

Why Most RAG Tutorials Fail You
How a senior architect learned RAG from scratch, the production way

Paul: Today, the stage belongs to Priya, a Senior Software Architect who’s spent years shipping production-scale systems at Publicis Sapient and Tesco.
She’s deconstructing RAG with a production-first mindset, skipping the theoretical demos to focus on building for architectural reliability.
This one is packed. Let’s get into it 👀 ↓
The “Deer in the Headlights” Moment
I’ve navigated many shifts since the early days of the web, from monoliths to cloud-native microservices and SOAP to REST. But the AI wave felt different. I found myself in a “deer in the headlights” moment, completely unsure of what to learn or even where to start. Should I dive into neural network math, focus on model training, or master context engineering (AI moves quickly)?
Eventually, the path became clear when I realized my real value lay in applying AI to complex business problems. In an enterprise context, that led me straight to RAG. It isn’t just about the model, it’s also about the robust system you build around it. It felt like a return to architecture, a concrete problem to solve where using AI could make a profound difference. However, as I started building, I hit a second roadblock...
Why Most RAG Tutorials Didn’t Help Me Learn RAG
Most RAG tutorials optimize for one outcome: getting an answer out of a model as quickly as possible. That’s fine for demos. It’s a poor way to learn how RAG systems behave in production.
I’m not new to building production software. I’ve spent decades shipping and maintaining systems where debuggability, operability, and failure modes matter. What’s new to me here is RAG, not the discipline of building systems that survive contact with reality. While learning RAG, I wanted to internalize the constraints I’d eventually face anyway: inspectability, idempotent ingestion, debuggable retrieval, and controllable generation. That meant resisting framework-managed chains and owning the control flow early, even if it slowed me down.
This post documents how I’m teaching myself RAG by building a production-grade system in deliberate phases, using frameworks as utilities rather than architecture.
That approach was heavily influenced by, and indeed, inspired by Paul Iusztin’s From 100+ AI Tools to 4: My Production Stack, especially this idea:
AI frameworks are good utilities. They should not dictate the architecture or control flow of your system.
That became my guiding principle.
Before we continue, a quick word from the Decoding AI team. ↓
Go Deeper: Your Path to Agentic AI for Production
Most engineers know the theory behind agents, context engineering, and RAG. What they lack is the confidence to architect, evaluate, and deploy these systems in production. The Agentic AI Engineering course, built in partnership with Towards AI, closes that gap across 34 lessons (articles, videos, and a lot of code).
By the end, you will have gone from “I built a demo” to “I shipped a production-grade multi-agent system with evals, observability, and CI/CD.” Three portfolio projects, a certificate to back it up in interviews, and a Discord community with direct access to industry experts and Paul Iusztin.

Rated 4.9/5 ⭐️ by 290+ early students — ”Every AI Engineer needs a course like this” and ”an excellent bridge from experimental LLM projects to real-world AI engineering.”
↓ Now, back to the article.
The Architecture
Before diving into the details, here is the end-to-end architecture of the RAG system. This diagram serves as a reference model, and we’ll walk through each layer and the production considerations that shaped these choices.
