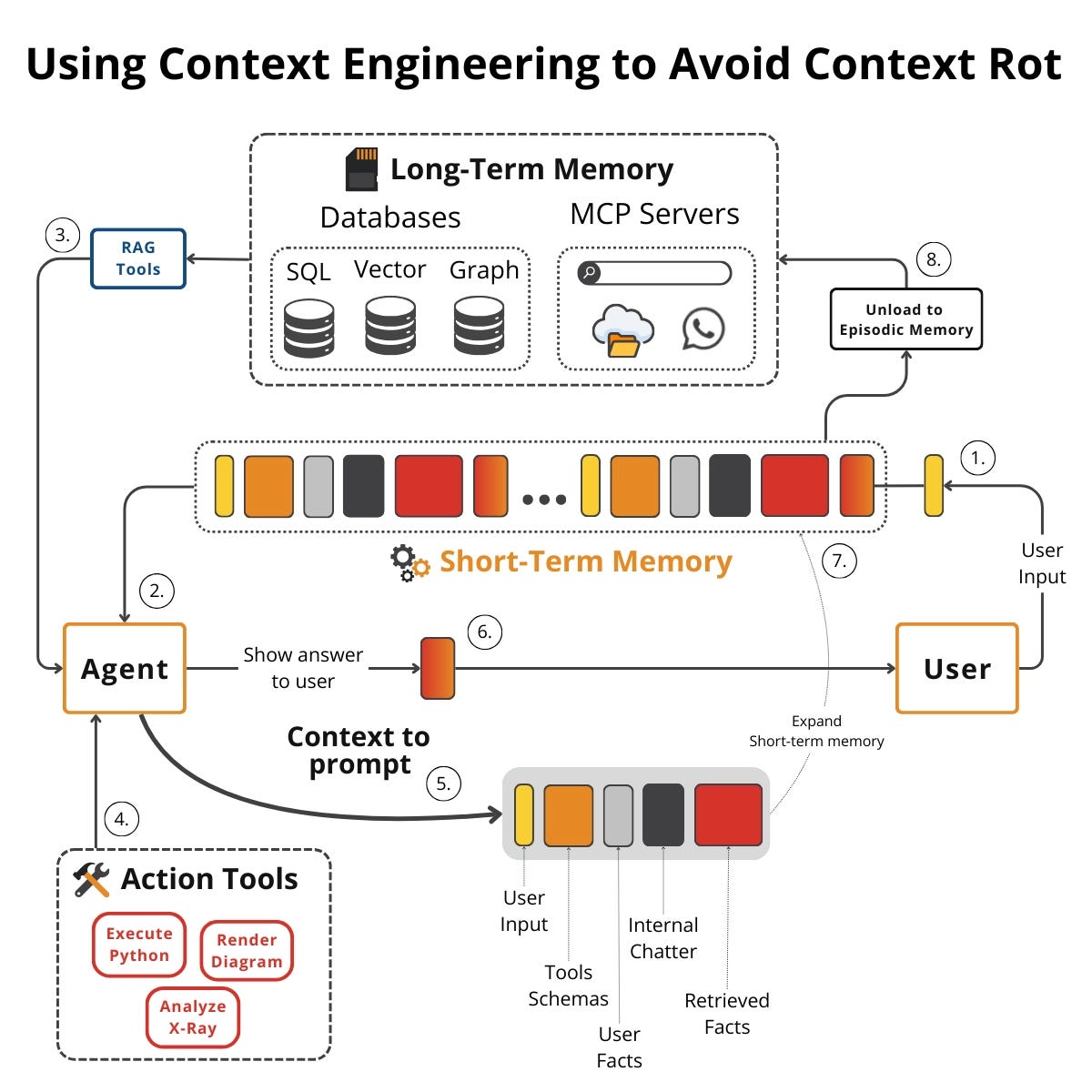
As a rule of thumb, start with a single prompt. If it works, stop. If it fails, do not jump to agents.
Introduce a small number of specialized steps and tune until you hit the balance. Context engineering is about deliberate selection.
Once the context window is secure, the next trap is overengineering the architecture before the problem demands it.
Mistake #2: Starting with Complicated Solutions
You have a clear problem, so you immediately reach for multi-agent architectures or heavy frameworks. You build RAG pipelines, hybrid retrieval, multiple databases, or adopt new protocols like MCP. You do this not because the problem demands it, but because it feels like the right way to build serious AI.
