

We Killed RAG, MCP, and Agentic Loops. Here's What Happened.
A brutally honest case study of building our vertical AI agent and shipping it to production.

I want to share a real story, directly from the trenches, about building ZTRON, the vertical AI agent I’ve been working on for the past year. It’s a case study on why we decided to severely limit RAG usage, why we regret starting to use MCP, and why we believe one-shot LLM calls are often better than agentic loops.
This article is based on a San Francisco presentation hosted by ZTRON: Stephen Ribbon (CEO), Jona Rodrigues (Cofounder / Principal) and me. ZTRON is the startup I’ve been working at for the past year as a founding AI engineer.
We hosted the presentation during the Antler start-up incubator program in SF in November 2025, where we worked on our vertical AI agent for financial advisors.

This is the second live presentation I have given in my entire life. The first one was at QCON London in March 2025, where, due to my social anxiety, I rehearsed my talk 10 times, afraid of making mistakes. This time, because I was too tired to prepare, I rehearsed once, spoke fluently, made eye contact, and connected.
I guess the secret is to be tired enough not to care. Joking. Don’t get me wrong. It wasn’t perfect. But it was a lot better!

Going back to our point. Let’s start digging into why we decided to STOP using RAG in many of our use cases and regret using MCP.
We started building ZTRON at the beginning of the AI agents hype, in early 2025. Meanwhile, as a start-up in a highly competitive space, we had to pivot multiple times before finding the best market fit.
That combined with the exploding AI landscape, where everyone was talking about RAG, Agentic RAG, Multimodal RAG, MCP, LangGraph, LlamaIndex, etc…
Resulted in a complex solution, relying on AI frameworks, complex RAG architectures, and an MCP layer that we haven’t really leveraged as intended.
The app was slow and unstable due to overuse of agentic RAG, and scaling the server was difficult because of our robust RAG ingestion pipeline.
This happened because it was challenging to make the right decision at the time, so, since any decision is better than no decision, we moved forward with what we thought was best.
The solution? It was time to strip away unnecessary complexity, return to fundamentals, and solve real business problems users actually want solved.
With that in mind, let’s walk through our engineering journey of building ZTRON, with its ups and downs, to see what we did right and wrong.
And ultimately, how we stabilized the product and shipped it to real-world users.
📣 Spoiler Alert: We are now in production, running a pilot, with ~100 users.
Let’s start.
But first, a quick word from our sponsor, Opik ↓
Opik: Open-Source LLMOps Platform (Sponsored)
This AI Agents Foundations series is brought to you by Opik, the LLMOps open-source platform used by Uber, Etsy, Netflix, and more.
But most importantly, we are incredibly grateful to be supported by a tool that we personally love and keep returning to for all our open-source courses and real-world AI products. Why? Because it makes escaping the PoC purgatory possible!

Here is how Opik helps us ship AI workflows and agents to production:
We see everything - Visualize complete traces of LLM calls, including costs and latency breakdowns at each reasoning step.
Easily optimize our system - Measure our performance using custom LLM judges, run experiments, compare results and pick the best configuration.
Catch issues quickly - Plug in the LLM Judge metrics into production traces and receive on-demand alarms.
Stop manual prompt engineering - Their prompt versioning and optimization features allow us to track and improve our system automatically. The future of AutoAI.
Opik is fully open-source and works with custom code or most AI frameworks. You can also use the managed version for free (w/ 25K spans/month on their generous free tier).
↓ Now, let’s move back to our article.
Started With Multi-Index RAG
Back in early 2025, the first component of our vertical AI agent was a fancy multi-index RAG architecture (just like everyone else in the industry at the time).
Our goal was ambitious but clear: we wanted our financial advisor agent to query any combination of data formats, such as text, PDFs, and images. We wanted users to be able to ask questions that required synthesizing information from a client’s portfolio PDF, an email summary, or a chart screenshot.
To achieve this, we built a massive ingestion beast. We ingested everything into a beefy index. We passed each file through OCR, created chunks, summaries, and rendered PDF pages into images. After, for each modality, we created embeddings, indexed them into a Postgres database using the pgvector and pgsearch extensions.
We then built a hybrid retrieval system that simultaneously queried and ranked all these indices.