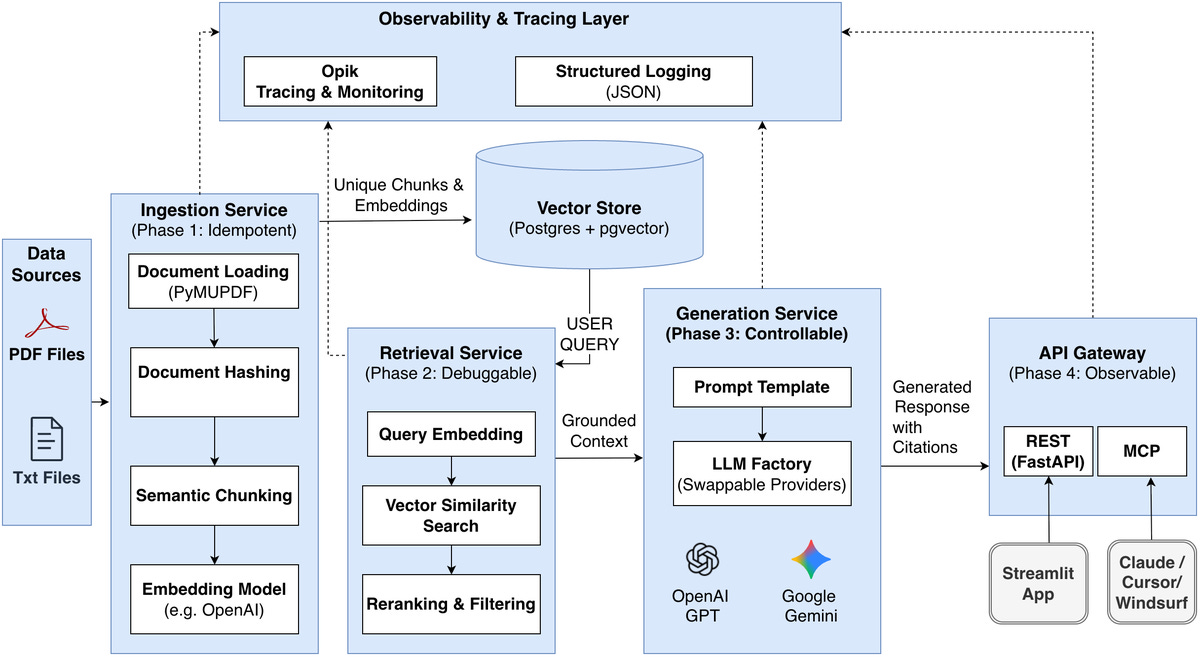
Phase 1. Ingestion: Own the Data
What I built: a pipeline that discovers files → loads documents → normalizes text → chunks → embeds → stores everything in Postgres.
From experience building production systems, ingestion pipelines are where complexity quietly accumulates if they lack idempotence, i.e., the ability to safely re-run without ending up in an inconsistent state, such as duplicate data, partial updates, or stale artifacts. The same applies to traceability, i.e., the ability to trace exactly what happened, to which data, and when. I assumed the same risks would apply here.
What I didn’t account for was how the nature of debugging would differ so vastly from what I was used to in the past. It wasn’t just about emitting log and error information at the right places anymore. A bad chunk doesn’t throw an exception, it just hallucinates an answer three steps later.
Single database, many uses
Instead of introducing a separate vector database, I used Postgres + pgvector. Chunks, embeddings, and metadata live together. That decision buys me a lot:
I can inspect ingestion results with plain SQL
I can join vectors with relational metadata
I can reproduce retrieval behavior outside the application
That inspectability matters when you’re still learning, and having less infrastructure to maintain pays off long after.
Frameworks as utilities, not architecture
I use LangChain’s document loaders (TextLoader, PyMuPDFLoader) for format handling. But the control flow is explicit and mine:
for file_info in discover_files(folder_path):
raw_docs = load_document(file_info.file_path)
clean_text = normalize_text(raw_docs)
chunks = chunk_text(clean_text, chunk_size=512)
embeddings = await embed_chunks(chunks)
await save_to_postgres(file_info, chunks, embeddings)Each step is isolated. Each step can be logged, rerun, or replaced independently. When something breaks, I debug my code, not a framework-managed chain. For instance, during my initial tests, I used PyPDFLoader for the document loading phase. When I inspected the chunking, I realised the chunks had incorrect spaces due to kerning (e.g., ”P r e - C h u n k”). This was easy to address just by swapping PyPDFLoader with PyMuPDFLoader, which handled the complex layouts better.
Idempotence and safe re-runs
I mentioned earlier that pipelines break down when they lack idempotence. Here’s how I addressed it.