Every layer adds a hidden tax. You get more dependencies, higher latency, higher costs, and harder debugging. Complexity compounds operational pain.
Teams end up spending months building infrastructure and shipping nothing.
At our startup, ZTRON, we built a multi-index RAG system. We had OCR pipelines, separate embedding pipelines, hybrid retrieval, and agentic RAG loops.
It worked, but simple queries took 10 to 15 seconds. Costs climbed, and debugging was a nightmare.
When we finally asked if we actually needed all this, the answer was no. Our data fit within modern context windows. We replaced agentic RAG with cache-augmented generation (CAG) for most workflows.
This gave us fewer LLM calls, lower latency, fewer errors, and an easier system to debug.

Start with the simplest solution that could work. Prove the core task works first. Only add memory, tools, retrieval, or multiple agents when the problem demands it.
Production-grade AI is built by engineers who ship simple systems first and scale complexity intentionally.
Earning complexity often means realizing that you do not need an agent at all, which brings us to the third mistake.
Mistake #3: Building Agents When a Workflow Will Do
Predictable tasks like data ingestion, summarization, or report generation need predictable execution. That is a workflow. Open-ended tasks like deep research or dynamic decision-making under uncertainty may need autonomy.
Agents handle these open-ended scenarios. Most teams treat predictable problems as if they need agents. When you use an agent for a structured task, you pay for autonomy you do not need.
You get unpredictable behavior, variable latency, higher token usage, and inconsistent outputs. The system works 80% of the time and fails when it matters most.
Workflows and agents are not binary choices. They sit on a spectrum known as the autonomy slider. More autonomy buys flexibility but costs predictability, cost control, and debuggability.
You must set the slider intentionally.
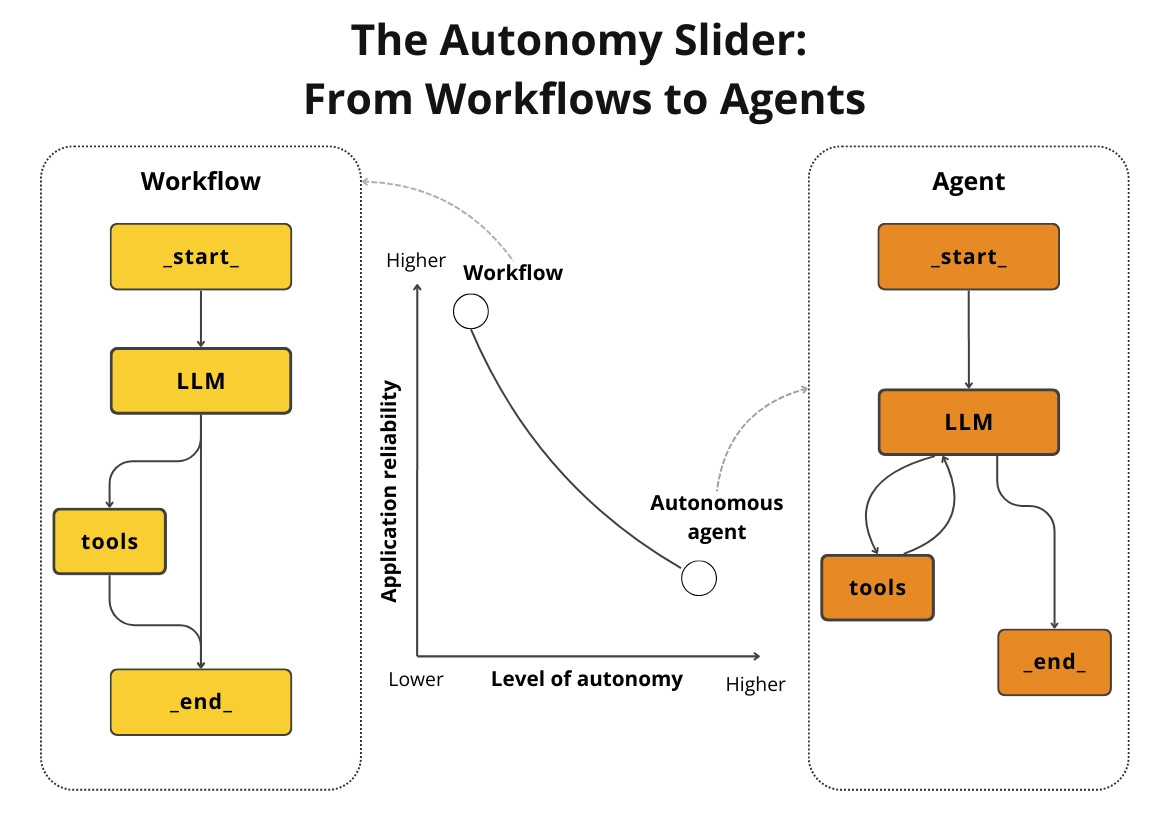
Adopt a workflow-first approach. Start with prompt chaining, routing, parallelization, or an orchestrator-worker pattern. Introduce agents only when the system must autonomously plan, explore unknown paths, or recover from failures dynamically.
