

DML: How to add real-time monitoring & metrics to your ML System
How to easily add retry policies to your Python code. How to add real-time monitoring & metrics to your ML System.

Hello there, I am Paul Iusztin 👋🏼
Within this newsletter, I will help you decode complex topics about ML & MLOps one week at a time 🔥
This week’s ML & MLOps topics:
How to add real-time monitoring & metrics to your ML System
How to easily add retry policies to your Python code
Storytime: How am I writing code in 2023? 𝗜 𝗱𝗼𝗻'𝘁.
But first, I have some big news to share with you 🎉
—> Want to learn how to 𝗳𝗶𝗻𝗲-𝘁𝘂𝗻𝗲 𝗮𝗻 𝗟𝗟𝗠, build a 𝘀𝘁𝗿𝗲𝗮𝗺𝗶𝗻𝗴 𝗽𝗶𝗽𝗲𝗹𝗶𝗻𝗲, use a 𝘃𝗲𝗰𝘁𝗼𝗿 𝗗𝗕, build a 𝗳𝗶𝗻𝗮𝗻𝗰𝗶𝗮𝗹 𝗯𝗼𝘁 and 𝗱𝗲𝗽𝗹𝗼𝘆 𝗲𝘃𝗲𝗿𝘆𝘁𝗵𝗶𝗻𝗴 using a serverless solution?
Then you will enjoy looking at this new free course that me and Pau Labarta Bajo (from the RWML newsletter) are cooking.
↳ The course will teach you how to build an end-to-end LLM solution.
It is structured into 4 modules ↓
𝗠𝗼𝗱𝘂𝗹𝗲 𝟭: Learn how to generate a financial Q&A dataset in a semi-automated way using the OpenAI API.
𝗠𝗼𝗱𝘂𝗹𝗲 𝟮: Fine-tune the LLM (e.g., Falcon, Llama2, etc.) using HuggingFace & Peft. Also, we will show you how to integrate an experiment tracker, model registry, and monitor the prompts using Comet.
𝗠𝗼𝗱𝘂𝗹𝗲 𝟯: Build a streaming pipeline using Bytewax that listens to financial news through a web socket, cleans it, embeds it, and loads it to a vector database using Qdrant.
𝗠𝗼𝗱𝘂𝗹𝗲 𝟰: Wrap the fine-tuned model and vector DB into a financial bot using LangChain and deploy it under a RESTful API.
❗️ But all of this is useless if it isn't deployed.
→ We will use Beam to deploy everything quickly - Beam is a serverless solution that lets you focus on your problem and quickly serve all your ML components. Say bye-bye to access policies and network configuration.
𝗡𝗼𝘁𝗲: This is still a work in progress, but the first 3 modules are almost done.