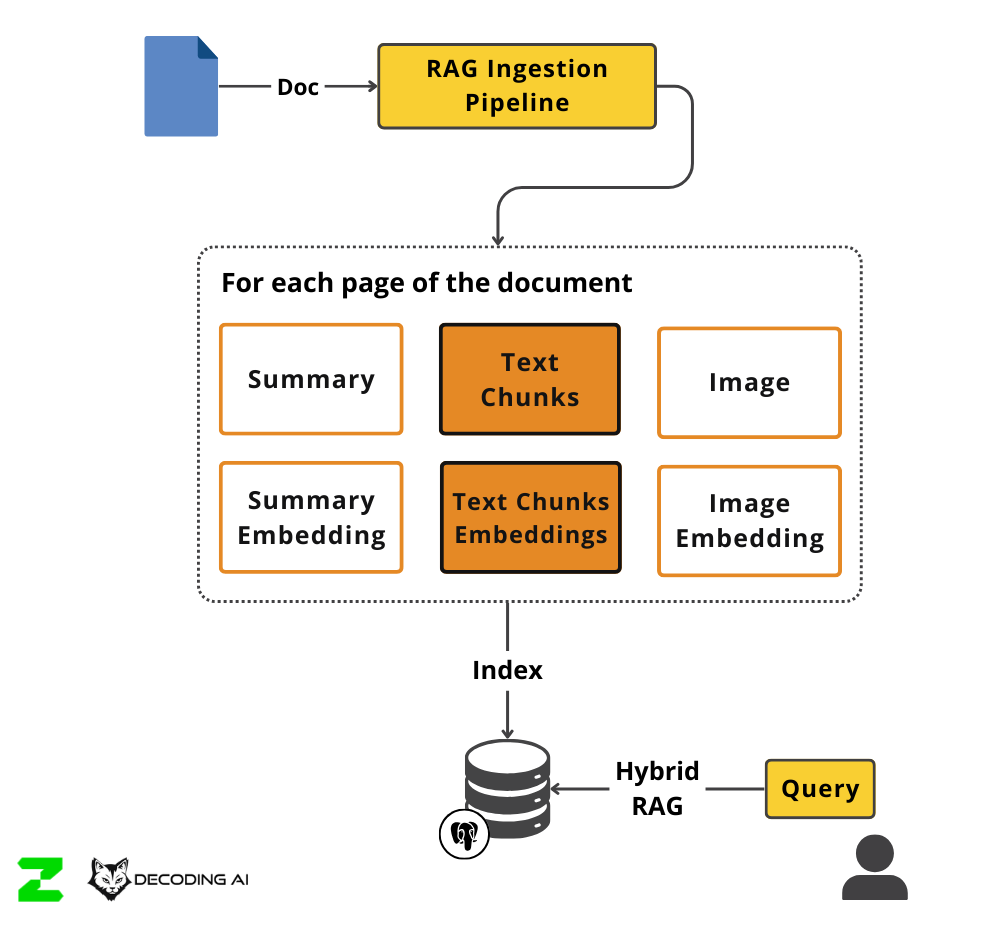
Sounds familiar? Then you should reconsider whether you really need this level of complexity.
Ultimately, even if the algorithm got complex, we managed to make it work. It functioned. But at what cost? Let’s see.
Next, We Added Agentic RAG
The next natural step was to answer more complex queries. A simple RAG system usually performs a one-shot retrieval: you ask a question, it finds relevant chunks, and it answers. But in the real world, and especially in wealth management, questions are rarely that simple.
Users would ask compound questions like, “What is the current state of my portfolio and what are my tasks for tomorrow?”
A standard retriever might find the portfolio update but miss the tasks, or vice versa. To solve this, we needed a loop where the agent could reflect on its own retrieval. It needed to ask, “Do I have enough information to answer this?” and if the answer was no, it needed to search again.
So, we implemented an Agentic RAG layer by implementing a ReAct agent from scratch that can dynamically query our hybrid index.
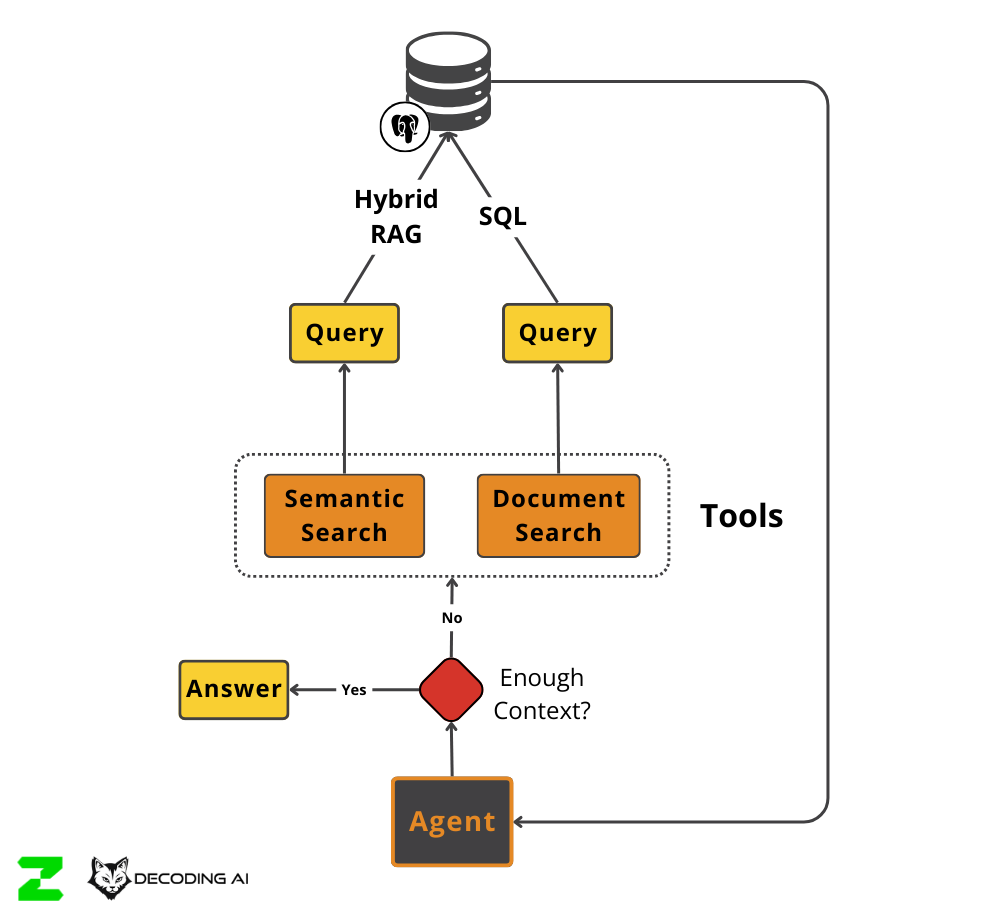
This allowed the system to perform multi-step reasoning. It could break down the query, retrieve data for the portfolio updates, realize it was missing task data, and perform a second retrieval. It sounded great in theory. In practice, it introduced a “zigzag” pattern