

Building Reliable AI Agents with Durable Workflows
How to make agents resilient to any failure


Paul: Today’s article is from Peter Kraft, a Stanford PhD and co-founder of DBOS, who’s obsessed with building reliable AI systems.
He’s got the receipt. Let’s get into it 👀 ↓
It’s tough to build AI agents that run reliably in production. Failures can happen at any time for any reason–because an API had an outage, because you were rate-limited, because your server crashed, because the LLM returned a malformed output, or for dozens of other reasons. And when failures happen, the nondeterministic nature of agents makes it difficult to figure out exactly what happened or to recover affected users.
One tool that helps make it easier to build reliable agents is durable workflows. Essentially, these work by regularly checkpointing the state of your agent to a database. That way, if your agent ever fails, your program can look up the last checkpoint and recover the agent from its last completed step.
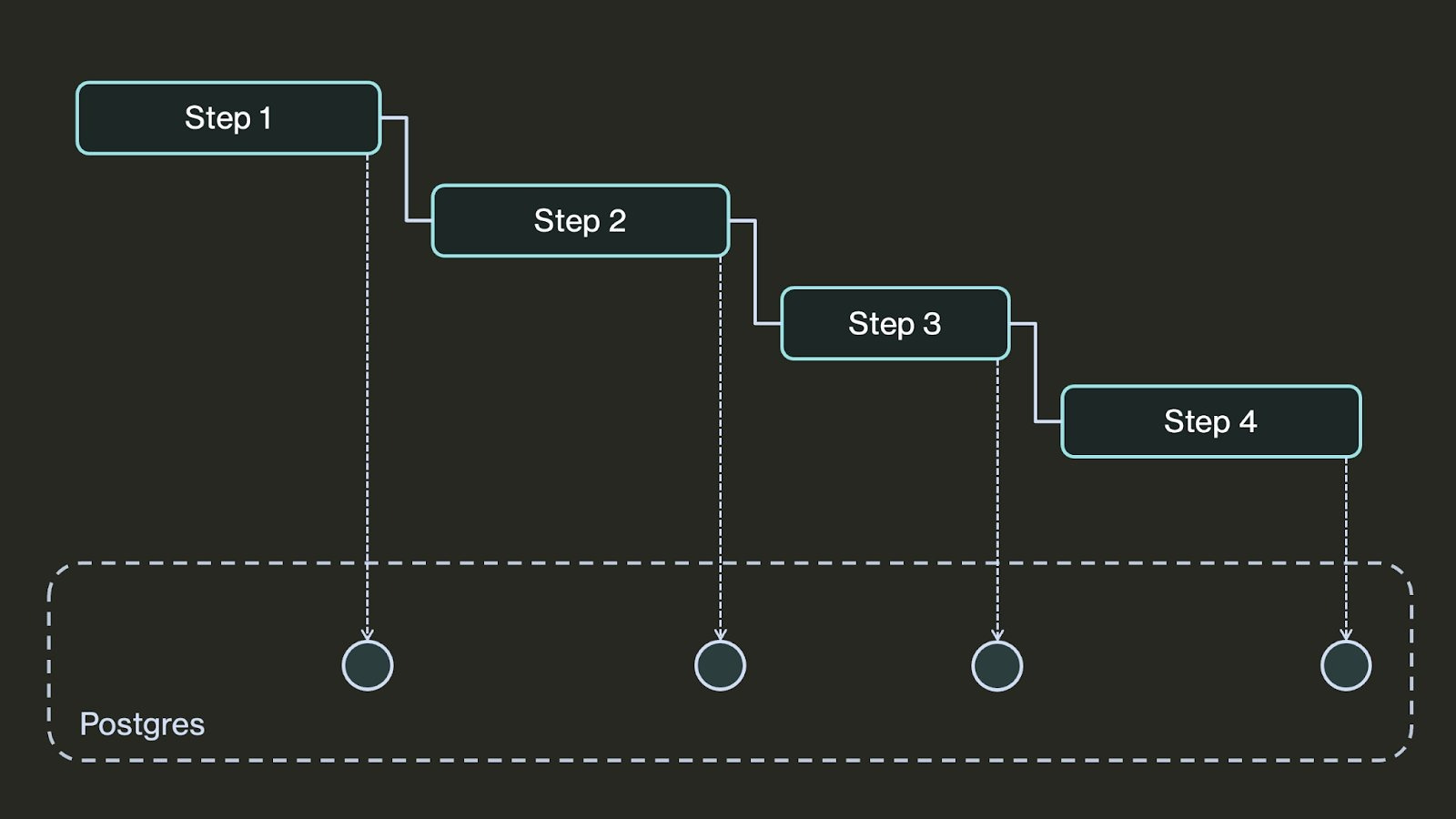
You can think of workflows as working like save points in a video game. They regularly “save” your agent’s progress (by checkpointing), and if there’s a failure, your agent can “reload” from the latest checkpoint.
