

Decoding ML #011: My Ideal ML Engineering Tech Stack
Supercharge Your ML System: Use a Model Registry. My Ideal ML Engineering Tech Stack.

Hello there, I am Paul Iusztin, and within this newsletter, I will deliver your weekly piece of MLE & MLOps wisdom straight to your inbox 🔥
Hello ML builders 👋
This week we will cover the following topics:
Supercharge Your ML System: Use a Model Registry
My Ideal ML Engineering Tech Stack
+ [Bonus] Something extra for you.
But first, I want to let you know something.
—> If you want to learn ML & MLOps in a structured way but are too busy to take an entire course, then I wrote the perfect article for you.
A “14-minute read” preview of my "𝗧𝗵𝗲 𝗙𝘂𝗹𝗹 𝗦𝘁𝗮𝗰𝗸 𝟳-𝗦𝘁𝗲𝗽𝘀 𝗠𝗟𝗢𝗽𝘀 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸" course that explains how all the puzzle pieces (aka architecture components) work together.
It gives a high-level overview of how to design:
- a batch architecture
- feature, training, and inference pipelines
- orchestration
- data validation & monitoring
- web app using FastAPI & Streamlit
- deploy & CI/CD pipeline
- adapt the batch architecture to an online system
—> Check it out: The Full Stack 7-Steps MLOps Framework Preview