Every file’s contents are hashed. If the content hash matches what’s already stored, the file is skipped, no wasted compute, no risk. If the content has changed, its old chunks and embeddings are completely removed before the new ones are written. The database never ends up with a mix of old and new states for the same source.
During development, it makes experimentation safe. For instance, I can tweak chunk sizes, swap embedding models, or change preprocessing logic, then re-run the entire pipeline and trust the result. Without this, every experiment would mean manually cleaning up the database first, or worse, not realizing stale data was still there, silently affecting retrieval quality. More importantly, though, in production, it makes the pipeline resilient to failure. If ingestion crashes halfway through, I can simply restart it. Files already processed are skipped, and the rest pick up where they left off. No manual cleanup, no risk of corruption.
Phase 2. Retrieval: Make Failure Visible
Retrieval is where the quality of your results is determined, which makes debugging discipline more important than clever algorithms.
What I built: query preprocessing → embedding → similarity search → optional reranking.
Most LangChain tutorials show you how to build a RAG pipeline as a “chain,” i.e., a single call where the framework retrieves context, sends it to the LLM, and returns the answer. I chose not to do that. Consistent with the architecture philosophy above, retrieval is an explicit phase, and every step in the retrieval pipeline is an explicit function call I control and invoke directly:
async def retrieve(query: str, top_k: int = 5, rerank: bool = False):
processed_query = preprocess_query(query)
query_embedding = embed_query(processed_query)
results = await search_similar_chunks(query_embedding, top_k)
if rerank:
results = rerank_results(query, results, top_k)
return RetrievalResponse(query=query, results=results)Keeping retrieval explicit makes failures legible. When an answer is wrong, I can tell whether the issue came from:
query preprocessing
embedding quality
recall
ranking
Because vectors live in Postgres, I can reproduce retrieval behavior with SQL alone.
That inspectability is invaluable when learning.
Retrieval → Generation boundary
This is the boundary where many RAG systems start to blur failure modes. But they are fundamentally different problems.
Retrieval, including reranking, decides what context is allowed to reach the model. It is a search problem. It fails by missing relevant information (poor recall) or burying it in noise (poor precision).
Generation decides what the model does with the provided context. It is a reasoning problem. It fails by misinterpreting the context, hallucinating facts, or ignoring instructions.
Keeping this boundary explicit helps you immediately diagnose which problem you effectively have. If the answer is wrong but the context contains the truth, you fix the prompt. If the context is missing the truth, you fix the search.

Phase 3. Generation: Treat the LLM as an Unreliable Dependency
What I built: context formatting → LLM invocation with retries → response assembly.
LLMs fail in ways traditional dependencies don’t. They are non-deterministic, occasionally unavailable, and can return plausible but wrong outputs. I treated the model as an unreliable dependency from day one, something to isolate, observe, and swap, not something to trust implicitly.
Swappable LLMs via a factory
A simple factory pattern makes experimentation cheap:
def get_llm():
if provider == “openai”:
return OpenAIChat(...)
if provider == “gemini”:
return GeminiChat(...)Switching providers requires only configuration changes. Call sites don’t care. This is exactly where frameworks like LangChain shine: as an abstraction layer. They handle the messy API differences between providers so that OpenAIChat and GeminiChat can expose the same interface to your application. Using them here makes swapping models trivial, without letting them dictate your control flow.
Explicit orchestration over chains
Generation is intentionally step-by-step:
async def generate_answer(request):
retrieval_response = await retrieve(query=request.query, ...)
context_text = format_docs(retrieval_response)
messages = get_rag_prompt().format_messages(
context=context_text,
question=request.query,
)
llm = get_llm()
ai_message = await _invoke_llm_with_retry(llm, messages)
return GenerateResponse(answer=ai_message.content, ...)I avoided using LangChain’s expression language (LCEL) or runnable abstractions to build this flow. While powerful, they can hide what’s happening. Explicit orchestration is easier to debug, instrument, and reason about, especially while learning. This resonated with me even more since I’m used to a hands-on approach where I can write code and truly understand how the logic flows.
