

ML #003: Level up your ML pipeline game using MLOps
Do hyperparameter tuning like an MLOps pro. 3 ways to properly design feature transformations.

This week we will take a look at how to design and scale the following to your ML pipeline properly:
Do hyperparameter tuning like an MLOps pro;
3 ways to do feature transformations.
#1. Do hyperparameter tuning like an MLOps pro
What was my best model called? Was it "best_final.model" or "final_final_best.model"?
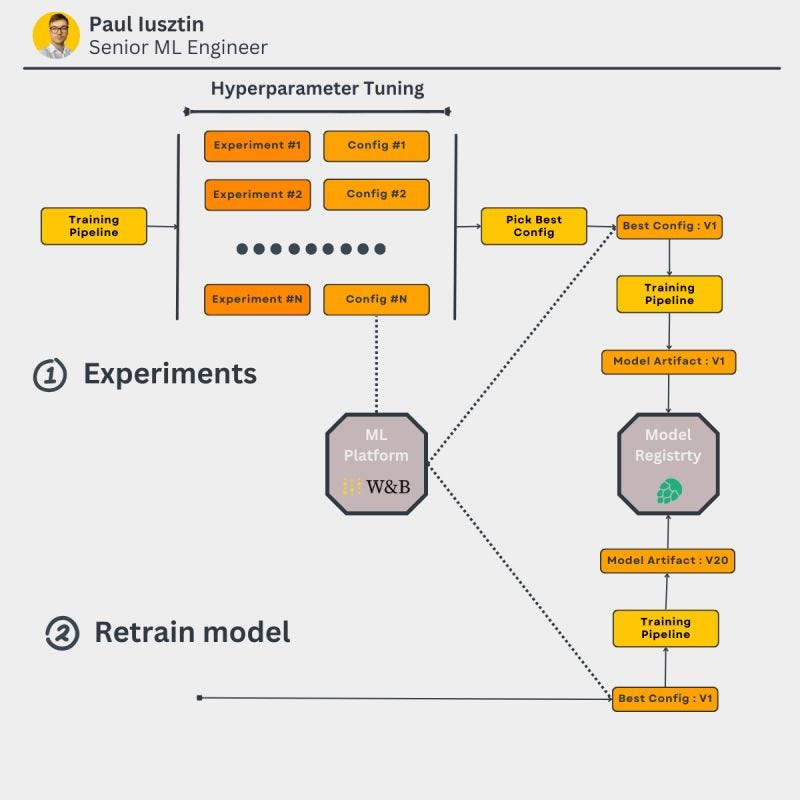
Let me explain how you should design your training pipeline using an ML platform, never to forget what was your best configuration file and model again.
One key component when designing a training pipeline is your hyperparameter tuning/experiment step.
It is critical to have the freedom to run multiple experiments, compare them, and decide on the best set of hyperparameters.
By using an ML platform:
- storing the configuration as artifacts and attaching them to your experiment is straightforward.
- you can quickly compare multiple experiments and find the best configuration
Finally, at the end of your experimentation process, you can store the best configuration in a different artifact that you can later version and access to retraining future models: "best_config:v0".
Now, it is evident what is the latest and best configuration to train future models.
Thus, when retraining your model from production, you must download the artifact from the ML platform and retrain your model.
No further experimentation/hyperparameter tuning is needed.
For example, you are still using "best_config:v0" while generating "model:v1", "model:v2", etc.
By doing so, it is easy to automate your training pipeline.
But, because the environment changes, your "best configuration" might not work anymore.
You will see this by testing your model on your new test split and running A/B tests.
In this case, you can automatically retrigger the hyperparameter tuning process to find the best configuration.
Now you generated "best_config:v1", which you will further use to retrain your future models.
But the key idea is that you want to run the tunning process as rarely as possible, as it consumes many resources: time & money.
So remember...
