

Inside Neo4j's Agent Memory
The knowledge-graph patterns that turn one-shot conversations into compounding intelligence.


I already have a second brain setup based on Obsidian, Readwise, NotebookLM, and Claude Code. I dump all my notes, research, and highlights there. Whenever I want to create content, I create a scoped wiki targeted toward the topic. I gather information from my second brain using a deep research algorithm on top of my private data and external resources via NotebookLM. The wiki is structured like the LLM Knowledge Base presented by Andrej Karpathy.
This setup fails to extract and maintain shared entities, preferences, and facts across the wiki as the knowledge base grows. For example, if the topic “Claude Code” is mentioned in 10 documents, I want to extract all the metadata about it into its dedicated folder. I want to see what other entities it relates to, such as Anthropic, San Francisco, Codex, or Gemini CLI. I also want to see how many documents mention it to rank frequency. You can do that with a pure file-based system and Obsidian, but performance degrades when your data scales past 50 documents.
The same concept applies to any unstructured knowledge base. You need a way to extract and connect knowledge from your conversations, documents, and images. This becomes essential between conversations so your agent doesn’t forget you. Instead, it provides a personalized experience. It’s also critical for context engineering to inject the right context at the right time and keep the LLM focused on relevant facts.
Most teams default to one of two memory approaches. Both collapse under real use. A file system gives you append-only logs that the agent re-reads from scratch, which fragments and rots context.
A vector index gives you fuzzy semantic recall but no merge, no identity, and no way to know if this is the same Karpathy you knew yesterday. Durable AI memory requires a structured graph to track identity and relationships [1]. Without this structure, the assistant forgets past interactions and fails to build compounding intelligence.
Knowledge-graph memory is the next step on the arc from Retrieval-Augmented Generation (RAG) to agentic RAG to agent memory [2]. Building a unified knowledge-graph memory system is hard, so most teams skip it.
During my research, I stumbled upon neo4j-labs/agent-memory. It’s a masterpiece. Who knows more about knowledge graphs (KGs) than Neo4j?
After I spent 2 days playing with it and understanding the codebase, I realized it was the perfect mental model for any agent memory system powered by KGs.
In this article, I’ll walk through the core architectural patterns of neo4j-labs/agent-memory. It features 1 graph, 3 memory tiers, the POLE+O ontology, a 3-stage extraction pipeline, a composite resolver, and the SAME_AS pattern.
By the end, you’ll have a concrete mental model. You can ship on top of their Software Development Kit (SDK) or hook it into your agent via their Model Context Protocol (MCP) server. Alternatively, you can steal the patterns and ship the same architecture on Postgres or MongoDB if a full graph database in production doesn’t make sense for your use case.
Start Your Transition Into AI Engineering (Product)