Most popular workflow systems, like Prefect, Airflow, or Temporal, work via external orchestration. At a high level, their architectures look like this:
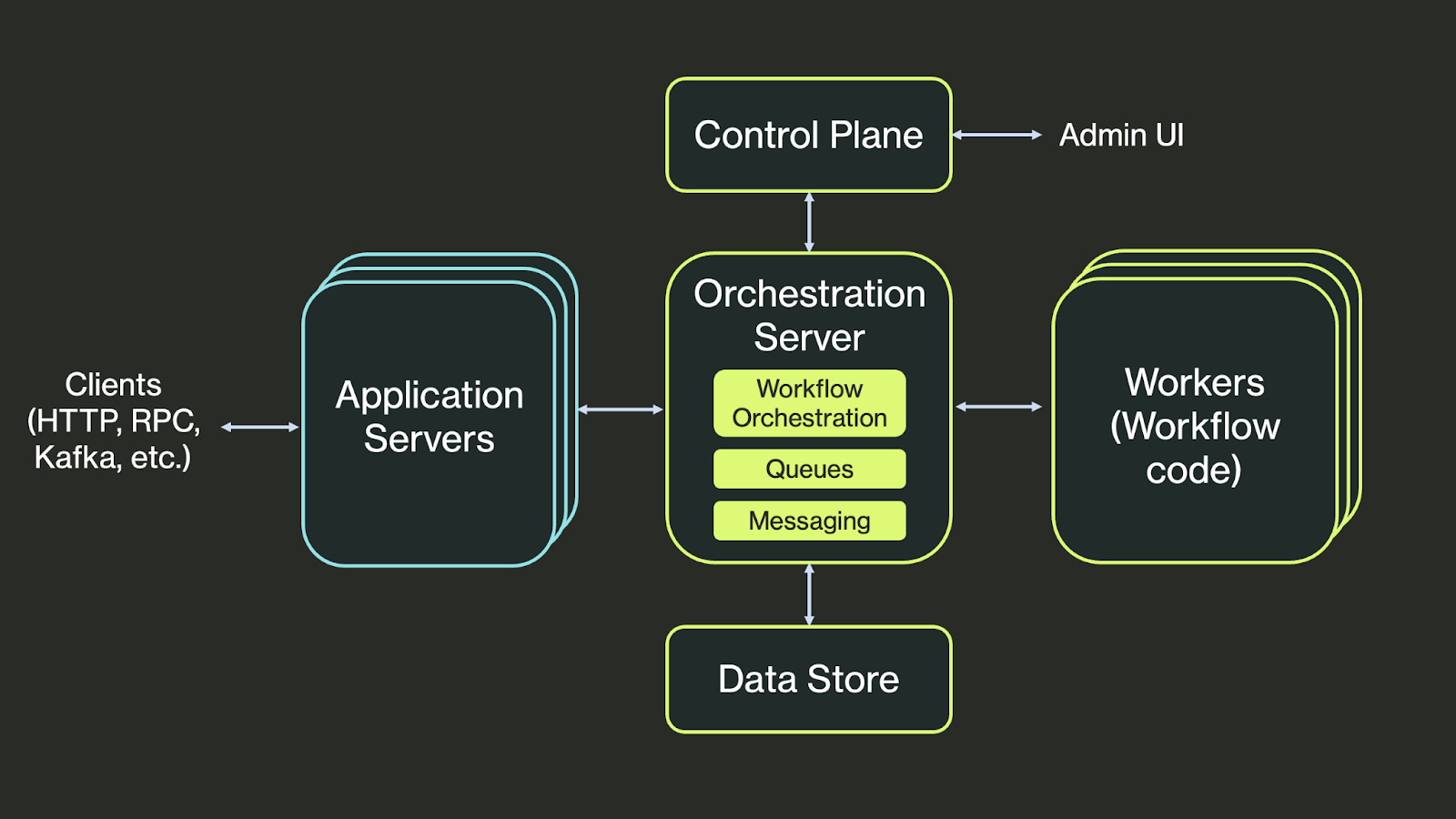
Externally orchestrated systems are made up of an orchestrator and a set of workers. The orchestrator runs workflow code, dispatching steps to workers through queues. Workers execute steps, then return their output to the orchestrator, which persists that output to a data store, then dispatches the next step. Application code can’t call workflows directly, but instead sends requests to the orchestrator server to start workflows and fetch their results.
