

Decoding ML #013: Build a CI/CD Pipeline Using Github Actions & Docker in Just a Few Lines of Code.
Build a CI/CD pipeline using GitHub Actions and Docker. 3 Simple Tricks to Evaluate Your Models with Ease.

Hello there, I am Paul Iusztin 👋🏼
Within this newsletter, I will help you decode complex topics about ML & MLOps one week at a time 🔥
This week we will cover:
How you can build a CI/CD pipeline using GitHub Actions and Docker in just a few lines of code.
3 Simple tricks to evaluate your models with ease.
Terraform & Kubernetes crash courses.
But first, a little bit of shameless promotion that might be beneficial for both of us 👋
Looking for a hub where to 𝗹𝗲𝗮𝗿𝗻 𝗮𝗯𝗼𝘂𝘁 𝗠𝗟 𝗲𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 𝗮𝗻𝗱 𝗠𝗟𝗢𝗽𝘀 𝗳𝗿𝗼𝗺 𝗿𝗲𝗮𝗹-𝘄𝗼𝗿𝗹𝗱 𝗲𝘅𝗽𝗲𝗿𝗶𝗲𝗻𝗰𝗲?
I just launched my personal site that serves as a hub for all my MLE & MLOps content and work.
There, I will constantly aggregate my:
- courses
- articles
- talks
...and more
→ Sweet part: Everything will revolve around MLE & MLOps
It is still a work in progress...
But please check it out and let me know what you think.
Your opinion is deeply appreciated 🙏
↳ 🔗 Personal site | MLE & MLOps Hub
#1. How you can build a CI/CD pipeline using GitHub Actions and Docker in just a few lines of code
This is how you can build a CI/CD pipeline using GitHub Actions and Docker in just a few lines of code.
As an ML/MLOps engineer, you should master serving models by building CI/CD pipelines.
The good news is that GitHub Actions + Docker simplifies building a CI/CD pipeline.
.
𝗪𝗵𝘆?
- you can easily trigger jobs when merging various branches
- the CI/CD jobs run on GitHub's VMs (free)
- easy to implement: copy & paste pre-made templates + adding credentials
.
𝗙𝗼𝗿 𝗲𝘅𝗮𝗺𝗽𝗹𝗲, 𝘁𝗵𝗶𝘀 𝗶𝘀 𝗵𝗼𝘄 𝘆𝗼𝘂 𝗰𝗮𝗻 𝗯𝘂𝗶𝗹𝗱 𝗮 𝗖𝗜 𝗽𝗶𝗽𝗲𝗹𝗶𝗻𝗲 𝗶𝗻 𝟯 𝘀𝗶𝗺𝗽𝗹𝗲 𝘀𝘁𝗲𝗽𝘀:
#1. The CI pipeline is triggered when you merge your new feature branch into the main branch.
#2. You login into the Docker Registry (or any other compatible registry such as ECR).
#3. You build the image. Run your tests (if you have any), and if the tests pass, you push the image into the registry.
.
𝗧𝗼 𝗶𝗺𝗽𝗹𝗲𝗺𝗲𝗻𝘁 𝘁𝗵𝗲𝗺 𝘂𝘀𝗶𝗻𝗴 𝗚𝗶𝘁𝗛𝘂𝗯 𝗔𝗰𝘁𝗶𝗼𝗻𝘀, 𝘆𝗼𝘂 𝗵𝗮𝘃𝗲 𝘁𝗼:
- Dockerize your code
- search "CI Template GitHub Actions" on Google
- copy-paste the template
- add your Docker Registry credentials
...and bam... you are done.
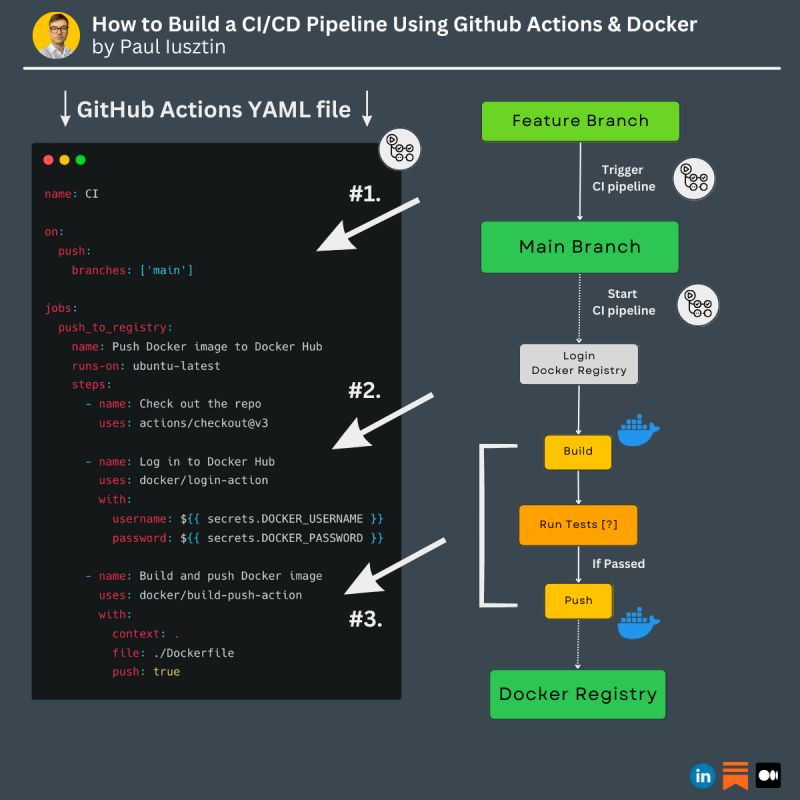
Easy right? The steps are similar when building your CD pipeline (deploying the new image to production).
If you want to see how I used GitHub Actions to build & deploy an ML system to GCP, check out this article: 🔗 Seamless CI/CD Pipelines with GitHub Actions on GCP
#2. 3 Simple tricks to evaluate your models with ease
When comparing 100+ training experiments, I often got overwhelmed by which one to pick.
Until I started using these 3 simple tricks 👇
𝟭. 𝗕𝗮𝘀𝗲 𝗠𝗼𝗱𝗲𝗹
You need a reference point to compare your model results with.
Otherwise, the computed metrics are hard to interpret.
-> For example, you are training a time series forecaster.
The base model always predicts the last value. If your "smart" model can't outperform that, you are better of without it.
𝟮. 𝗦𝗹𝗶𝗰𝗶𝗻𝗴
Aggregated metrics are often misleading (the mean over all the testing samples).
Slicing your testing dataset by features of interest such as gender, age, demographics, etc., can bring to the surface issues such as:
- bias
- weakness points
- relationships between inputs & outputs (aka explainability), etc.
-> For example, your model can have extraordinary results in the [18, 30] age range but terrible ones in [30+, inf].
The aggregated metrics look great because most data samples are within the [18, 30] range. But in reality, your model fails the minority groups.
Thus, even though the aggregated metrics look great, you may deploy a broken model.
Tools: Snorkel
𝟯. 𝗘𝘅𝗽𝗲𝗿𝗶𝗺𝗲𝗻𝘁 𝗧𝗿𝗮𝗰𝗸𝗲𝗿
You just run 100+ experiments using different models and hyperparameters.
You already have your base model and slicing techniques set in place.
How can you easily compare these experiments?
You can quickly aggregate the results using an experiment tracker in a single graph(s).
Thus, you have the big picture to pick the best experiment and its metadata easily.
Tools: Comet ML, W&B, MLFlow, Neptune