This article shows the memory layer your agent needs. My Agentic AI Engineering course shows the harness around it, and I just released a free preview that lets you build and run a working agent in 5 minutes.
You build a multi-agent system with two MCP servers (Research Agent + Writing Workflow), a deep research algorithm, an evaluator-optimizer loop, observability, and LLM-as-judge evals. The production patterns behind agents that actually ship.
Built for software, data engineers or scientists transitioning into AI engineering.
7 free lessons, 2 MCP agents ready for your GitHub portfolio. Part of the 35-lesson course. Rated 5/5 by 300+ students.
What’s Inside neo4j-labs/agent-memory
The SDK takes natural-language interactions on the write side and returns a fused memory context on the read side. Everything anchors to a single Neo4j graph. For our scoped wiki, notes and Readwise highlights about Claude Code flow in. A structured pull of what the agent knows about Claude Code, how it relates to Anthropic, and its frequency across 50 documents comes out.
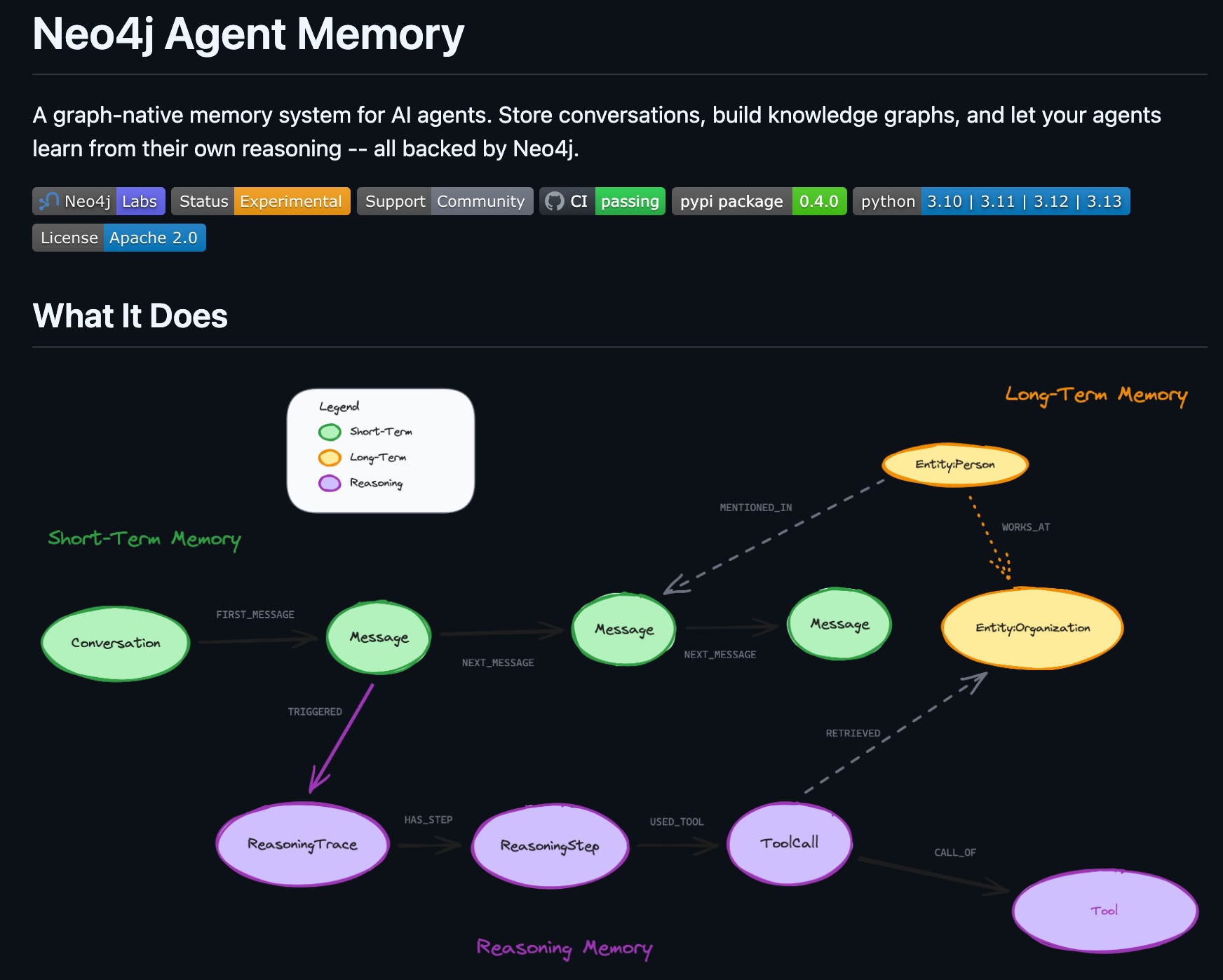
At its core, there is 1 graph and 3 memory tiers joined by typed edges: short-term conversations, long-term typed entities, and reasoning traces. They’re stitched together by :MENTIONS, :TOUCHED, and :INITIATED_BY relationships [3].
The architecture contains 8 small, single-responsibility modules. The models/ module holds Pydantic schemas. The schema/ module handles Cypher migrations. The extraction/ module runs the Named Entity Recognition (NER) pipeline. The resolution/ module holds the composite resolver. The dedup/ module manages the SAME_AS pattern. The core/ module provides MemoryClient.get_context(). The mcp/ module runs the FastMCP server with 15 tools. The integrations/ module holds 9 framework adapters for tools like LangChain and LlamaIndex.

Consider an end-to-end scenario. You drop a Readwise highlight about Claude Code into your scoped wiki. The extraction/ module pulls Claude Code as an Object, Anthropic as an Organization, and Codex as an Object. The resolution/ module canonicalizes each against existing nodes. The dedup/ module checks vector similarity and either auto-merges or flags a pending :SAME_AS edge. The schema/ module commits :MENTIONS edges from the note to each entity.
Later, MemoryClient.get_context() pulls fused context across the same graph in one call. This matters concretely for the scoped-wiki agent. You can ask what you discussed last session, what you know about Claude Code, and why the agent surfaced a Codex comparison last Tuesday. The SDK answers all three against the same graph. It uses the same Cypher dialect with no cross-store join logic.
Short-Term, Long-Term, Reasoning Memory
The SDK splits memory into three layers that all live on the same Neo4j graph [3]. Short-term memory is the linear message sequence. It uses ordered :Message nodes chained by :NEXT edges, scoped to a :Conversation. Long-term memory is the typed entity graph. It uses deduplicated :Entity nodes with vector embeddings and arbitrary domain relationships.
Reasoning memory is a tree per agent run. It uses a :ReasoningTrace root with child :ReasoningStep nodes capturing thoughts and tool calls. For the scoped-wiki agent, short-term memory holds your current chat. Long-term memory holds the canonical Claude Code entity plus its relations to Anthropic, San Francisco, Codex, and Gemini CLI. Reasoning memory holds the trace of how the agent picked those specific notes to answer you.
Three relationships do the entire stitching. The :MENTIONS edge joins short-term to long-term memory. The :INITIATED_BY edge joins reasoning to short-term memory. The :TOUCHED edge joins reasoning to long-term memory. These three edges make provenance a one-hop query rather than a log-reconstruction project.

