

Decoding ML #010: Should You Even Know How Diffusion Models Work?
Part 2: Learn How to Train and Control a Diffusion Model With Your Favorite Prompt

Hello there, I am Paul Iusztin, and within this newsletter, I will deliver your weekly piece of MLE & MLOps wisdom straight to your inbox 🔥
As promised, this week, I will finalize our stable diffusion models discussion with:
A Quick Guide on How to Train Diffusion Models
Controlling Stable Diffusion Models with a Given Context
→ Before diving into our topic, I want to let you know that I rebranded my newsletter to “Decoding ML”. I hope it brights up your interest in you 👀
→ Also, if you are curious to listen to a coffee chat about MLOps and ML engineering, I had the honor to talk at the Let’s Talk AI podcast about:
- building and engineering AI systems
- finding your niche in AI
- different ML job positions
- Airflow for automating ML
- deploying multiple versions and communicating effectively
- explaining technical complexity to customers
... and more
If that sounds useful to you, here is the link:
→ #32 - MLops, ML Engineer, AI systems and Deep Learning with Paul Iusztin
Ok… I am done talking about myself.
Let’s move back to the SD discussion I promised you 👇
#1. A Quick Guide on How to Train Diffusion Models
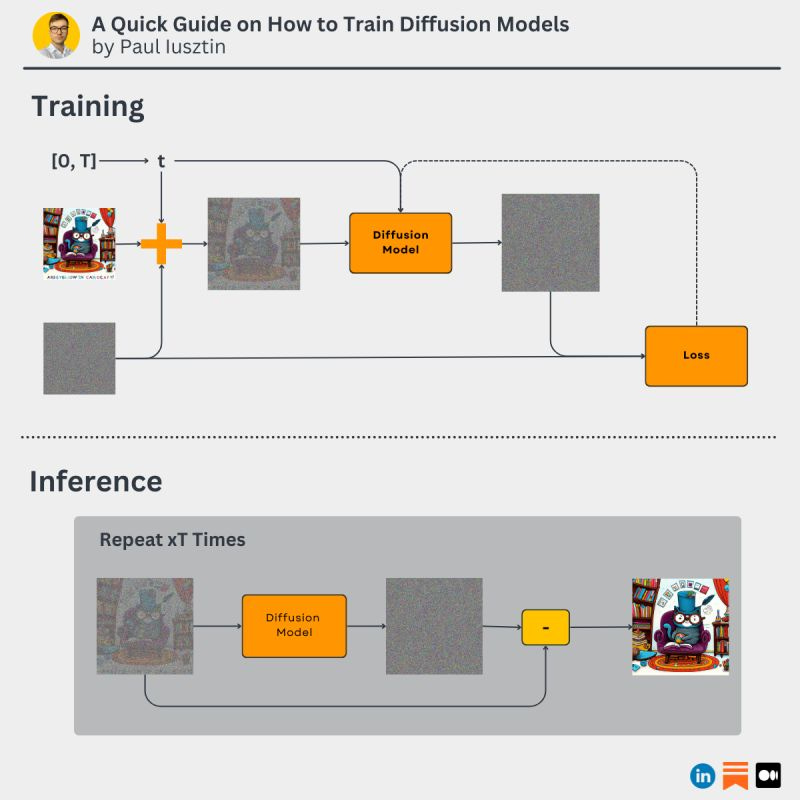
Reminder
A diffusion model takes a noisy image as input and outputs the noise level from the image.
At inference time, you take the input image and subtract the predicted noise from it.
Also, A diffusion model is parameterized by a timestamp T that reflects the diffusion process from T to 0.
Thus, for different timestamps, it predicts different levels of noise.
When the timestamp is near T, the model expects noisier images.
As it approaches 0, the expected noise level in the image is reduced.
Here is how the training works 👇
1. Sample a training image from the dataset.
2. Sample timestamp t from the interval [0, T], which determines the noise level.
3. Sample the noise.
4. Add the noise to the image based on the sample timestamp t.
5. Pass it through the diffusion model, which predicts the noise from the image.
6. Use an MSE loss to compare the predicted noise with the true one.
7. Use backpropagation to update the model.
8. Repeat!
Following this training strategy, the model learns to differentiate between the actual information from an image (e.g., the features of a cat) and the noise.
To summarize...
To train a diffusion model you:
- add noise to an image based on timestamp t
- the models learn to predict the noise from timestamp t
- you use MSE as a loss to compare the real noise with the predicted noise
#2. Controlling Stable Diffusion Models with a Given Context
Text-to-image models aren't magic.
This is everything you must know about how text prompts condition diffusion models,
...and not only!
.
The most common type of context is a piece of "text", but it can actually be anything, such as:
- categories
- images, doddles
- point clouds, etc.
But for this post, let's stick with the typical scenario of a "prompt."
.