External orchestration is effective but complex, and adopting it requires rearchitecting your app to fit its model. However, workflows don’t require this complexity anymore. In this blog post, we’ll highlight a new and simpler durable workflow solution: DBOS. DBOS implements durable workflows in a lightweight library built on top of Postgres. Architecturally, an application built with DBOS looks like this:
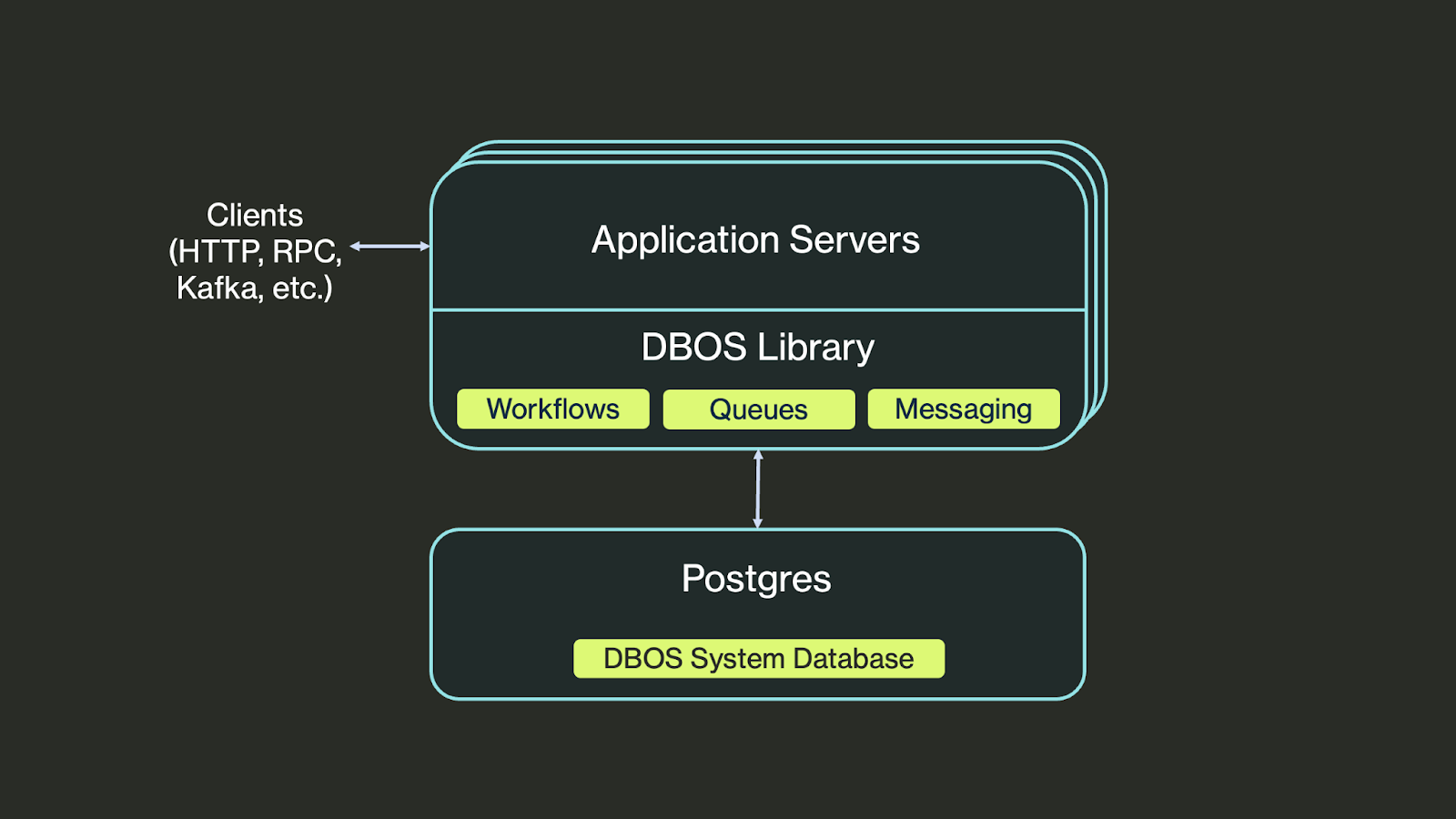
You install the DBOS workflows library into your application and start annotating your code as workflows and steps. The library checkpoints your workflow and step executions to a database like Postgres, then uses those checkpoints to recover your application from failures. There’s no rearchitecting required and no external dependencies except a database to store checkpoints.