of search. The agent would retrieve, reason, fail, retrieve again, and reason again. This drastically increased latency and cost. A simple query that should take 2 seconds was now taking 10 or 15 seconds because of the multiple round trips to the LLM and the vector database.
We don’t want to demonize agentic RAG. In many use cases, it is the go-to method. We still use it in production. Still, the real challenge is deciding when to use it. More on this later.
Continued With an MCP Registry
While we were wrestling with RAG, we also faced the challenge of integrating third-party services. ZTRON needed to talk to Gmail, Calendars, CRMs, and video meeting tools. At the time, in ~summer 2025, MCP was “the only way to do it”. Otherwise, you fall behind. Everyone said, “You must integrate using MCP, as it’s the USB-C of AI agents.”
So… We decided to use MCP. The idea was to have a unified interface where we could plug in custom MCP servers and existing ones, exposing them all to the agent through a single standard interface. We envisioned a future where we could just swap out tools through MCP servers without changing the agent’s core logic.
In other words, it was a tool registry, powered by MCP servers.
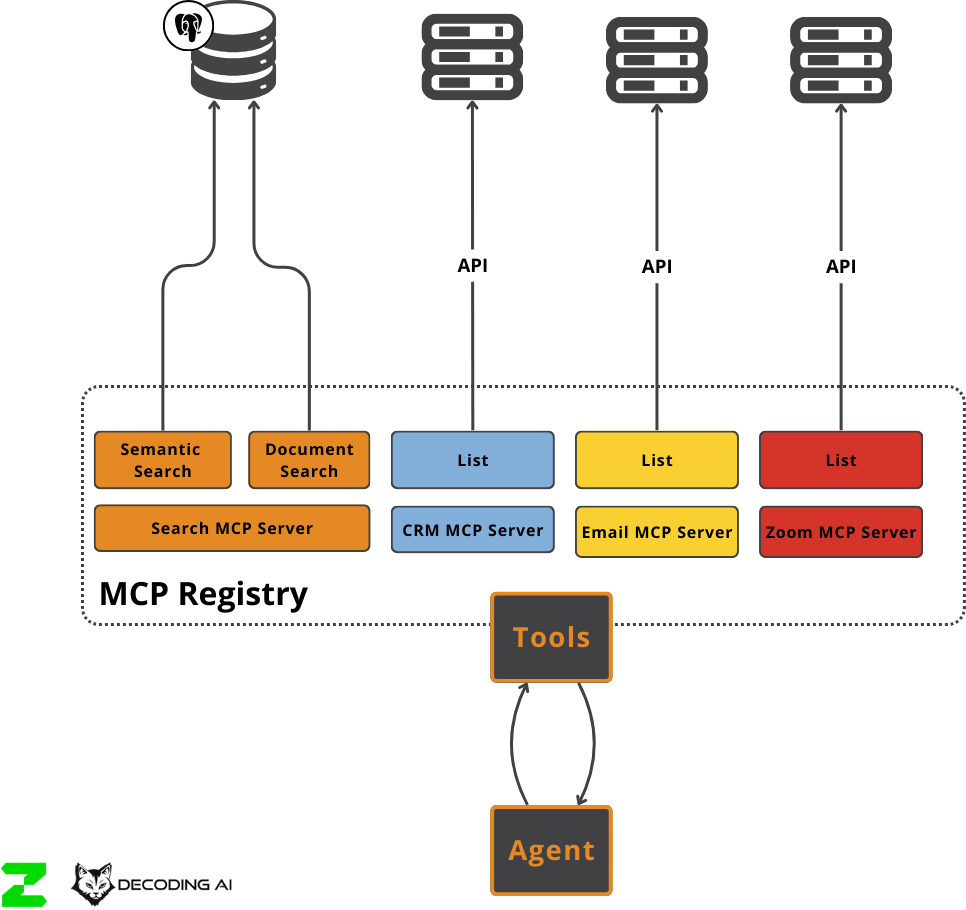
The problem was that most of the services we needed didn’t have MCP servers available. And the ones that did weren’t custom enough for our needs.