To conclude...
To quickly compare many experiments, you need:
- a base model
- to slice your testing split
- an experiment tracker
If you are curious about implementing these strategies, check out my article: 🔗 A Guide to Building Effective Training Pipelines for Maximum Results
Do you recommend other tricks to improve your evaluation process?
#3. Terraform & Kubernetes crash courses
Courses for 2 tools that any MLOps engineer should master.
I finished them recently & I had to share them with you.
𝟭. 𝗧𝗲𝗿𝗿𝗮𝗳𝗼𝗿𝗺
The most popular tool for Infrastructure as Code.
It lets you spin up & down entire complex cloud infrastructures with a single command.
↳ 🔗 Introduction to Terraform course
𝟮. 𝗞𝘂𝗯𝗲𝗿𝗻𝗲𝘁𝗲𝘀
Probably all of you know about Kubernetes.
But it is the go-to tool for scaling your application horizontally.
↳ 🔗 Introduction to K8s course
.
Both courses provide a theoretical part & hands-on examples that you can replicate along the course.
That’s it for today 👾
See you next Thursday at 9:00 am CET.
Have a fantastic weekend!
Paul
Whenever you’re ready, here is how I can help you:
The Full Stack 7-Steps MLOps Framework: a 7-lesson FREE course that will walk you step-by-step through how to design, implement, train, deploy, and monitor an ML batch system using MLOps good practices. It contains the source code + 2.5 hours of reading & video materials on Medium.
Machine Learning & MLOps Blog: here, I approach in-depth topics about designing and productionizing ML systems using MLOps.
Machine Learning & MLOps Hub: a place where I will constantly aggregate all my work (courses, articles, webinars, podcasts, etc.),