To make this more concrete, we’ll show a demo of building a reliable AI agent with DBOS. Specifically, we’ll build a deep research agent for Hacker News. You give it a topic, and it will iteratively research Hacker News stories and comments for that topic and related topics until it’s learned enough to synthesize a research report.
The core of the agent is a main loop that takes in a topic and iteratively runs the following steps:
Research Hacker News for information on the topic, using Algolia to find top stories and comments.
Decide if enough information has been collected, breaking the loop if so.
If more information is needed, generate a follow-up topic to research in the next loop iteration.
After enough information has been collected, the agent synthesizes a research report based on all the stories and comments it has read.
Here’s the main loop in code:
@DBOS.workflow()
def agentic_research_workflow(topic: str, max_iterations: int):
“”“The agent starts with a research topic then:
1. Searches Hacker News for information on that topic.
2. Iteratively searches related queries, collecting information.
3. Makes decisions about when to continue
4. Synthesizes findings into a final report.
The entire process is durable and can recover from any failure.
“”“
all_findings = []
research_history = []
current_iteration = 0
current_query = topic
# Main agentic research loop
while current_iteration < max_iterations:
current_iteration += 1
# Research the next query in a child workflow
iteration_result = research_query(topic, current_query, current_iteration)
research_history.append(iteration_result)
all_findings.append(iteration_result[”evaluation”])
# Handle cases where no results are found
stories_found = iteration_result[”stories_found”]
if stories_found == 0:
# Generate alternative queries when hitting dead ends
alternative_query = generate_follow_ups_step(
topic, all_findings, current_iteration
)
if alternative_query:
current_query = alternative_query
continue
# Evaluate whether to continue research
should_continue = should_continue_step(
topic, all_findings, current_iteration, max_iterations
)
if not should_continue:
break
# Generate next research question based on findings
if current_iteration < max_iterations:
follow_up_query = generate_follow_ups_step(
topic, all_findings, current_iteration
)
if follow_up_query:
current_query = follow_up_query
# Final step: Synthesize all findings into comprehensive report
final_report = synthesize_findings_step(topic, all_findings)
# Return complete research results
return final_reportTurning this agent into a durable workflow requires very little code. First, we annotate the main loop as a durable workflow with the @DBOS.workflow decorator. Then, we annotate each operation the workflow performs (like fetching Hacker News comments or synthesizing findings) as a step. This tells the workflow to checkpoint after performing the operation so that the operation isn’t re-executed during recovery. We should annotate every nondeterministic operation in our workflow (such as external API calls like searching Hacker News or LLM calls like synthesizing findings) as a step. For example:
@DBOS.step()
def synthesize_findings_step(topic: str, all_findings: List[Dict[str, Any]]):With those annotations in place, our agent is durable. Now, if it ever fails, we can just restart it to recover it from the last completed step.
So, for example, if our agent crashes during its second loop iteration while researching “artificial intelligence,” upon restart, it will resume in that same loop iteration.