:MENTIONS, :INITIATED_BY, :TOUCHED) make every cross-tier question a one-hop query.Reasoning memory is the novelty from this architecture. By storing past successful or failed thinking patterns into the memory, the agent can one-shot future similar requests or at least know not to repeat similar mistakes. Intuitively, it’s similar to Reinforcement Learning (RL), but instead of baking the optimizations into the weights, you do it at the database level.
The most important part of this architecture is the ontology.
The Ontology
The long-term memory uses a closed five-type vocabulary for its ontology known as POLE+O. It uses Person, Object, Location, Event, and Organization, borrowed from intelligence-analysis taxonomies [5]. Every entity is exactly one of these five types. Subtypes are open, but the top-level vocabulary is fixed.
In the personal assistant, Karpathy is a Person. Claude Code is an Object. Anthropic is an Organization. Your Tuesday deep-research run is an Event. San Francisco is a Location.
Type and subtype materialize as multi-tier Neo4j labels. The query builder sanitizes and PascalCases them into labels like :Entity:Person:Individual. You can search by type or subtype, making this solution highly efficient.
Using this strategy, you can extend each core type from POLE+O with your own custom domain. Other defaults are: :Entity:Location:City, :Entity:Event:Concert, :Entity:Organization:Company, etc. Here is a catalog of over 20 domains such as Data Journalism, Gaming, Personal Knowledge, and Product Management.
Entities modeled via POLE+O are nouns. The SDK adds 2 other node types beyond entities.
:Fact nodes hold every claim mentioned in the text. They’re intentionally generic so the ontology doesn’t get over-specified. They serve as a fallback when nothing else fits. You can intuitively see them as chunks of text that contain only 1 concept.
Then there are :Preference nodes that store user preferences via a SUPERSEDED_BY relationship. As agent memory is user-centric, this provides the WOW effect where the agent remembers past preferences and learns from them over time.
For the scoped wiki, “Anthropic developed Claude Code” is an edge. “Claude Code 1.0 shipped in 2025” is a :Fact. “I prefer agent-harness comparisons over pure benchmarks” is a :Preference.

:RELATED_TO edge with the semantic name carried as a property.Extraction: From Raw Text to Typed Entities
The SDK runs entity extraction as a speed-versus-accuracy ladder. It uses spaCy for fast statistical NER. It uses GLiNER and GLiREL for zero-shot extraction. It uses an LLM stage for cases that need real semantics and to extract the relationships between them [6].
Each stage maps its outputs back to POLE+O types. It uses explicit merge strategies when 2 extractors disagree. When you drop a Readwise highlight about Claude Code into your scoped wiki, spaCy lifts proper nouns like Anthropic and San Francisco. GLiNER catches domain entities like Claude Code and Gemini CLI. The LLM stage only fires when the previous 2 stages leave ambiguity, or when the model needs to extract relationships.

Routing every mention through an LLM would multiply extraction cost massively for marginal recall on rare entities. The ladder pushes high-confidence cases to cheap models. It escalates only ambiguous mentions to the zero-shot models and reserves the LLM stage for when real semantics matter.
The real problem is at the normalization step.
When Two Mentions Are the Same Entity (And When They Aren’t)
Resolution and deduplication are 2 different problems. Resolution sets a canonical string property on an existing reference. Deduplication decides whether a new node gets created at all. Conflating them is how graphs end up with 3 Anthropic nodes that none of your queries find together [7].
Resolution runs 3 strategies on the name field in cost order. Exact matches existing canonical strings. Fuzzy uses RapidFuzz string similarity for surface variants like “A. Karpathy” and “Karpathy, Andrej”. Semantic falls back to embedding similarity for cases like “the founder of Eureka Labs”. It only matches between nodes of the same type, meaning a Person only resolves against Person candidates.
After resolution runs, two mentions like “Apple” and “Apple Inc.” end up with different surface names but the same canonical name. That’s why a second step is needed. Deduplication looks at the semantics, not just the name.