Curious?
Then, check out the repository and give it a ⭐ ↓
#1. How to add real-time monitoring & metrics to your ML System
Your model is exposed to performance degradation after it is deployed to production.
That is why you need to monitor it constantly.
The most common way to monitor an ML model is to compute its metrics.
But for that, you need the ground truth.
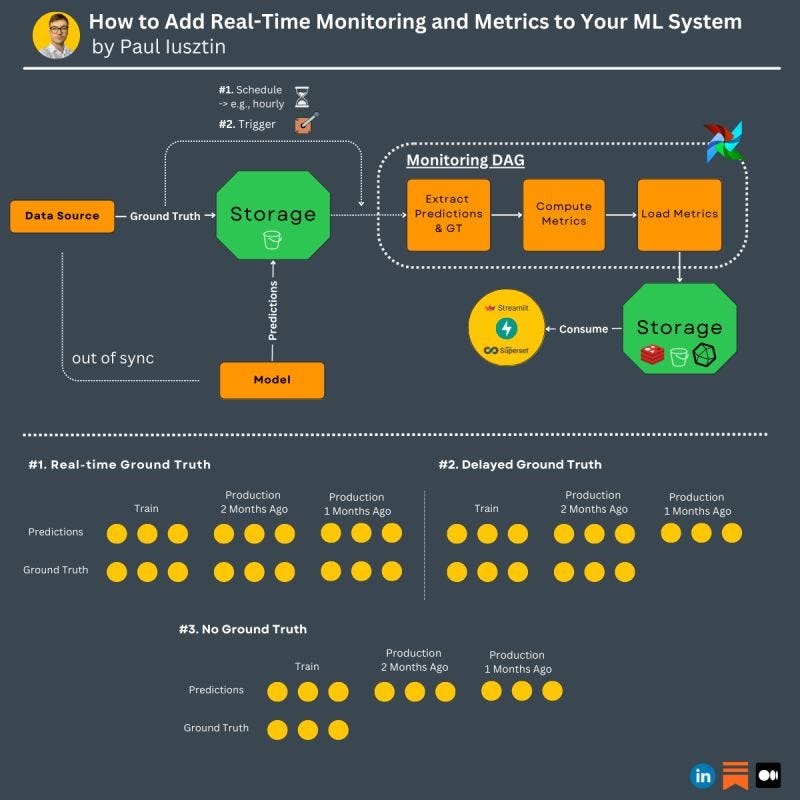
𝗜𝗻 𝗽𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻, 𝘆𝗼𝘂 𝗰𝗮𝗻 𝗮𝘂𝘁𝗼𝗺𝗮𝘁𝗶𝗰𝗮𝗹𝗹𝘆 𝗮𝗰𝗰𝗲𝘀𝘀 𝘁𝗵𝗲 𝗴𝗿𝗼𝘂𝗻𝗱 𝘁𝗿𝘂𝘁𝗵 𝗶𝗻 𝟯 𝗺𝗮𝗶𝗻 𝘀𝗰𝗲𝗻𝗮𝗿𝗶𝗼𝘀:
1. near real-time: you can access it quite quickly
2. delayed: you can access it after a considerable amount of time (e.g., one month)
3. never: you have to label the data manually
.
𝗙𝗼𝗿 𝘂𝘀𝗲 𝗰𝗮𝘀𝗲𝘀 𝟮. 𝗮𝗻𝗱 𝟯. 𝘆𝗼𝘂 𝗰𝗮𝗻 𝗾𝘂𝗶𝗰𝗸𝗹𝘆 𝗰𝗼𝗺𝗽𝘂𝘁𝗲 𝘆𝗼𝘂𝗿 𝗺𝗼𝗻𝗶𝘁𝗼𝗿𝗶𝗻𝗴 𝗽𝗶𝗽𝗲𝗹𝗶𝗻𝗲 𝗶𝗻 𝘁𝗵𝗲 𝗳𝗼𝗹𝗹𝗼𝘄𝗶𝗻𝗴 𝘄𝗮𝘆:
- store the model predictions and GT as soon as they are available (these 2 will be out of sync -> you can't compute the metrics right away)
- build a DAG (e.g., using Airflow) that extracts the predictions & GT computes the metrics in batch mode and loads them into another storage (e.g., GCS)
- use an orchestration tool to run the DAG in the following scenarios:
1. scheduled: if the GT is available in near real-time (e.g., hourly), then it makes sense to run your monitoring pipeline based on the known frequency
2. triggered: if the GT is delayed and you don't know when it may come up, then you can implement a webhook to trigger your monitoring pipeline
- attach a consumer to your storage to use and display the metrics (e.g., trigger alarms and display them in a dashboard)
If you want to see how to implement a near real-time monitoring pipeline using Airflow and GCS, check out my article ↓
↳ 🔗 Ensuring Trustworthy ML Systems With Data Validation and Real-Time Monitoring
#2. How to easily add retry policies to your Python code
One strategy that makes the 𝗱𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝗰𝗲 𝗯𝗲𝘁𝘄𝗲𝗲𝗻 𝗴𝗼𝗼𝗱 𝗰𝗼𝗱𝗲 𝗮𝗻𝗱 𝗴𝗿𝗲𝗮𝘁 𝗰𝗼𝗱𝗲 is adding 𝗿𝗲𝘁𝗿𝘆 𝗽𝗼𝗹𝗶𝗰𝗶𝗲𝘀.
To manually implement them can get tedious and complicated.
Retry policies are a must when you:
- make calls to an external API
- read from a queue, etc.
.
𝗨𝘀𝗶𝗻𝗴 𝘁𝗵𝗲 𝗧𝗲𝗻𝗮𝗰𝗶𝘁𝘆 𝗣𝘆𝘁𝗵𝗼𝗻 𝗽𝗮𝗰𝗸𝗮𝗴𝗲...
𝘠𝘰𝘶 𝘤𝘢𝘯 𝘲𝘶𝘪𝘤𝘬𝘭𝘺 𝘥𝘦𝘤𝘰𝘳𝘢𝘵𝘦 𝘺𝘰𝘶𝘳 𝘧𝘶𝘯𝘤𝘵𝘪𝘰𝘯𝘴 𝘢𝘯𝘥 𝘢𝘥𝘥 𝘤𝘶𝘴𝘵𝘰𝘮𝘪𝘻𝘢𝘣𝘭𝘦 𝘳𝘦𝘵𝘳𝘺 𝘱𝘰𝘭𝘪𝘤𝘪𝘦𝘴, 𝘴𝘶𝘤𝘩 𝘢𝘴:
1. Add fixed and random wait times between multiple retries.
2. Add a maximum number of attempts or computation time.
3. Retry only when specific errors are thrown (or not thrown).
... as you can see, you easily compose these policies between them.
The cherry on top is that you can access the statistics of the retries of a specific function:
"
print(raise_my_exception.retry.statistics)
"