We ended up implementing the MCP servers ourselves and then implementing the specific API logic for Gmail, Calendar, and the others behind it. We were essentially wrapping standard APIs in an extra layer of abstraction just to say we used the protocol.
This means we used FastMCP, a Python framework for MCP, as a tool wrapper. A way to decorate functions, annotate them with tags, and load them into a tool registry based on particular filters.
The solution works, but in reality, we don’t leverage anything provided by the MCP protocol or by out-of-the-box MCP servers.
Was it worth it? Honestly, no. We could easily write that MCP registry functionality on our own, keeping the solution flexible and straightforward.
We overcomplicated our code for a “maybe.” Maybe in the future, we will use pre-existing servers. Maybe the ecosystem would catch up.
Again, we don’t demonize MCP. It’s a useful protocol. But we want to highlight that you most likely don’t need it. If you want to connect to an existing MCP server, that's great. If you want to ship your AI app as an MCP server, that's fantastic. If you want to design microservices, terrific. Unfortunately, that was not our use case.
Now, let’s move on to how we scaled our RAG ingestion pipeline with simplicity and flexibility in mind (at this point, we learnt our lesson, haha).
Next, We Scaled Our RAG Ingestion
Initially, we used a simple architecture where the ingestion pipeline ran directly on the API server. This worked fine when we were testing with one document. But as soon as we tried to ingest multiple documents at once, the server crashed.
We had competing resources. Even if all our models were used through APIs, the I/O workload of preparing data for RAG and moving it in multiple representations (chunks, summaries, images, embeddings, etc.) in memory was fighting for CPU and RAM. We needed to decouple the request from the ingestion process.
As we wanted to keep it simple and flexible, we turned to DBOS, an amazing open-source durable workflows tool. We wanted a simple solution that wouldn’t require spinning up a complex infrastructure like Kubernetes or managing separate message brokers like RabbitMQ or Redis. DBOS offered a durable queue backed directly by our existing Postgres database.
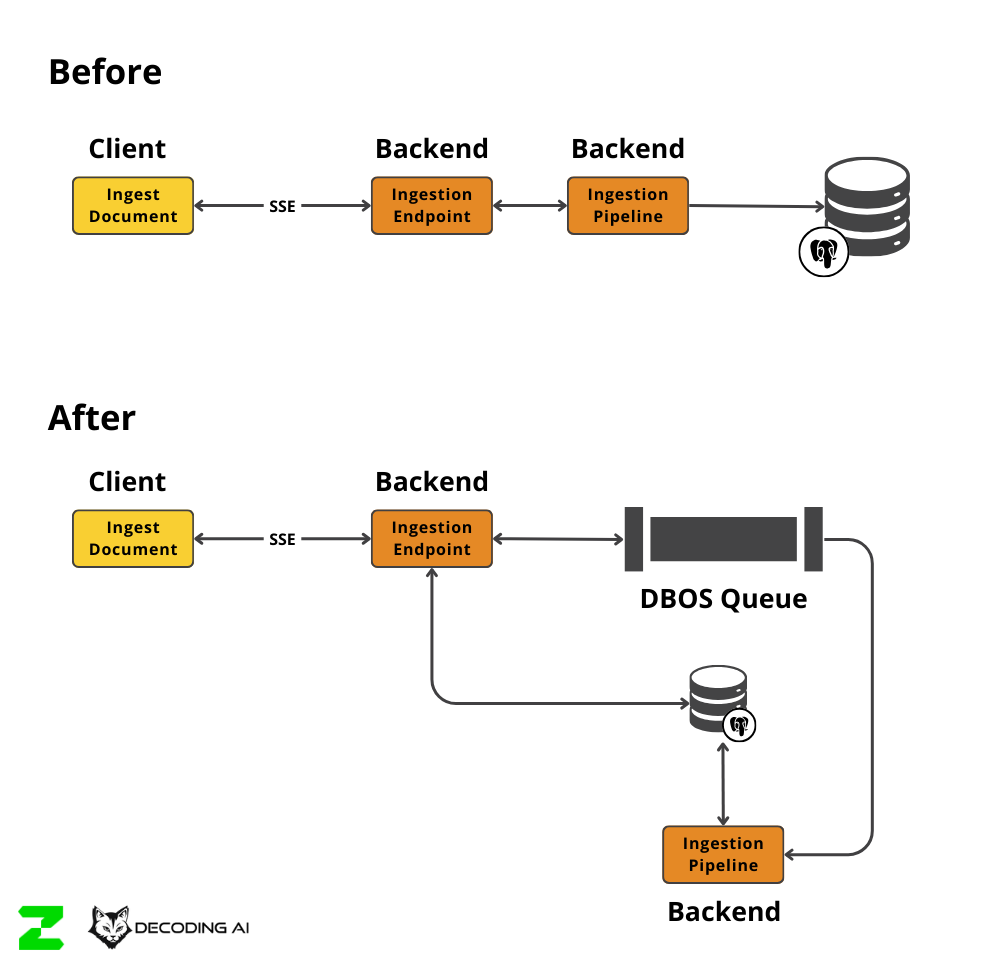
This allowed us to decouple the logic in about a week. We scaled from ingesting a couple of documents to hundreds without changing our core infrastructure. We were running on AWS Beanstalk with simple EC2 instances, and by using the DBOS queue, we created a lightweight distributed system. The data could come from anywhere, be stored in PostgreSQL, and be picked up by any worker on any EC2 instance.
