

The difference between development and continuous training ML environments
Looking to become a PRO in LangChain? How to write a streaming retrieval system for RAG on social media data.

Decoding ML Notes
This week’s topics:
Looking to become a PRO in LangChain?
The difference between development and continuous training ML environments
How to write a streaming retrieval system for RAG on social media data
First, I want to thank everyone who supported our Hands-on LLMs course repo 🙏🏻
The 𝗛𝗮𝗻𝗱𝘀-𝗼𝗻 𝗟𝗟𝗠𝘀 FREE 𝗰𝗼𝘂𝗿𝘀𝗲 passed 2.1k+ ⭐️ on GitHub - the place to 𝗹𝗲𝗮𝗿𝗻 the 𝗳𝘂𝗻𝗱𝗮𝗺𝗲𝗻𝘁𝗮𝗹𝘀 of 𝗟𝗟𝗠 𝘀𝘆𝘀𝘁𝗲𝗺𝘀 & 𝗟𝗟𝗠𝗢𝗽𝘀
𝘛𝘩𝘦 𝘤𝘰𝘶𝘳𝘴𝘦 𝘪𝘴 𝘵𝘩𝘦 𝘨𝘰-𝘵𝘰 𝘩𝘶𝘣 𝘧𝘰𝘳 𝘭𝘦𝘢𝘳𝘯𝘪𝘯𝘨 𝘵𝘩𝘦 𝘧𝘶𝘯𝘥𝘢𝘮𝘦𝘯𝘵𝘢𝘭𝘴 𝘰𝘧 𝘱𝘳𝘰𝘥𝘶𝘤𝘵𝘪𝘰𝘯-𝘳𝘦𝘢𝘥𝘺 𝘓𝘓𝘔𝘴 & 𝘓𝘓𝘔𝘖𝘱𝘴
It will walk you through an 𝗲𝗻𝗱-𝘁𝗼-𝗲𝗻𝗱 𝗽𝗿𝗼𝗰𝗲𝘀𝘀...
...from data preparation to deployment & monitoring:
- the 3-pipeline design
- building your custom financial dataset using GPT-4
- a streaming pipeline to ingest financial news in real-time
- fine-tuning an LLM using QLoRA
- building a custom RAG pipeline
- deploying the streaming pipeline to AWS
- deploying the training & inference pipelines to Beam
- using MLOps components: model registries, experiment trackers, prompt monitoring

𝗖𝗵𝗲𝗰𝗸 𝗶𝘁 𝗼𝘂𝘁
↓↓↓
🔗 𝘏𝘢𝘯𝘥𝘴-𝘰𝘯 𝘓𝘓𝘔𝘴 𝘊𝘰𝘶𝘳𝘴𝘦 - 𝘓𝘦𝘢𝘳𝘯 𝘵𝘰 𝘛𝘳𝘢𝘪𝘯 𝘢𝘯𝘥 𝘋𝘦𝘱𝘭𝘰𝘺 𝘢 𝘙𝘦𝘢𝘭-𝘛𝘪𝘮𝘦 𝘍𝘪𝘯𝘢𝘯𝘤𝘪𝘢𝘭 𝘈𝘥𝘷𝘪𝘴𝘰𝘳
Looking to become a PRO in LangChain?
Then 𝗰𝗵𝗲𝗰𝗸 𝗼𝘂𝘁 this 𝗯𝗼𝗼𝗸 on 𝗵𝗮𝗻𝗱𝘀-𝗼𝗻 𝗟𝗮𝗻𝗴𝗖𝗵𝗮𝗶𝗻: from 𝗯𝗲𝗴𝗶𝗻𝗻𝗲𝗿 to 𝗮𝗱𝘃𝗮𝗻𝗰𝗲𝗱 ↓
→ It's called: 𝘎𝘦𝘯𝘦𝘳𝘢𝘵𝘪𝘷𝘦 𝘈𝘐 𝘸𝘪𝘵𝘩 𝘓𝘢𝘯𝘨𝘊𝘩𝘢𝘪𝘯: 𝘉𝘶𝘪𝘭𝘥 𝘓𝘓𝘔 𝘢𝘱𝘱𝘴 𝘸𝘪𝘵𝘩 𝘗𝘺𝘵𝘩𝘰𝘯, 𝘊𝘩𝘢𝘵𝘎𝘗𝘛, 𝘢𝘯𝘥 𝘰𝘵𝘩𝘦𝘳 𝘓𝘓𝘔𝘴 by Ben Auffarth , published by Packt
𝘏𝘦𝘳𝘦 𝘪𝘴 𝘢 𝘴𝘩𝘰𝘳𝘵 𝘣𝘳𝘦𝘢𝘬𝘥𝘰𝘸𝘯:
- It begins with some theoretical chapters on LLMs & LangChain
- It explores the critical components of LangChain: chains, agents, memory, tools
𝗧𝗵𝗲𝗻, 𝗺𝘆 𝗳𝗮𝘃𝗼𝗿𝗶𝘁𝗲 𝗽𝗮𝗿𝘁...