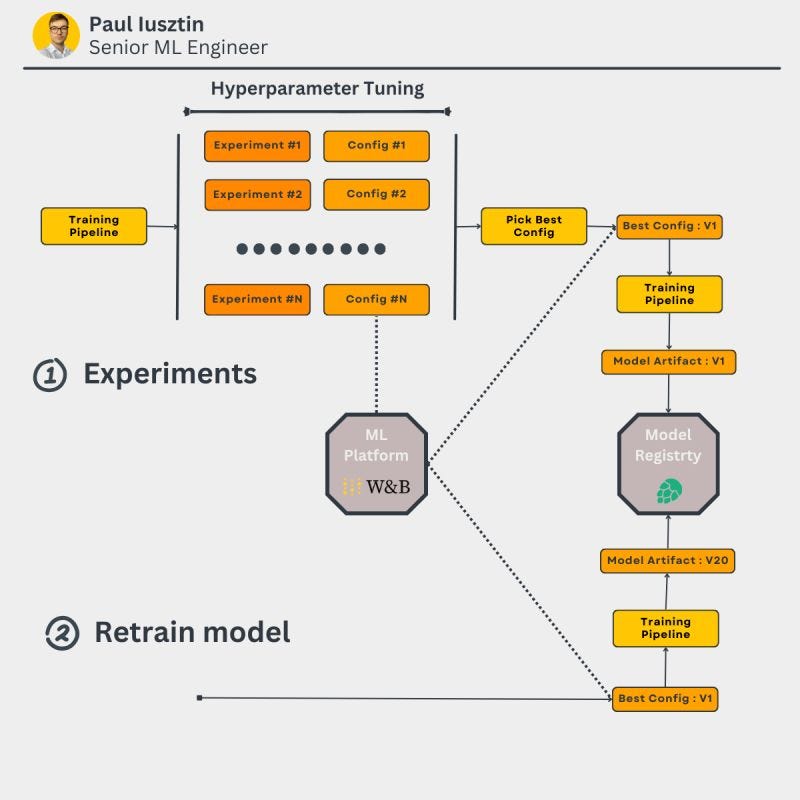
Using an ML platform, you can quickly run hyperparameter tuning experiments, compare them, and pick the best investigation.
After, you can upload the best configuration as a versioned artifact "best_config:v0" that you can later use to retrain your models: "model:v1", model:v2", etc.
By doing so, you will always know the version of the config and model you are using, thus ensuring 100% control.
What is your strategy for storing your configuration files?
#2. 3 ways to do feature transformations
These are 3 ways you didn't know about how you can transform your data when using a feature store.
A feature store helps you quickly solve the training serving skew issue by offering you a consistent way to transform your data into features between the training and inference pipelines.
The issue boils down to WHEN you do the transformation.
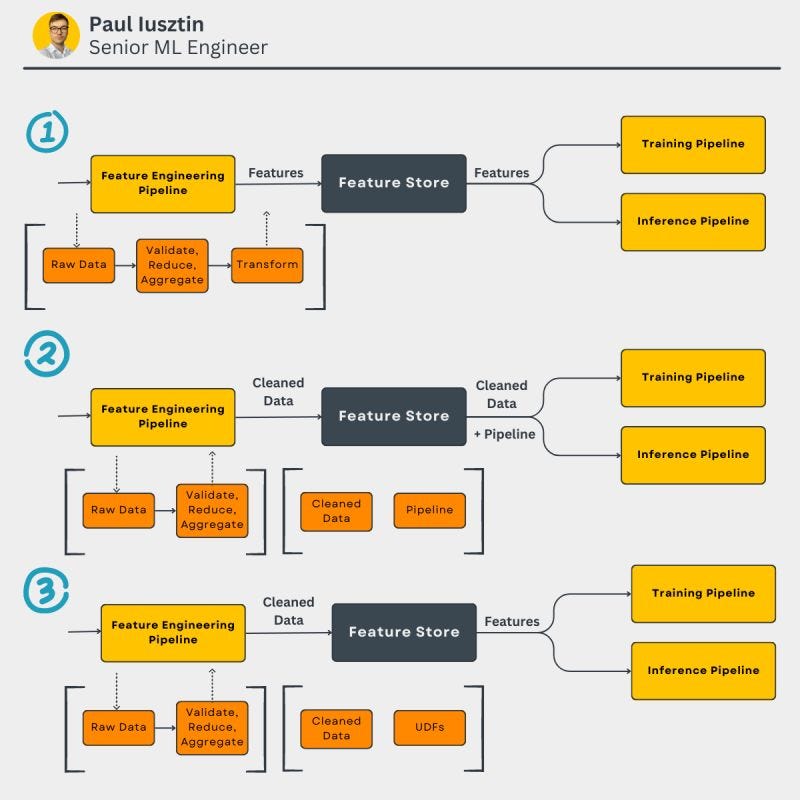
When using a feature store, there are 3 main ways how you can transform your data:
𝟏. 𝐁𝐞𝐟𝐨𝐫𝐞 𝐬𝐭𝐨𝐫𝐢𝐧𝐠 𝐭𝐡𝐞 𝐝𝐚𝐭𝐚 𝐢𝐧 𝐭𝐡𝐞 𝐟𝐞𝐚𝐭𝐮𝐫𝐞 𝐬𝐭𝐨𝐫𝐞
In the feature engineering pipeline, you do everything: clean, validate, aggregate, reduce, and transform your data.
Even if this is the most intuitive way of doing things, it is the worse.
🟢 ultra-low latency