But DBOS gave us more than just queues. It gave us durable workflows.
With durable workflows, we got out-of-the-box the ability to retry failed steps automatically. If an ingestion step failed, let’s say during the OCR process, we didn’t have to restart the whole pipeline. DBOS had checkpointed the state in Postgres, so we could resume exactly where we left off. This eliminated the randomness of debugging distributed systems.
However, we still had one big problem. We were running our FastAPI servers and the DBOS workers on the same EC2 instances.
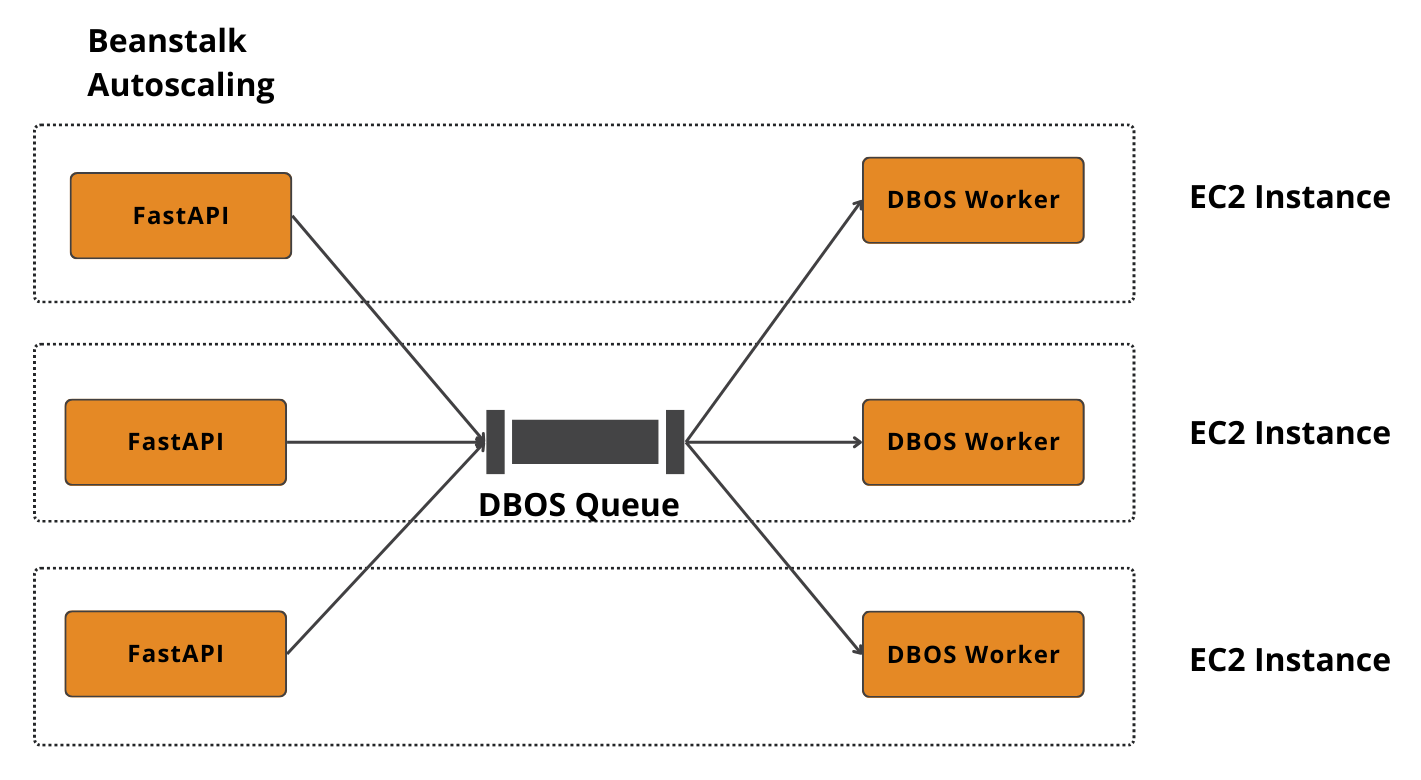
Python doesn’t really clean up its resources well. We started hitting Out-Of-Memory (OOM) errors because the heavy background workers were eating up the RAM needed by the API server. We needed a way to separate them without complicating our deployment.