Storytime: How am I writing code in 2023? I don’t
As an engineer, you are paid to think and solve problems. How you do that, it doesn't matter. Let me explain ↓
.
The truth is that I am lazy.
That is why I am a good engineer.
With the rise of LLMs, my laziness hit all times highs.
.
𝗧𝗵𝘂𝘀, 𝘁𝗵𝗶𝘀 𝗶𝘀 𝗵𝗼𝘄 𝗜 𝘄𝗿𝗶𝘁𝗲 𝗺𝘆 𝗰𝗼𝗱𝗲 𝘁𝗵𝗲𝘀𝗲 𝗱𝗮𝘆𝘀 ↓
- 50% Copilot (tab is the new CTRL-C + CTRL-V)
- 30% ChatGPT/Bard
- 10% Stackoverflow (call me insane, but I still use StackOverflow from time to time)
- 10% Writing my own code
The thing is that I am more productive than ever.
... and that 10% of "writing my own code" is the final step that connects all the dots and brings real value to the table.
.
𝗜𝗻 𝗿𝗲𝗮𝗹𝗶𝘁𝘆, 𝗮𝘀 𝗮𝗻 𝗲𝗻𝗴𝗶𝗻𝗲𝗲𝗿, 𝘆𝗼𝘂 𝗺𝗼𝘀𝘁𝗹𝘆 𝗵𝗮𝘃𝗲 𝘁𝗼:
- ask the right questions
- understand & improve the architecture of the system
- debug code
- understand business requirements
- communicate with other teams
...not to write code.

Writing code as we know it most probably will disappear with the rise of AI (it kind of already did).
.
What do you think? How do you write code these days?
That’s it for today 👾
See you next Thursday at 9:00 am CET.
Have a fantastic weekend!
Paul
Whenever you’re ready, here is how I can help you:
The Full Stack 7-Steps MLOps Framework: a 7-lesson FREE course that will walk you step-by-step through how to design, implement, train, deploy, and monitor an ML batch system using MLOps good practices. It contains the source code + 2.5 hours of reading & video materials on Medium.
Machine Learning & MLOps Blog: here, I approach in-depth topics about designing and productionizing ML systems using MLOps.
Machine Learning & MLOps Hub: a place where I will constantly aggregate all my work (courses, articles, webinars, podcasts, etc.).