Retries are operational, not semantic
LLM calls fail for mundane reasons: transient network issues, provider-side throttling, or brief outages. I treat those as operational failures, not model behavior, and handle them explicitly.
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=1, max=10),
)
async def _invoke_llm_with_retry(llm, messages):
return await llm.ainvoke(messages)Retries don’t make the model correct, they make the system resilient.
Phase 4. Serving: Thin Adapters, Shared Core
What I built: two interfaces over the same RAG core: a REST API and an MCP server.
In many RAG implementations, the retrieval logic is tightly coupled to the web framework (e.g., defined inside a FastAPI route). This makes it hard to test the logic in isolation or reuse it in different contexts (like a CLI or an evaluation script).
Instead, I treated my RAG system as a standalone library. The core function ‘generate_answer’ takes a pure Pydantic object and returns one. It knows nothing about HTTP, headers, or JSON.
This architecture allowed me to treat serving as a thin adapter pattern.
Adapter 1: REST API (FastAPI)
The REST adapter serves traditional software systems that need deterministic access to the retrieval layer. This includes web applications, backend services, internal tooling, evaluation pipelines, and automation jobs. These are environments where the caller decides exactly when and how the capability should be invoked.
The web layer itself does no extra work. It merely deserializes JSON, calls the core, and serializes the result.
@router.post(”“, response_model=GenerateResponse)
async def query(request: GenerateRequest) -> GenerateResponse:
return await generate_answer(request)Adapter 2: MCP Server (Capability Interface for Tool-Using LLMs)
Exposing the same core through the Model Context Protocol (MCP) transforms my RAG pipeline from an application-bound feature into a standardized capability.
MCP standardizes how capabilities are exposed to tool-using LLMs, regardless of whether the caller is a chat assistant, a coding copilot, or an autonomous agent.
I’m used to abstraction via careful refactoring, and it didn’t take long to understand that MCP was just another way of achieving this in the context of AI.
MCP-compatible clients such as Claude Desktop, Cowork, or Cursor can connect to the server and invoke the query_rag tool directly. This allows the underlying LLM to ground its responses in private data without requiring custom integrations, plugins, or connector logic.
Direct tool access is useful, but the MCP interface becomes far more valuable as agents adopt skills to carry out knowledge work and other multi-step tasks. For example, a “Market Research Skill” might combine web search, financial data lookup, and document retrieval. By exposing my RAG system as an MCP Tool, it becomes a standardized block that these skills can easily include in their workflows, without needing custom code.
@mcp.tool()
async def query_rag(query: str, top_k: int = 5, rerank: bool = True) -> dict:
request = GenerateRequest(query=query, top_k=top_k, rerank=rerank)
response = await generate_answer(request)
return response.model_dump()Both interfaces share the same core logic, thus avoiding duplication. Serving is an adapter problem, not a RAG problem.
Data lineage & traceability
Traceability isn’t new. Long before LLMs, production systems relied on lineage and identifiers to make failures debuggable. LLM non-determinism makes that discipline more important, not less.
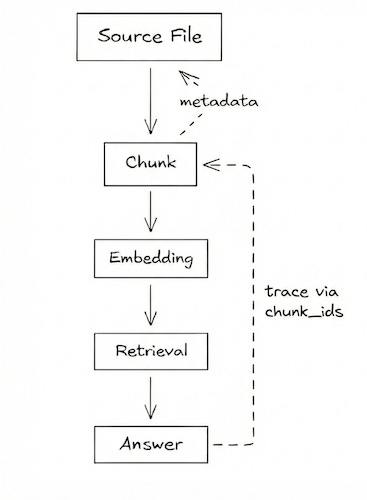
Debugging RAG systems almost always means reasoning backward, from an answer, to retrieved chunks, to embeddings, and finally to source files.