How We Balanced Flexibility & Scalability to Scale Our AI Agent
To fully resolve resource contention, we decided to offload the heavy workflows to ephemeral workers. We split our infrastructure into two distinct autoscaling groups on AWS while keeping the communication simple through the DBOS queue in Postgres.
We configured the FastAPI Autoscaling Group to run on small, cost-effective ARM EC2 instances. These machines handle CRUD tasks running on the server extremely well. These machines can easily scale based on network traffic or CPU workload.
Separately, we set up a Workers Autoscaling Group running on larger ARM EC2s designed for heavy processing. These workers listen to the DBOS queue. We built a small controller on the server that monitors the queue size and scales the worker group accordingly. Critically, these workers can scale down to zero when there is no ingestion work to do.
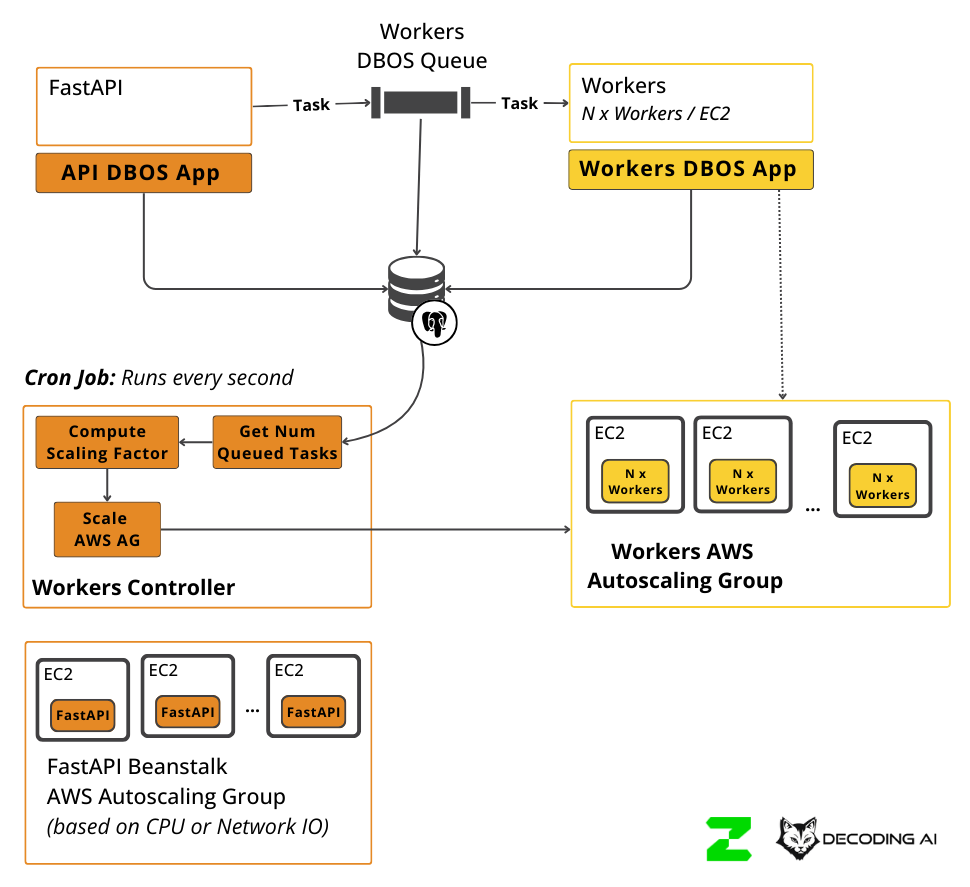
This architecture gave us the sweet spot. We used simple AWS elements (EC2, Postgres) but achieved a highly scalable system where the server is never blocked by the workers, and we only pay for the compute we actually use.
Ultimately, if you think about it, this is the go-to strategy for building backend applications that require some heavy processing on the side. The trickiest part is figuring out how to do it while keeping it simple, modular, and cheap without throwing K8s at every problem.
Probably, when we want to scale the solution further, we will go down the K8s path, but while you are still developing the core product, using overcomplicated infrastructure can really slow you down.
So... What’s the Core Problem Behind All This Engineering?
Ultimately, with a lot of engineering effort, we made everything work. And it works in production! Still... After many months of effort, we realized the core engineering issue behind all our struggles: RAG overcomplicates everything.