🔴 hard to do EDA on transformed data
🔴 store duplicated/redundant data
𝟐. 𝐒𝐭𝐨𝐫𝐞 𝐭𝐡𝐞 𝐭𝐫𝐚𝐧𝐬𝐟𝐨𝐫𝐦𝐚𝐭𝐢𝐨𝐧 𝐢𝐧 𝐲𝐨𝐮𝐫 𝐩𝐢𝐩𝐞𝐥𝐢𝐧𝐞 𝐨𝐫 𝐦𝐨𝐝𝐞𝐥 𝐩𝐫𝐞-𝐩𝐫𝐨𝐜𝐞𝐬𝐬𝐢𝐧𝐠 𝐥𝐚𝐲𝐞𝐫𝐬
In the feature engineering pipeline, you perform only the cleaning, validation, aggregations, and reductions steps.
Later, by incorporating all your transformations into your pipeline object or pre-processing layers, you automatically save them along your model.
Thus, you can input your cleaned data into your pipeline, and it will know how to handle it.
🟢 store only cleaned data
🟢 easily explore your data
🔴 the transformations are done on the client
𝟑. 𝐘𝐨𝐮 𝐚𝐭𝐭𝐚𝐜𝐡 𝐭𝐨 𝐞𝐯𝐞𝐫𝐲 𝐜𝐥𝐞𝐚𝐧𝐞𝐝 𝐝𝐚𝐭𝐚 𝐬𝐨𝐮𝐫𝐜𝐞 𝐚 𝐔𝐃𝐅 𝐭𝐫𝐚𝐧𝐬𝐟𝐨𝐫𝐦𝐚𝐭𝐢𝐨𝐧
This is similar to solution 2., but instead of attaching the transformation directly to your model, you attached them as a UDF to the feature store.
feature = cleaned data source + UDF
So when you request a feature, the feature store will automatically trigger the UDF on a server and return it.
🟢 store only cleaned data
🟢 easily explore your data
🟢 the transformations are done on the server
🟢 scalable (using Spark)
🔴 hard to implement
As a recap,
There are 3 ways when you can perform your transformations to solve the train serving skew when using a feature store.
What method do you think is the best?