For vertical AI agents, use a hybrid approach. Route known patterns to workflows and open-ended requests to agents.
Whether you use a workflow or an agent, you must handle the data they produce, which exposes a flaw in how engineers process outputs.
Mistake #4: Fragile Parsing of LLM Outputs
You ask the model for something structured, and it responds with something that looks structured. You parse it with regex, string splitting, or custom logic. It works in staging.
Then one day, a missing comma or different bullet style crashes production. LLMs are non-deterministic. Even with identical prompts, output can drift due to context changes, model updates, or variations in tool outputs.
Fragile parsing is a time bomb. Many teams respond by prompting the model to output JSON. That is better than free-form text, but it still is not a contract.
You still get missing keys, wrong types, and drifting nested fields.
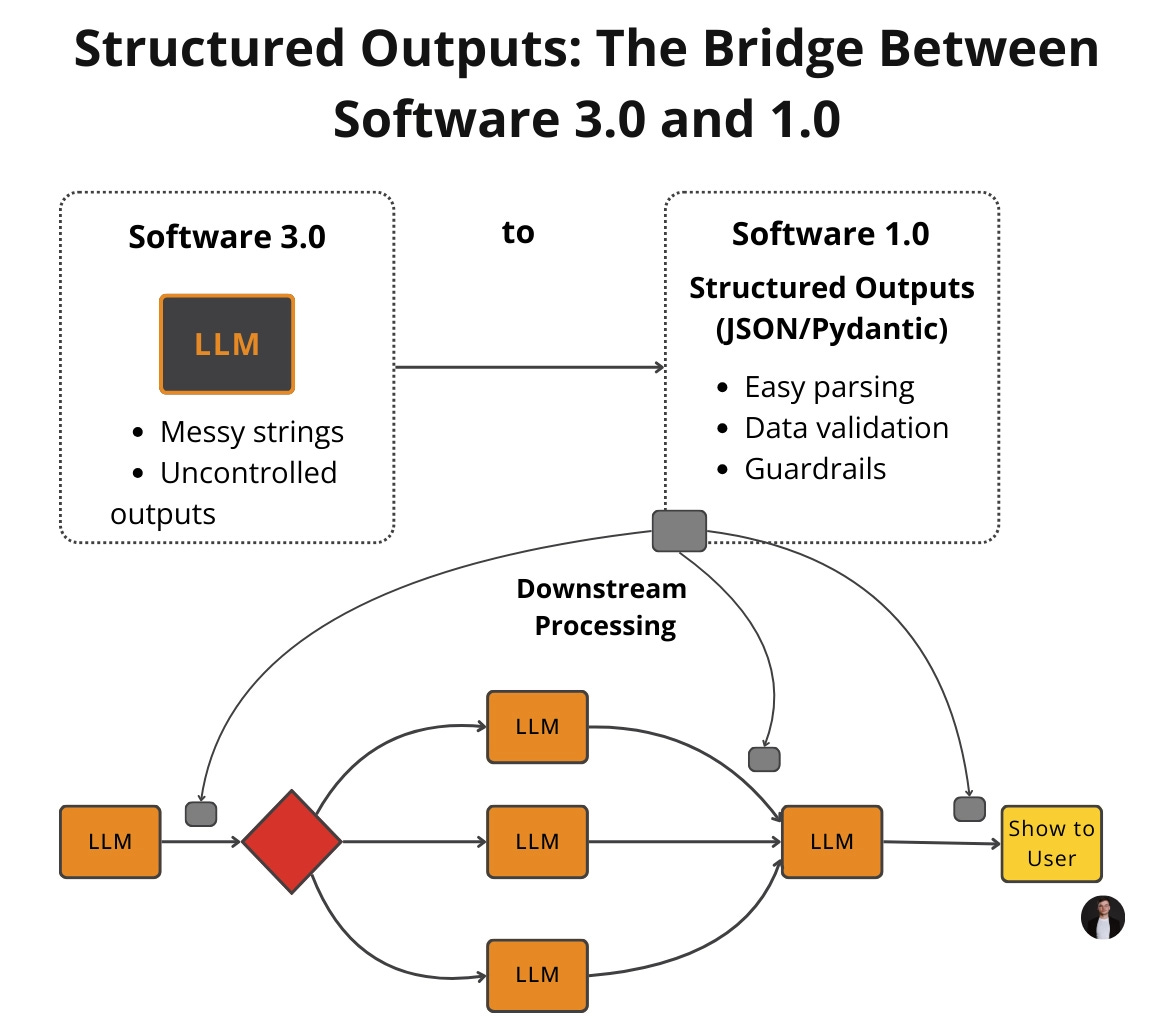
Stop treating LLM outputs like text and treating them like data. Define a schema, enforce it at generation time, validate at runtime, and fail fast when wrong. Use Pydantic as the bridge between probabilistic generation and deterministic code.