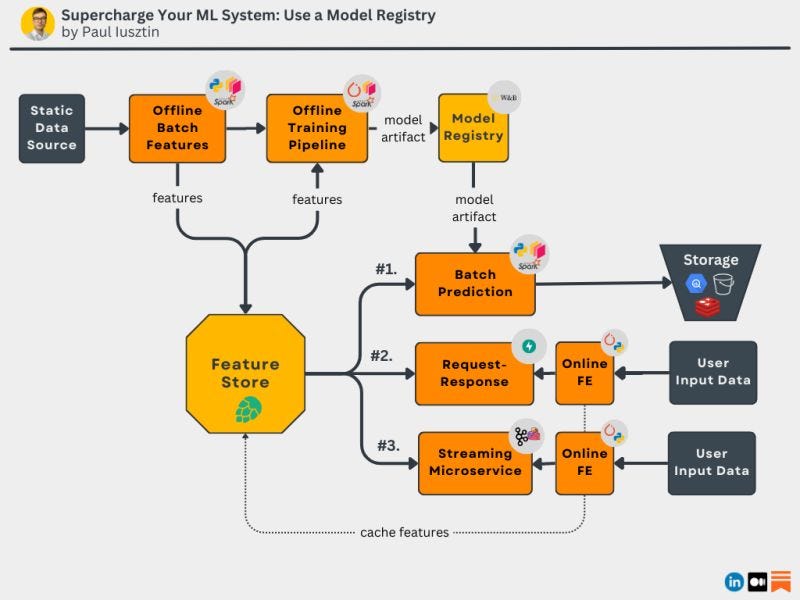
#1. Supercharge Your ML System: Use a Model Registry
A model registry is the holy grail of any production-ready ML system.
The model registry is the critical component that decouples your offline pipeline (experimental/research phase) from your production pipeline.
𝗖𝗼𝗺𝗽𝘂𝘁𝗲 𝗢𝗳𝗳𝗹𝗶𝗻𝗲 𝗙𝗲𝗮𝘁𝘂𝗿𝗲𝘀
Usually, when training your model, you use a static data source.
Using a feature engineering pipeline, you compute the necessary features used to train the model.
These features will be stored inside a features store.
After processing your data, your training pipeline creates the training & testing splits and starts training the model.
The output of your training pipeline is the trained weights, also known as the model artifact.
𝗛𝗲𝗿𝗲 𝗶𝘀 𝘄𝗵𝗲𝗿𝗲 𝘁𝗵𝗲 𝗺𝗼𝗱𝗲𝗹 𝗿𝗲𝗴𝗶𝘀𝘁𝗿𝘆 𝗸𝗶𝗰𝗸𝘀 𝗶𝗻 👇
This artifact will be pushed into the model registry under a new version that can easily be tracked.
Since this point, the new model artifact version can be pulled by any serving strategy:
#1. batch
#2. request-response
#3. streaming
Your inference pipeline doesn’t care how the model artifact was generated. It just has to know what model to use and how to transform the data into features.
Note that this strategy is independent of the type of model & hardware you use:
- classic model (Sklearn, XGboost),
- distributed system (Spark),
- deep learning model (PyTorch)
To summarize...
Using a model registry is a simple and effective method to:
-> detach your experimentation from your production environment,
regardless of what framework or hardware you use.
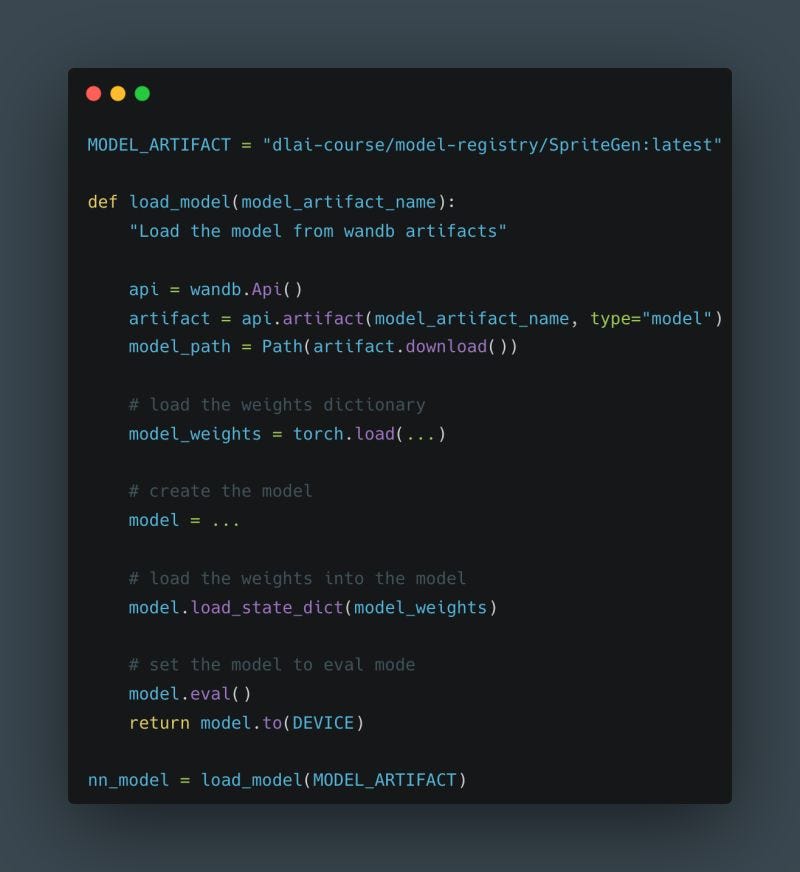
To learn more, check out my practical & detailed example of how to use a model registry in my article: A Guide to Building Effective Training Pipelines for Maximum Results
#2. My Ideal ML Engineering Tech Stack
Here it is 👇
- Python: your bread & butter
- Rust: code optimization
- Sklearn + XGBoost: classic ML
- PyTorch: deep learning
- FastAPI: REST APIs
- Streamlit: UI
- Terraform: infrastructure
- Kafka: streaming
- Docker: containerize
- Kubernetes: horizontal scaling
- GitHub Actions: CI/CD
- Airflow: orchestrating
- AWS: cloud
- Hopsworks: feature store
- W&B: experiment tracking, model & artifact registry
- DVC: data versioning
- Arize: Observability
If that sounds like a lot... it is...
Sometimes finding your way out of this tool's labyrinth is a struggle.
But hey, at the end of the day, I have a lot of fun working with them.

Note that in some scenarios, the tool you use depends a lot on the context. For example, you might use ZenML instead of Airflow for orchestration.
That is perfectly fine. The most important is to know what you know (e.g., orchestration). Afterward, you can quickly do your own research and pick the best tool for the job.
[Bonus] New 1-hour Free MLOps Course by DeepLearning.ai
This one-hour course is perfect for you if you want a quick intro to MLOps around generative AI.
DeepLearning.AI just released a ~1-hour MLOps course that will show you how to use W&B as your MLOps tool for:
- diffusion models
- LLMs
I recently skimmed through it, and it is worth it.
🔗 Evaluating and Debugging Generative AI
That’s it for today 👾
See you next Thursday at 9:00 am CET.
Have a fantastic weekend!
Paul
Whenever you’re ready, here is how I can help you:
The Full Stack 7-Steps MLOps Framework: a 7-lesson FREE course that will walk you step-by-step through how to design, implement, train, deploy, and monitor an ML batch system using MLOps good practices. It contains the source code + 2.5 hours of reading & video materials on Medium.
Machine Learning & MLOps Blog: here, I approach in-depth topics about designing and productionizing ML systems using MLOps.