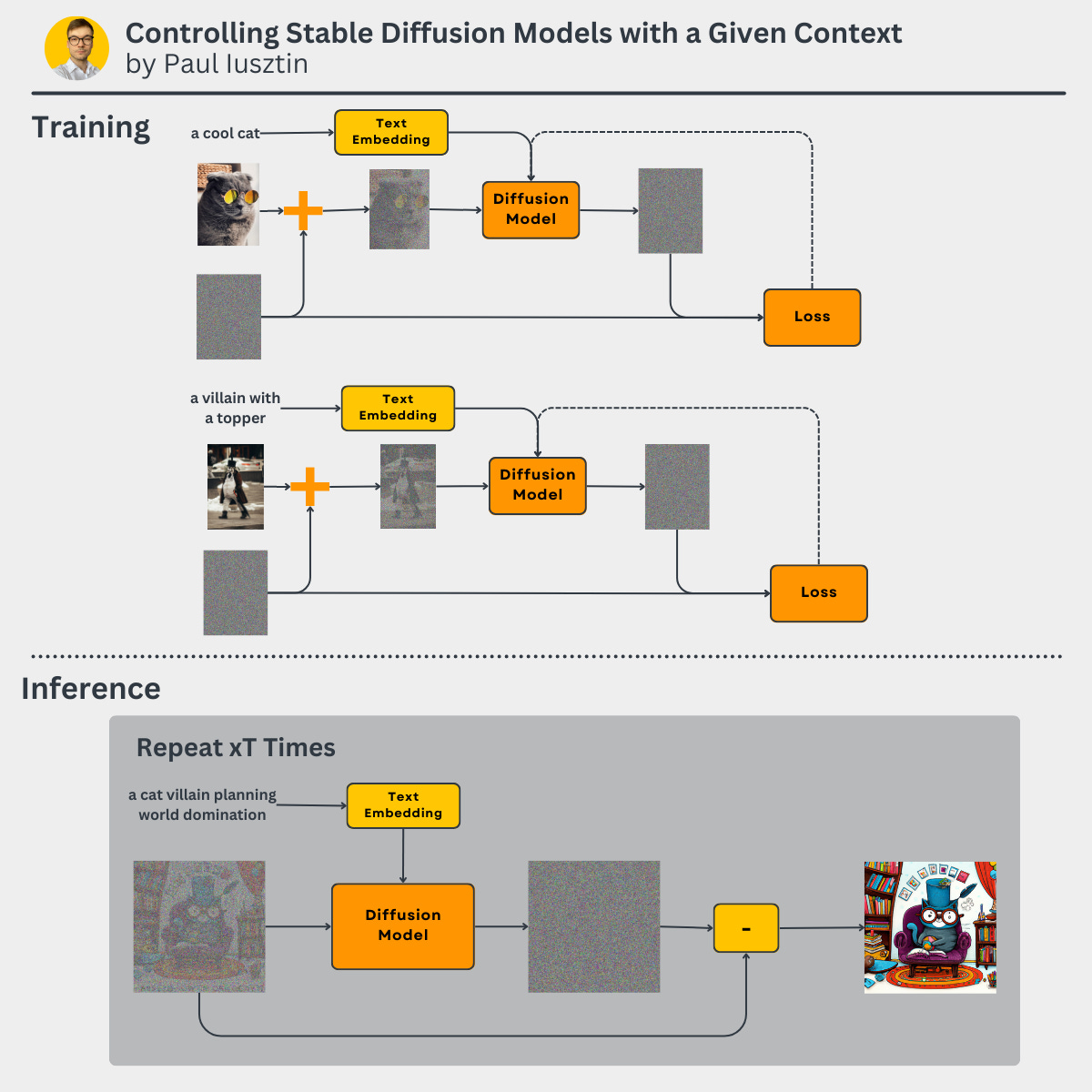
How do we condition the stable diffusion model with a prompt?
The first step is to add an encoder that embeds your context in the same space as the image. The CLIP encoder is a popular example that works with pictures and text.
The second step is to attach the context embedding to the diffusion model. A simple example is to add the embedding to the decoder feature maps during the upscaling phase.
.
-> During 𝘵𝘳𝘢𝘪𝘯𝘪𝘯𝘨, the context will guide the predicted noise of the diffusion model.
-> During 𝘪𝘯𝘧𝘦𝘳𝘦𝘯𝘤𝘦, we have 2 options:
- text + image: the output will be a combination of both
- text + random noise: the output will be solely based on the text
.
𝘉𝘶𝘵 𝘩𝘦𝘳𝘦 𝘪𝘴 𝘵𝘩𝘦 𝘤𝘢𝘵𝘤𝘩...
You need a high-quality and diverse dataset for the model to generate novel images.
Let me explain with a concrete example.
Let's say that our image + text dataset contains the following samples:
- a cool cat
- a villain with a topper
Diffusion models can interpolate between their training data points.
Thus we can safely ask it to generate "a cat villain planning world domination," and it will instantly create a cat with a topper.
But, if we want a different kind of "villain cat," the model will have difficulty generating it.
Also, if we ask for a dog instead of a cat, its job will become even harder.
❗The model's reality is stuck between cats and villains with a topper❗
That is why, for the ordinary mortal, who only trains diffusion models, the secret lies in the diversity and quality of his training dataset.
That is why data is more important than the model.
-> 𝘔𝘰𝘥𝘦𝘭𝘴 𝘢𝘳𝘦 𝘦𝘷𝘦𝘳𝘺𝘸𝘩𝘦𝘳𝘦 𝘣𝘶𝘵 𝘶𝘴𝘦𝘭𝘦𝘴𝘴 𝘸𝘪𝘵𝘩𝘰𝘶𝘵 𝘵𝘩𝘦 𝘱𝘳𝘰𝘱𝘦𝘳 𝘥𝘢𝘵𝘢.
That’s it 🔥
In a nutshell, this is how diffusion models work.
See you next Thursday at 9:00 am CET.
Have a fantastic weekend!
Paul
Whenever you’re ready, here is how I can help you:
The Full Stack 7-Steps MLOps Framework: a 7-lesson FREE course that will walk you step-by-step through how to design, implement, train, deploy, and monitor an ML batch system using MLOps good practices. It contains the source code + 2.5 hours of reading & video materials on Medium.
Machine Learning & MLOps Blog: here, I approach in-depth topics about designing and productionizing ML systems using MLOps.