In practice, this meant persisting identifiers at every step. Retrieved results carry chunk IDs forward. Generation logs include the IDs of the chunks used as context. When an answer looks wrong, I can trace it deterministically back to its source.
Without lineage, every bad answer looks like a model problem. With it, failures become diagnosable and fixable.
Vendor-neutral observability
This isn’t RAG specific. It’s the same observability discipline I’ve applied in other production systems. I deliberately kept it vendor-neutral, following a pattern I’ve used before to keep core logic decoupled from tooling.
Beyond tracing execution paths, tools like Opik let me reason about operational realities: latency per phase, token usage, and cost per request. Being able to see which model was invoked, how many tokens were consumed, and where time was spent turns performance and cost from assumptions into measurable signals.
def track(name: str = None, phase: Phase = None):
def decorator(func):
tags = [f”phase:{phase.value}”] if phase else []
@opik.track(name=name, tags=tags)
def wrapper(*args, **kwargs):
return func(*args, **kwargs)
return wrapper
return decoratorIf I ever switch observability tools, business code doesn’t change.
What I’m Exploring Next
Next steps include:
Adding durable workflow orchestration (DBOS or Prefect)
Implementing systematic evaluation for retrieval quality and faithfulness
Exploring more advanced retrieval patterns
Each will be added deliberately, one constraint at a time.
Closing Thoughts
Moving from keyword search to semantic and multimodal understanding is a massive leap in how we solve problems. While this technology introduces an ambiguity that contrasts with the deterministic systems I’ve built before, the incredible advantages and sheer problem-solving power it offers make the challenge truly exciting.
Building RAG this way slowed me down, deliberately.
What I have now is a system I can inspect, rerun, and reason about when something goes wrong. For me, that’s a better foundation than a faster demo.
I’m still learning RAG. But I’m learning it with the same instincts that shaped the rest of my career: make systems observable, design for failure, and own the control flow before adding abstraction.
Code: https://github.com/CalvHobbes/rag-101
Inspired by: From 100+ AI Tools to 4: My Production Stack by Paul Iusztin
See you next time.
What’s your opinion? Do you agree, disagree, or is there something I missed?
Enjoyed the article? The most sincere compliment is to share our work.
Whenever you’re ready, here is how I can help you
Go from agent user to agent builder. Master the foundations of AI agents and turn fragile demo code into reliable, production-ready systems with my course, Agent Engineering: Building Multi-Agent Systems (made with Towards AI).
35 lessons. Pure foundations from scratch. 4 mini-projects. 2 production systems. A certificate and direct access to me & industry experts in our Discord.
Built for software and data professionals transitioning into AI engineering. Rated 5/5 with 300+ students. The first 7 lessons are free:
Not ready to commit? Start with our free Agent AI Engineering Guide, a 6-day email course on the mistakes that silently break AI agents in production.
Images
If not otherwise stated, all images are created by the author.
 | A guest post by
|
Thanks for contributing to this amazing piece!
Great write-up on building a production-quality RAG system.
I recently built something similar and thought it might be useful to share another implementation for comparison. The latest version of my project is rag-foundry-universal, which aims to be “universal” in the sense that it can ingest a variety of document types, including entire Python repositories, and then allow you to query them.
It expects that you already have Ollama installed and Docker available (Docker Desktop works well). Once running, it can index a repo and let you ask questions about the codebase. It’s intentionally not agentic—the focus was on keeping the architecture simple and reliable for retrieval and question answering over code.
It does not do other languages such as java as yet .
Repo: https://github.com/sankar-ramamoorthy/rag-foundry-universal
For comparison, this implementation by Priya includes additional observability and evaluation tooling (for example using Opik), which is an interesting direction for testing and tracing RAG pipelines:
https://github.com/CalvHobbes/rag-101
Curious how others are approaching evaluation and observability as RAG systems move toward more production-oriented setups