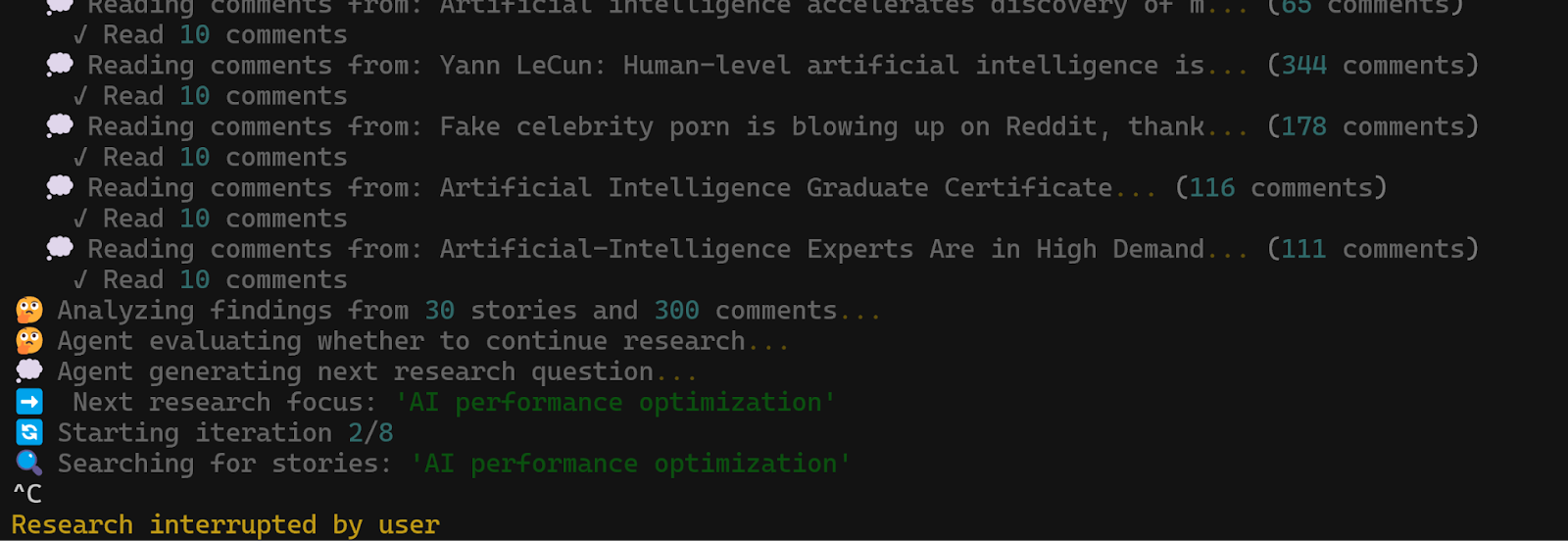
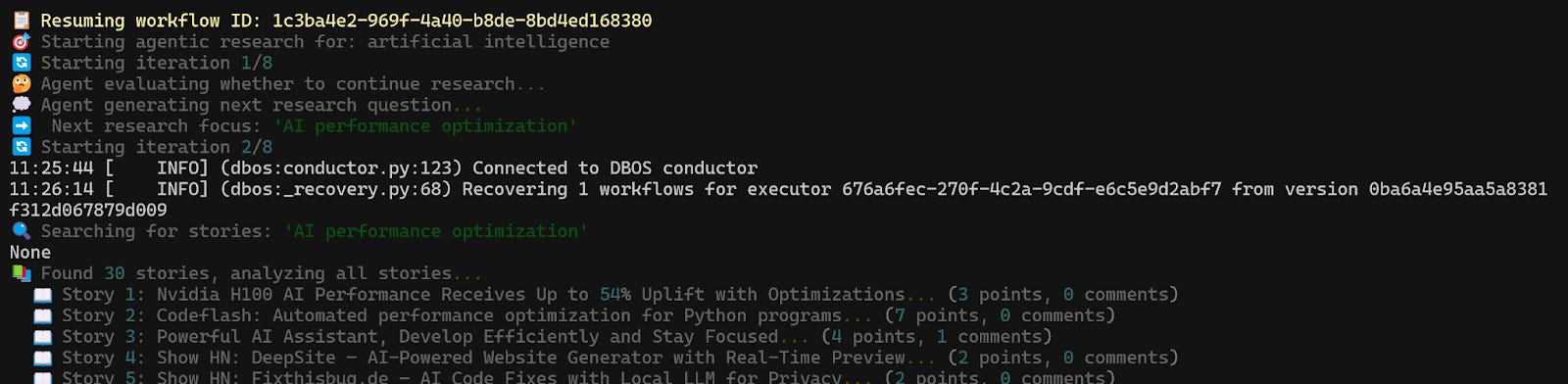
See the full demo here:
Durable workflows also provide advanced features that help our application scale. For example, instead of running workflows sequentially, we can durably enqueue them (using a database-backed queue) to reliably run many workflows concurrently across multiple workers. That allows us to research many topics simultaneously. We can also schedule workflows to run periodically using a database-backed cron or durably stream results from workflows.