𝗜𝘁 𝗷𝘂𝗺𝗽𝘀 𝗱𝗶𝗿𝗲𝗰𝘁𝗹𝘆 𝗶𝗻𝘁𝗼 𝗵𝗮𝗻𝗱𝘀-𝗼𝗻 𝗲𝘅𝗮𝗺𝗽𝗹𝗲𝘀 - 𝗪𝗜𝗧𝗛 𝗣𝗬𝗧𝗛𝗢𝗡 𝗖𝗢𝗗𝗘 ↓
- takes off with beginner-friendly examples of using LangChain with agents, HuggingFace, GCP/VertexAI, Azure, Anthropic, etc.
- shows an end-to-end example of building a customer services application with LangChain & VertexAI
- how to mitigate hallucinations using the 𝘓𝘓𝘔𝘊𝘩𝘦𝘤𝘬𝘦𝘳𝘊𝘩𝘢𝘪𝘯 class
- how to implement map-reduce pipelines
- how to monitor token usage & costs
- how to extract information from documents such as PDFs
- building a Streamlit interface
- how reasoning works in agent
- building a chatbot like ChatGPT from SCRATCH
.
I haven't finished it yet, but I love it so far —I plan to finish it soon.
.
𝗪𝗵𝗼 𝗶𝘀 𝘁𝗵𝗶𝘀 𝗳𝗼𝗿?
If you are 𝘀𝘁𝗮𝗿𝘁𝗶𝗻𝗴 𝗼𝘂𝘁 in the LLM world, this is a great book to 𝗿𝗲𝗮𝗱 𝗲𝗻𝗱-𝘁𝗼-𝗲𝗻𝗱.
Even if you are 𝗲𝘅𝗽𝗲𝗿𝗶𝗲𝗻𝗰𝗲𝗱, I think it is 𝗲𝘅𝘁𝗿𝗲𝗺𝗲𝗹𝘆 𝘂𝘀𝗲𝗳𝘂𝗹 to 𝘀𝗸𝗶𝗺 𝗶𝘁 to refresh the fundamentals, learn new details, and see how everything is implemented in LangChain.

𝗜𝘀 𝘁𝗵𝗶𝘀 𝗳𝗼𝗿 𝘆𝗼𝘂? 🫵
🔗 𝗖𝗵𝗲𝗰𝗸 𝗶𝘁 𝗼𝘂𝘁: Generative AI with LangChain [By Ben Auffarth]
The difference between development and continuous training ML environments
They might do the same thing, but their design is entirely different ↓
𝗠𝗟 𝗗𝗲𝘃𝗲𝗹𝗼𝗽𝗺𝗲𝗻𝘁 𝗘𝗻𝘃𝗶𝗿𝗼𝗻𝗺𝗲𝗻𝘁
At this point, your main goal is to ingest the raw and preprocessed data through versioned artifacts (or a feature store), analyze it & generate as many experiments as possible to find the best:
- model
- hyperparameters
- augmentations
Based on your business requirements, you must maximize some specific metrics, find the best latency-accuracy trade-offs, etc.
You will use an experiment tracker to compare all these experiments.
After you settle on the best one, the output of your ML development environment will be:
- a new version of the code
- a new version of the configuration artifact
Here is where the research happens. Thus, you need flexibility.
That is why we decouple it from the rest of the ML systems through artifacts (data, config, & code artifacts).