But only use structured outputs when structure is required. If you only need a plain string, accept a string and keep schemas shallow and minimal.
If you have secured your context, simplified your architecture, chosen the right autonomy, and enforced output schemas, you are ready to build an agent. However, many teams still fail by omitting actual planning from their loops.
Mistake #5: Forgetting Agents Need Planning
You give a model tools, let it pick one, feed the tool output back, and repeat. At a glance, it looks agentic, but it is just a workflow with randomness. The system is reacting to the last tool output, not driving toward a goal.
Without embedded planning, the loop cannot decompose tasks into meaningful steps. It cannot evaluate progress or choose next actions intentionally. The result is random behavior, unnecessary tool calls, infinite loops, and shallow reasoning.
Copying ReAct or Plan-and-Execute from blog posts without adapting them to your domain makes it worse.
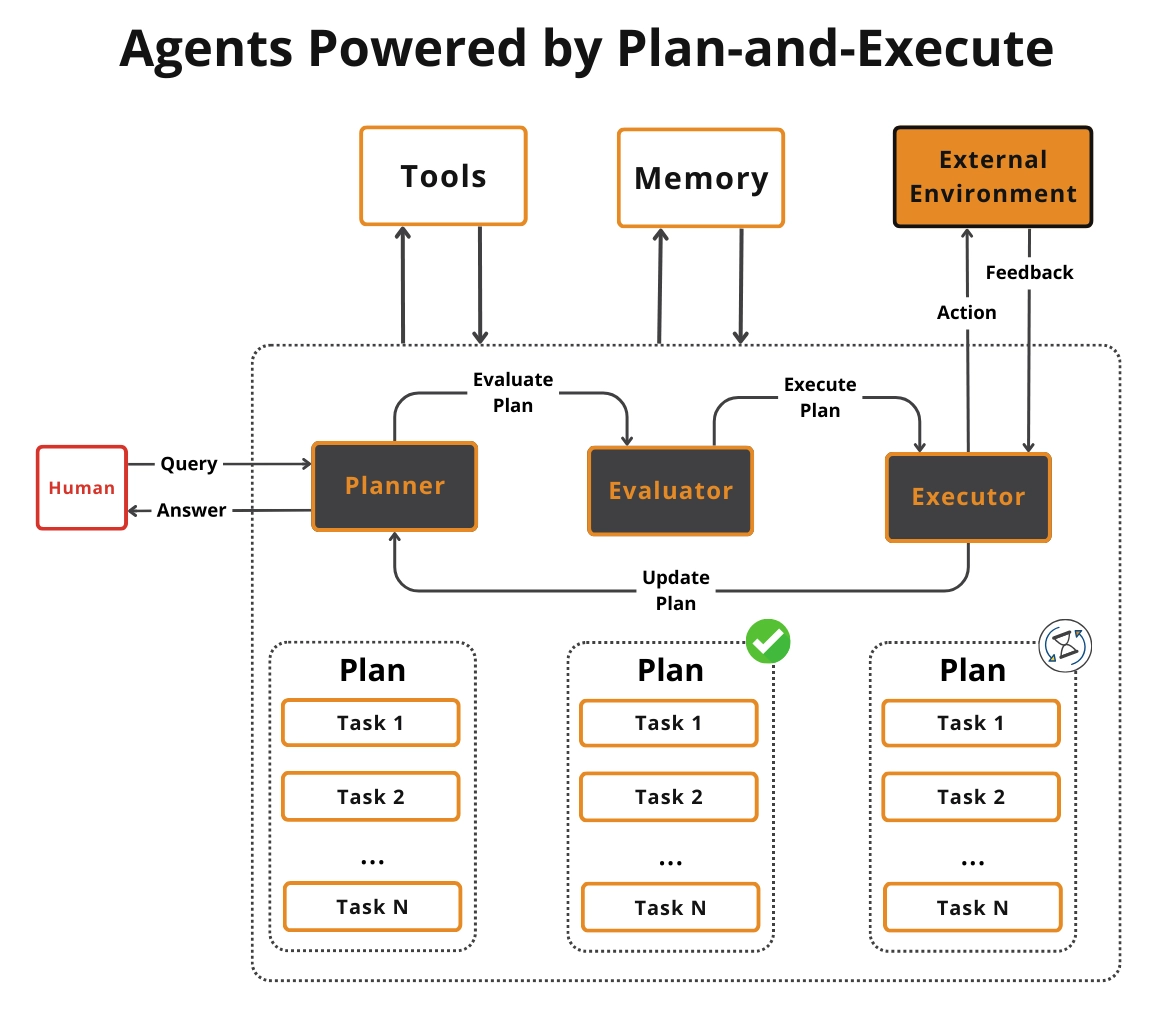
You must embed planning into the loop. Before calling a tool, require a reasoning step. Ask what the goal is, what the next best action is, and what evidence you need.
Add progress checks and stop conditions like max steps, token budgets, and escalation when stuck. Make planning use-case specific, because generic ReAct is not a product. Tailor planning to your tools, data, constraints, and failure modes.
Even a well-planned agent will degrade over time if you do not measure its performance continuously.
Mistake #6: Not Starting with AI Evals from Day Zero
You build features without tracking how well your AI behaves. You have no tests, no evaluation metrics, and no defined success criteria. Every new feature is a gamble, and teams silently ship regressions.
AI systems do not fail all at once. They decay. A prompt change, a new tool, or a model upgrade causes subtle behavior shifts.
Without evals, nobody can answer whether a change made the system better or worse. Teams get stuck relying on vibe evals, which are manual, gut-feel testing that does not scale. Many teams think they are doing evals, but rely on generic scores like helpfulness or 1-5 star scales.
A score of 3.7 helpfulness tells you nothing about what to fix.