Another benefit of durable workflows is observability. Because we’re checkpointing each step our agent takes in a database, we can visualize its progress in real time. For example, we can see exactly which topics it’s researching and what Hacker News stories and comments it’s reading:
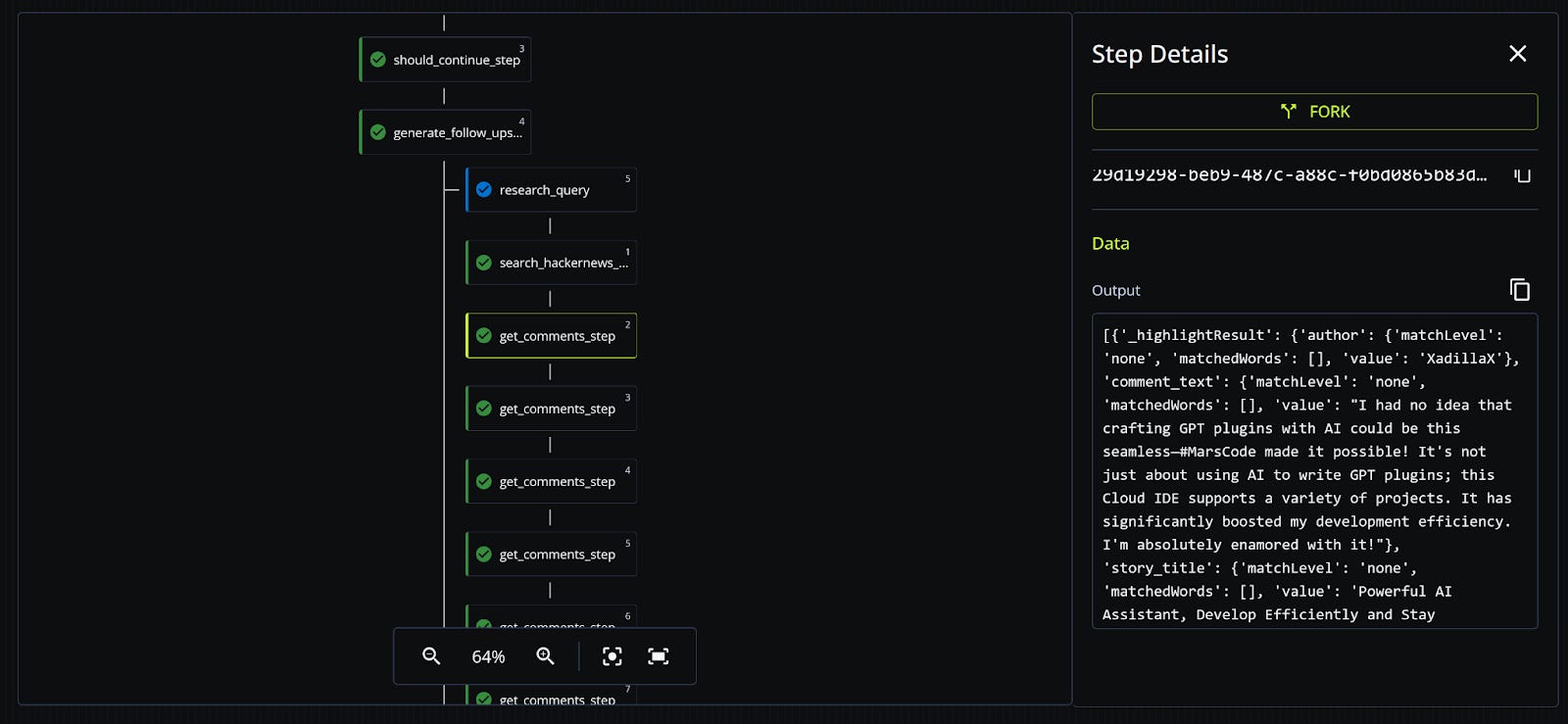
You can find the full code for this demo here, with a line-by-line walkthrough here.
If you want to try DBOS in your agents, check out the quickstart. You can use DBOS with any agent framework, but if you use Pydantic AI, DBOS has a native integration; check it out here.
See you next week.
What’s your take on today’s topic? Do you agree, disagree, or is there something I missed?
If you enjoyed this article, the ultimate compliment is to share our work.
Whenever you’re ready, here is how I can help you
Go from agent user to agent builder. Master the foundations of AI agents and turn fragile demo code into reliable, production-ready systems with my course, Agent Engineering: Building Multi-Agent Systems (made with Towards AI).
35 lessons. Pure foundations from scratch. 4 mini-projects. 2 production systems. A certificate and direct access to me & industry experts in our Discord.
Built for software and data professionals transitioning into AI engineering. Rated 5/5 with 300+ students. The first 7 lessons are free:
Not ready to commit? Start with our free Agent AI Engineering Guide, a 6-day email course on the mistakes that silently break AI agents in production.
Images
If not otherwise stated, all images are created by the author.
 | A guest post by
|
Yep self recovering agents catalogue for the good 😊
Thanks, Peter, for contributing this amazing piece!