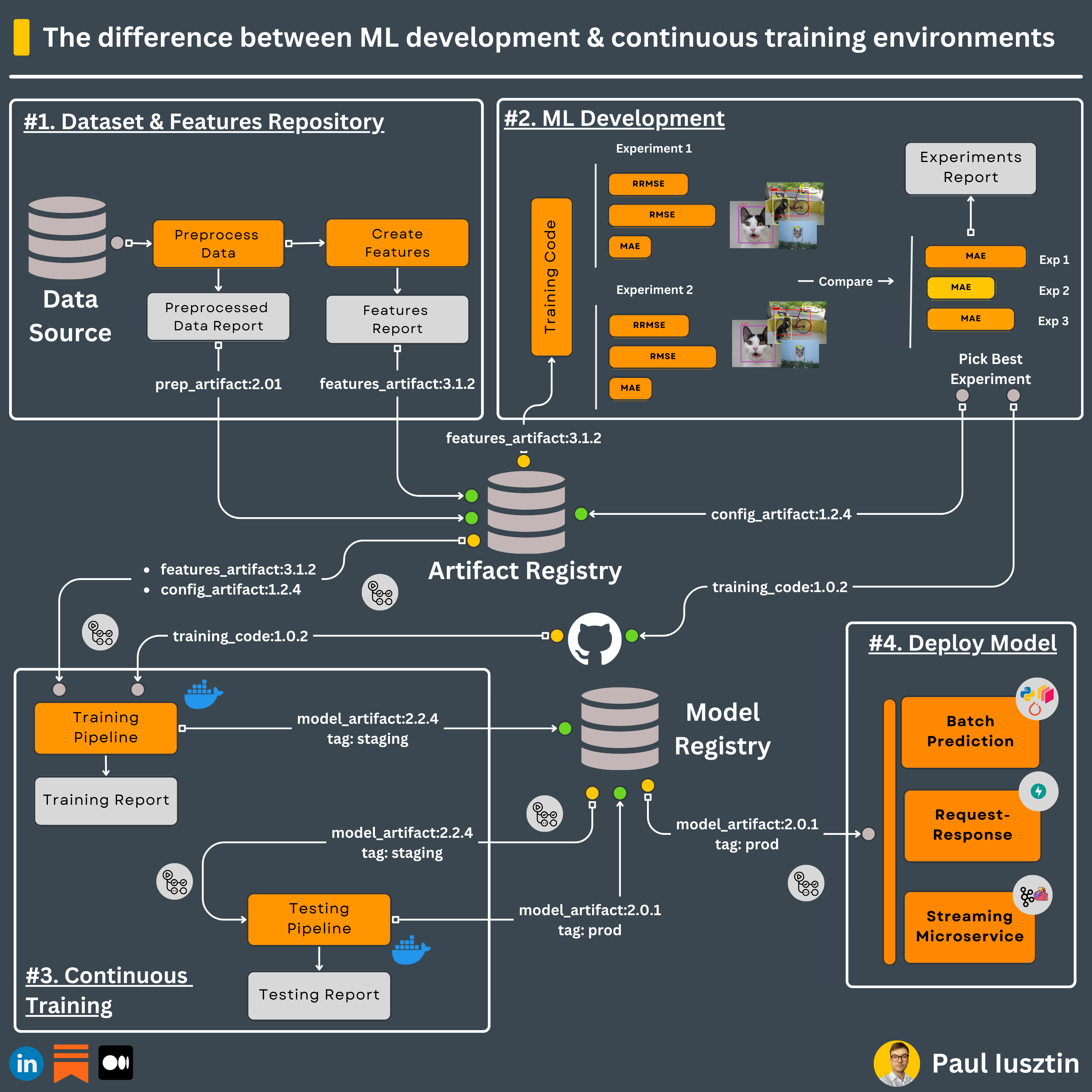
𝗖𝗼𝗻𝘁𝗶𝗻𝘂𝗼𝘂𝘀 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗘𝗻𝘃𝗶𝗿𝗼𝗻𝗺𝗲𝗻𝘁
Here is where you want to take the data, code, and config artifacts and:
- train the model on all the required data
- output a staging versioned model artifact
- test the staging model artifact
- if the test passes, label it as the new production model artifact
- deploy it to the inference services
A common strategy is to build a CI/CD pipeline that (e.g., using GitHub Actions):
- builds a docker image from the code artifact (e.g., triggered manually or when a new artifact version is created)
- start the training pipeline inside the docker container that pulls the feature and config artifacts and outputs the staging model artifact
- manually look over the training report -> If everything went fine, manually trigger the testing pipeline
- manually look over the testing report -> if everything worked fine (e.g., the model is better than the previous one), manually trigger the CD pipeline that deploys the new model to your inference services
Note how the model registry quickly helps you to decouple all the components.
Also, because training and testing metrics are not always black and white, it is challenging to automate the CI/CD pipeline 100%.
Thus, you need a human in the loop when deploying ML models.
To conclude...
The ML development environment is where you do your research to find better models.
The continuous training environment is used to train & test the production model at scale.
How to write a streaming retrieval system for RAG on social media data
𝗕𝗮𝘁𝗰𝗵 𝘀𝘆𝘀𝘁𝗲𝗺𝘀 are the 𝗽𝗮𝘀𝘁. Here is how to 𝘄𝗿𝗶𝘁𝗲 a 𝘀𝘁𝗿𝗲𝗮𝗺𝗶𝗻𝗴 𝗿𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹 𝘀𝘆𝘀𝘁𝗲𝗺 for 𝗥𝗔𝗚 on 𝘀𝗼𝗰𝗶𝗮𝗹 𝗺𝗲𝗱𝗶𝗮 𝗱𝗮𝘁𝗮 ↓
𝗪𝗵𝘆 𝘀𝘁𝗿𝗲𝗮𝗺𝗶𝗻𝗴 𝗼𝘃𝗲𝗿 𝗯𝗮𝘁𝗰𝗵?