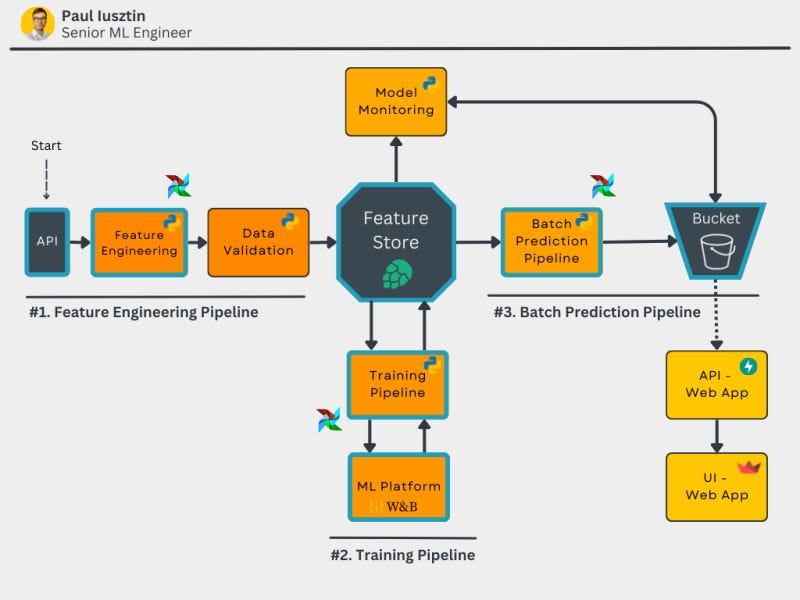
Check out The Full Stack 7-Steps MLOps Framework FREE course that will show you hands-on examples of how to:
implement a hyperparameter tuning pipeline using MLOps good principles
build a feature transformation layer using a Feature Store
Also, it will teach you how to use, design and implement:
a feature engineering pipeline
a training pipeline
a batch prediction pipeline
a feature store
an ML Platform
a storage system to store your predictions
The course is accessible on Medium, and the code is on GitHub:
🔗 Lesson 2: https://medium.com/towards-data-science/a-guide-to-building-effective-training-pipelines-for-maximum-results-6fdaef594cee
🔗 Lesson 3: https://medium.com/towards-data-science/unlock-the-secret-to-efficient-batch-prediction-pipelines-using-python-a-feature-store-and-gcs-17a1462ca489
🔗 GitHub Repository: https://github.com/iusztinpaul/energy-forecasting
DeepLearning.AI just released 3 FREE courses about Generetavie AI.
They are similar to the 1.5-hour ChatGPT Prompt Engineering for Developers course released a while ago.
𝟭. 𝗟𝗮𝗻𝗴𝗖𝗵𝗮𝗶𝗻 𝗳𝗼𝗿 𝗟𝗟𝗠 𝗔𝗽𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻 𝗗𝗲𝘃𝗲𝗹𝗼𝗽𝗺𝗲𝗻𝘁:
"Learn to use memories to store conversations, create sequences of operations to manipulate data, and use the agents' framework as a reasoning engine that can decide for itself what steps to take next."
𝟮. 𝗛𝗼𝘄 𝗗𝗶𝗳𝗳𝘂𝘀𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹𝘀 𝗪𝗼𝗿𝗸:
"Learn to build a diffusion model in PyTorch from the ground up, and see how to start with an image of pure noise and refine it iteratively to generate an image."
𝟯. 𝗕𝘂𝗶𝗹𝗱𝗶𝗻𝗴 𝗦𝘆𝘀𝘁𝗲𝗺𝘀 𝘄𝗶𝘁𝗵 𝘁𝗵𝗲 𝗖𝗵𝗮𝘁𝗚𝗣𝗧 𝗔𝗣𝗜:
"This course takes you beyond prompting and explains how to break a complex task down to be carried out via multiple API calls to an LLM."
I am not a fan of binging courses, but these are short courses packed with information that give you a good understanding of the topic.
If you are motivated, you can crunch them in a single week. At least I will try 😂
See you next week on Thursday at 9:00 am CET.
Have a fabulous weekend!
💡 My goal is to help machine learning engineers level up in designing and productionizing ML systems. Follow me on LinkedIn and Medium for more insights!
🔥 If you enjoy reading articles like this and wish to support my writing, consider becoming a Medium member. Using my referral link, you can support me without extra cost while enjoying limitless access to Medium's rich collection of stories.
Thank you ✌🏼 !