The zigzag retrieval patterns, the latency, the complex multi-index ingestion, it was all because we were trying to force RAG into a use case where it wasn’t strictly necessary. RAG is great for massive datasets, but it introduces instability. You are never quite sure if the retrieval will find the right chunk.
So, what did we do for many of our specialized agents? We shifted to CAG.
It’s not that RAG is dead, but for many vertical AI agents, you might not need it. We did the math. In our multi-tenant system, enforced by the UI/UX, the relevant data for a specific user session rarely exceeded 64k tokens.
Modern models, such as Gemini, can easily handle 64k tokens in their context window. By switching to CAG, we load all relevant user context into the prompt and use caching to improve efficiency. This eliminated the need for complex retrieval logic. We reduced multiple tool calls and LLM round-trips to just one. It made the system faster, deterministic, and cheaper to develop.
Just to be clear, we are still using RAG for open-ended questions where we don’t want to bloat the context for every “summarize my latest email” basic query. But as most features of our vertical AI agent are specific, such as generating reports, we can leverage CAG, drastically simplifying the solution and increasing the performance.
How We See the Future of Vertical AI Agents
This journey has shaped our view of where vertical AI agents are heading. We believe the future isn’t about bigger RAG pipelines, but about smarter context management.
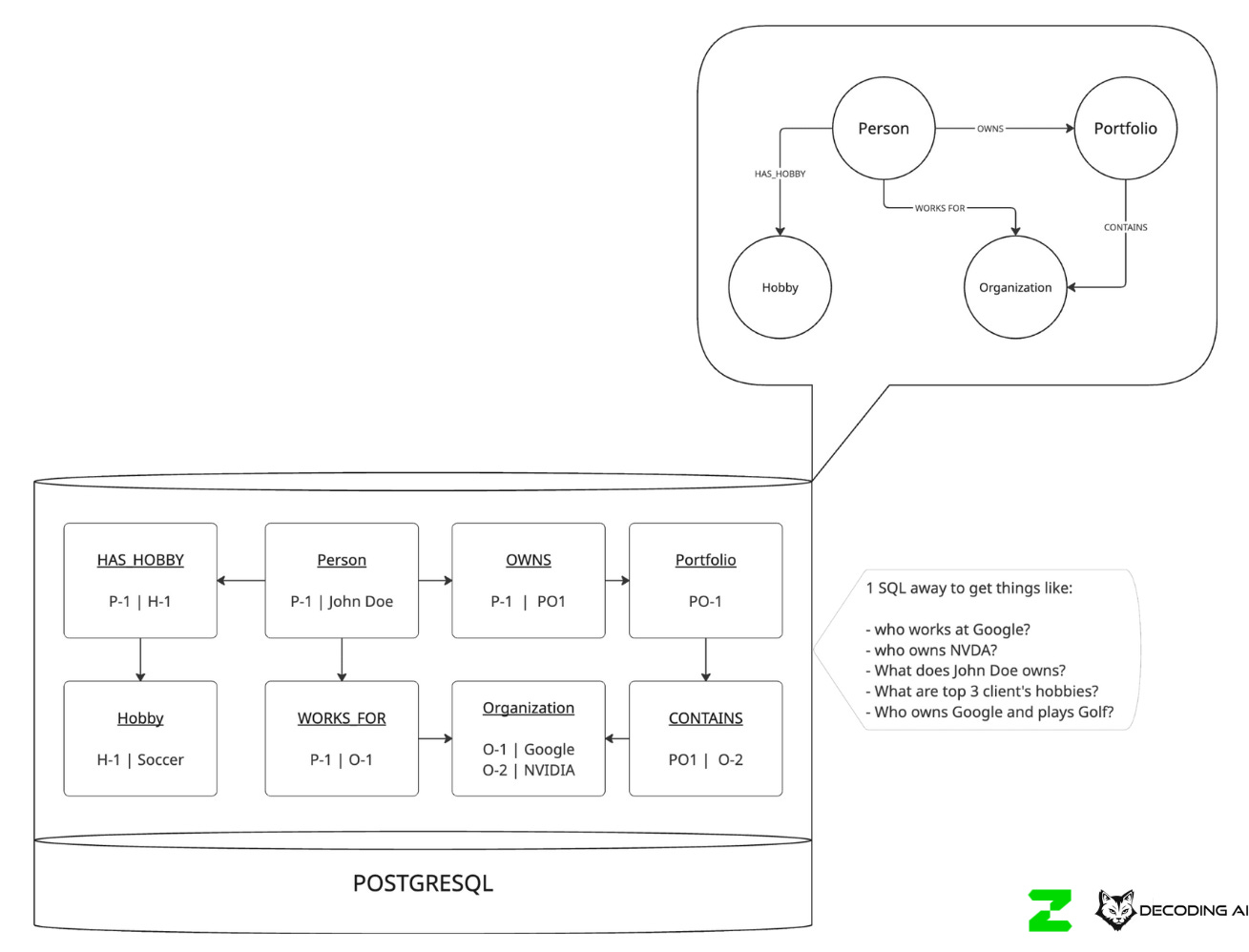
We see a move toward simple Knowledge Graphs built on top of Postgres or MongoDB. You don’t need a complex graph database like Neo4j for everything. Simple relational tables or documents can model the entities (Persons, Portfolios, Hobbies) and their relationships, allowing you to anchor your context effectively.