In environments where data evolves quickly (e.g., social media platforms), the system's response time is critical for your application's user experience.
That is why TikTok is so addicting. Its recommender system adapts in real-time based on your interaction with the app.
How would it be if the recommendations were updated daily or hourly?
Well, it would work, but you would probably get bored of the app much faster.
The same applies to RAG for highly intensive data sources...
→ where you must sync your source and vector DB in real time for up-to-date retrievals.
𝘓𝘦𝘵'𝘴 𝘴𝘦𝘦 𝘩𝘰𝘸 𝘪𝘵 𝘸𝘰𝘳𝘬𝘴.
↓↓↓
I wrote an 𝗮𝗿𝘁𝗶𝗰𝗹𝗲 on how to 𝗯𝘂𝗶𝗹𝗱 a 𝗿𝗲𝗮𝗹-𝘁𝗶𝗺𝗲 𝗿𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹 𝘀𝘆𝘀𝘁𝗲𝗺 for 𝗥𝗔𝗚 on 𝗟𝗶𝗻𝗸𝗲𝗱𝗜𝗻 𝗱𝗮𝘁𝗮 in collaboration with Superlinked .
The 𝗿𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹 𝘀𝘆𝘀𝘁𝗲𝗺 is based on 𝟮 𝗱𝗲𝘁𝗮𝗰𝗵𝗲𝗱 𝗰𝗼𝗺𝗽𝗼𝗻𝗲𝗻𝘁𝘀:
- the streaming ingestion pipeline
- the retrieval client
The 𝘀𝘁𝗿𝗲𝗮𝗺𝗶𝗻𝗴 𝗶𝗻𝗴𝗲𝘀𝘁𝗶𝗼𝗻 𝗽𝗶𝗽𝗲𝗹𝗶𝗻𝗲 runs 24/7 to keep the vector DB synced with the current raw LinkedIn posts data source.
The 𝗿𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹 𝗰𝗹𝗶𝗲𝗻𝘁 is used in RAG applications to query the vector DB.
→ These 2 components are completely decoupled and communicate with each other through the vector DB.
#𝟭. 𝗧𝗵𝗲 𝘀𝘁𝗿𝗲𝗮𝗺𝗶𝗻𝗴 𝗶𝗻𝗴𝗲𝘀𝘁𝗶𝗼𝗻 𝗽𝗶𝗽𝗲𝗹𝗶𝗻𝗲
→ Implemented in Bytewax - a streaming engine built in Rust (speed& reliability) that exposes a Python interface
𝘔𝘢𝘪𝘯 𝘧𝘭𝘰𝘸:
- uses CDC to add changes from the source DB to a queue
- listens to the queue for new events
- cleans, chunks, and embeds the LI posts
- loads them to a Qdrant vector DB
and... everything in real-time!

#𝟮. 𝗧𝗵𝗲 𝗿𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹 𝗰𝗹𝗶𝗲𝗻𝘁
→ A standard Python module.
The goal is to retrieve similar posts using various query types, such as posts, questions, and sentences.
𝘔𝘢𝘪𝘯 𝘧𝘭𝘰𝘸:
- preprocess user queries (the same way as they were ingested)
- search the Qdrant vector DB for the most similar results
- use rerank to improve the retrieval system's accuracy
- visualize the results on a 2D plot using UMAP
.
You don't believe me? 🫵
𝗖𝗵𝗲𝗰𝗸 𝗼𝘂𝘁 𝘁𝗵𝗲 𝗳𝘂𝗹𝗹 𝗮𝗿𝘁𝗶𝗰𝗹𝗲 & 𝗰𝗼𝗱𝗲 𝗼𝗻 𝗗𝗲𝗰𝗼𝗱𝗶𝗻𝗴 𝗠𝗟 ↓
🔗 𝘈 𝘙𝘦𝘢𝘭-𝘵𝘪𝘮𝘦 𝘙𝘦𝘵𝘳𝘪𝘦𝘷𝘢𝘭 𝘚𝘺𝘴𝘵𝘦𝘮 𝘧𝘰𝘳 𝘙𝘈𝘎 𝘰𝘯 𝘚𝘰𝘤𝘪𝘢𝘭 𝘔𝘦𝘥𝘪𝘢 𝘋𝘢𝘵𝘢
Images
If not otherwise stated, all images are created by the author.