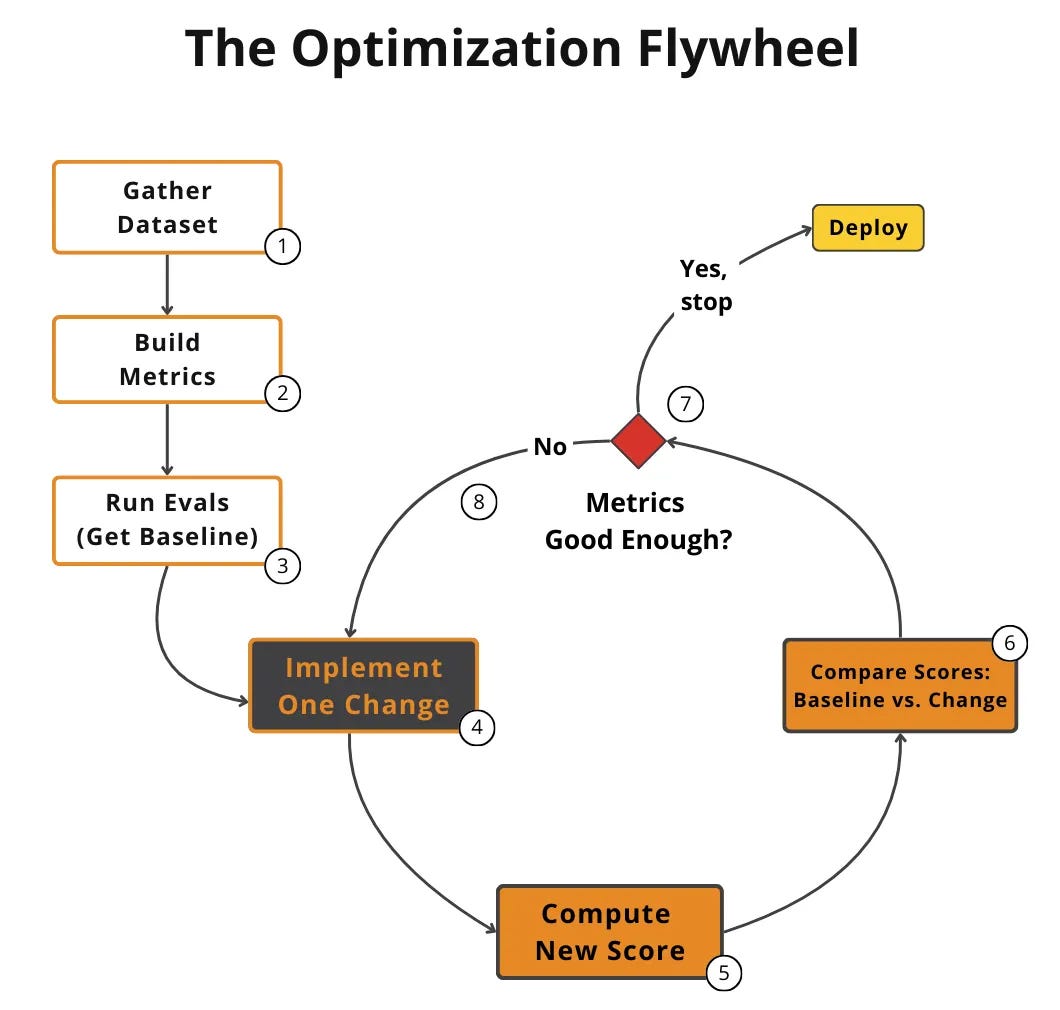
Use evals as your north star. Define task-specific, binary metrics tied to real system behavior and business requirements from day one. Use evals to drive the optimization flywheel.
Integrate evals into your development workflow to catch regressions before users do.
Recognizing these six mistakes is the first step to escaping PoC purgatory.
Conclusion
These six mistakes are not exotic edge cases. They are the exact patterns that repeatedly break real agentic systems. Individually, they look small, but in production, they compound into disasters.
Each of these mistakes deserves a deeper breakdown with real examples and production-tested fixes. That is why we turned them into a free 6-day email course. We cover one mistake per day, with the exact patterns and solutions we use in production.
💡 If you want the complete breakdown, sign up here.
Otherwise, see you next Tuesday.
What’s your opinion? Do you agree, disagree, or is there something I missed?
Enjoyed the article? The most sincere compliment is to share our work.
Whenever you’re ready, here is how I can help you
Go from agent user to agent builder. Master the foundations of AI agents and turn fragile demo code into reliable, production-ready systems with my course, Agent Engineering: Building Multi-Agent Systems (made with Towards AI).
35 lessons. Pure foundations from scratch. 4 mini-projects. 2 production systems. A certificate and direct access to me & industry experts in our Discord.
Built for software and data professionals transitioning into AI engineering. Rated 5/5 with 300+ students. The first 7 lessons are free:
Not ready to commit? Start with our free Agent AI Engineering Guide, a 6-day email course on the mistakes that silently break AI agents in production.
Images
If not otherwise stated, all images are created by the author.
 | A guest post by
|
We spent weeks going back and forth on these patterns while writing this and mistake #1 still surprised me with how often it comes up in our community. Context window mismanagement is probably responsible for 80% of the "my agent stopped working" messages we get. Glad we finally put this into a structured framework people can reference!
"These six mistakes are not exotic edge cases. They are the exact patterns that repeatedly break real agentic systems. Individually, they look small, but in production, they compound into disasters."
excellent conclusion here. context mistakes are one of the more common ones and this article was really well written.