We also see a strong need for a hybrid approach using Small Language Models (SLMs). You can use closed-source, heavy reasoning models for complex planning, but offload the specialized tasks to tiny, fine-tuned models that can run cheaply or even on-device.
This combination of simplified graphs for context and SLMs for execution will drive the next wave of efficient AI agents.
Conclusion
Looking back at the development of ZTRON, it’s clear which decisions moved us forward and which held us back.
The correct decisions were rooted in simplicity and fundamentals. Sticking to a boring infrastructure (AWS, Postgres) allowed us to move fast. Writing our agentic layer from scratch gave us control. Integrating durable workflows through DBOS solved our distributed system headaches without adding ops overhead. And finally, stabilizing the app through CAG removed the fragility of retrieval.
The bad decisions almost always came from following the trend. We wasted time with AI packages that abstracted too much. We relied too heavily on Agentic RAG when simple context loading was enough. We built specialized agents we didn’t need, and we over-engineered an MCP registry for a problem we didn’t have.
If there is one lesson to take away, it’s this: The main source of bad engineering decisions is often just following the hype. Start simple, understand your data constraints, and only add complexity when you absolutely have to.
Thank you, Stephen, for hosting this event, and Jona for presenting it together with me! So excited about our next steps at ZTRON.
See you next Tuesday.
What’s your take on today’s topic? Do you agree, disagree, or is there something I missed?
If you enjoyed this article, the ultimate compliment is to share our work.
Go Deeper
Everything you learned in this article, from building evals datasets to evaluators, comes from the AI Evals & Observability module of our Agentic AI Engineering self-paced course.
Your path to agentic AI for production. Built in partnership with Towards AI.
Across 34 lessons (articles, videos, and a lot of code), you’ll design, build, evaluate, and deploy production-grade AI agents end to end. By the final lesson, you’ll have built a multi-agent system that orchestrates Nova (a deep research agent) and Brown (a full writing workflow), plus a capstone project where you apply everything on your own.
Three portfolio projects and a certificate to show off in interviews. Plus a Discord community where you have direct access to other industry experts and me.
Rated 4.9/5 ⭐️ by 190+ early students — “Every AI Engineer needs a course like this.”
Not ready to commit? We also prepared a free 6-day email course to reveal the 6 critical mistakes that silently destroy agentic systems. Get the free email course.
Thanks again to Opik for sponsoring the series and keeping it free!

If you want to monitor, evaluate and optimize your AI workflows and agents:
Images
If not otherwise stated, all images are created by the author.
“The main source of bad engineering decisions is often just following the hype.”
this rings very true. remember when everyone was tokenizing or putting every single product on the bloc chain a few years ago?
Note on public speaking. I've been on the sales and conference circuit for many years. The trick is not to over-prepare a specific presentation but instead to just know your content really well and then get out there and improv and jazz hands your way through it. This will come off as much more fluid and natural. Sounds it ended up working out this way with you being too tired to go through your prepared speech.
Staying loose but knowledgable (ie, bullshitting) allows you to remain flexible and adaptive to the audience and the context. You also may come up with new ideas mid discussion and can incorporate those seamlessly. The presentations (if using a formal one) should just be a rough outline with key points reminding you of what comes next.
Kind of like being an LLM. The improvisation is good if it is based on solid training. Trying to over-engineer a presentation is like trying to hard code everything an agent does. It may work awkwardly but it is also much less flexible and adaptive.
With this year's fast moving excitement over all these agent tools, I've had the impression that a lot of the hype is a bunch of solutions looking for a problem.
I went through a bunch of Coursera stuff on Agents but then never really used any of it because it seems agents are just trying to badly automate what I'm doing in conversation with ChatGPT anyway: "Do this, then with the result, do that," etc. I didn't go the extra step of plugging into any databases. I just drop whatever file or content I'm working on into the chat then take the result and fine tune it myself. That works pretty well for a single user and shaves off 40-60% of the time for a complex task.
It seems the great dream and promise of agents is automating away the need for a human middle man to take idiosyncratic data, do some stuff to it and return a result. But the agents don't know what you're trying to do to the same depth that you do and maybe never will.
I think the best use cases are as gatekeepers in a complex process using limited small models at different points. This allows for better control over your process. If you have to spend more time finding and correcting their errors, then it was probably more efficient just to keep doing it manually.
Of course, speaking in vague generalities isn't very useful in an engineering context as every particular use case has its own unique complexities that need to be addressed.