For deduplication, the SDK uses vector and fuzzy similarity across the entire node content. This ensures the node is actually the same, not just a name coincidence. In other words, this avoids false positives. Using vector and fuzzy search, the SDK computes a score.
Scores at or above 0.95 trigger an auto-merge. Scores below 0.85 create a new node. Scores between 0.85 and 0.95 don’t silently merge. Instead, they create a :SAME_AS edge with a pending status. This flags the edge for a human or downstream agent to resolve later. This pattern stops “Jensen Huang the NVIDIA CEO” from merging with “Jensen Huang the Taipei dermatologist” just because their embeddings landed 0.91 apart [7].
A false merge is silent and unrecoverable. A false split is noisy but recoverable. You can’t undo a false merge without re-ingesting from the raw source data. That’s why you should leave uncertainty to a human.
Zooming into the Retrieval Algorithm
Because all three tiers live on one graph, a single retrieval can compose vector similarity over :Entity embeddings, multi-hop expansion over typed relationships, time-ordered :NEXT conversation walks, and reasoning-trace lookups via :INITIATED_BY and :TOUCHED joins. All of these run as steps in the same Cypher query. Neo4j 5.20 introduces db.index.vector.queryNodes, making vector similarity a first-class graph operation [4].
When you ask what you know about Claude Code, how it relates to Codex and Gemini CLI, and why you looked at it last week, the agent fuses three things in one pull. It uses vector similarity over your Readwise highlights to surface relevant passages. It uses a multi-hop traversal of :DEVELOPED_BY and :COMPETES_WITH edges to bring in Anthropic and Codex neighbors. Finally, it uses an :INITIATED_BY jump back to the prior conversation that discussed agent harnesses. There’s no cross-store join logic and no orchestrator.
From our tests, the library leaves the context construction to the user of the SDK. In other words, you get the whole output from the graph, and it’s your responsibility to further compress it before passing it to the LLM.
What’s Next
The neo4j-labs/agent-memory architecture is more complex than what this article covers, but this is the core idea behind it. I’ll cover other components in more depth in future articles, including designing the ontology and keeping your knowledge graph clean over time.
I think this open-source repository is a perfect blueprint you can take to build your own agent memory solution, even with Postgres or MongoDB, to avoid keeping multiple databases in production. Still, Neo4j is probably the best choice for data mining and exploration.
For small to medium-scale projects with thousands of nodes and short hop traversals, I’d probably build my own agent memory solution from scratch on top of Postgres or MongoDB. I’d reach for Neo4j as an internal tool within my organization, or when the scale or complexity becomes too large for Postgres or MongoDB.
But here is what I’m wondering:
How are you handling agent memory today? Flat files, a vector index, a knowledge graph, or something stranger?
Click the button below and tell me. I read every response.
Enjoyed the article? The most sincere compliment is to restack this for your readers.
Whenever you’re ready, here is how I can help you
If you want to go from zero to shipping production-grade AI agents, check out my Agentic AI Engineering course, built with Towards AI.
35 lessons. Three end-to-end portfolio projects. A certificate. And a Discord community with direct access to industry experts and me.
Built for software, data engineers or scientists transitioning into AI engineering.
Rated 5/5 by 300+ students. The first 7 lessons are free:
Not ready to commit? Start with our free Agentic AI Engineering Guide, a 6-day email course on the mistakes that silently break AI agents in production.
References
Seale, T. (n.d.). This week Anthropic dropped Claude Sonnet 4.5. LinkedIn. https://www.linkedin.com/posts/tonyseale_this-week-anthropic-dropped-claude-sonnet-activity-7379787334398926848-iVOE/
Monigatti, L. (n.d.). The Evolution From RAG to Agentic RAG to Agent Memory. Leonie Monigatti. https://www.leoniemonigatti.com/blog/from-rag-to-agent-memory.html
Neo4j Labs. (n.d.). Understanding the Three Memory Types. Neo4j Agent Memory. https://neo4j.com/labs/agent-memory/explanation/memory-types/
Neo4j Labs. (n.d.). Why Neo4j? Graph-Native Memory Architecture. Neo4j Agent Memory. https://neo4j.com/labs/agent-memory/explanation/graph-architecture/
Neo4j Labs. (n.d.). POLE+O Data Model. Neo4j Agent Memory. https://neo4j.com/labs/agent-memory/explanation/poleo-model/
Neo4j Labs. (n.d.). How Entity Extraction Works. Neo4j Agent Memory. https://neo4j.com/labs/agent-memory/explanation/extraction-pipeline/
Neo4j Labs. (n.d.). Entity Resolution and Deduplication. Neo4j Agent Memory. https://neo4j.com/labs/agent-memory/explanation/resolution-deduplication/
Images
If not otherwise stated, all images are created by the author.
“Reasoning memory is the novelty from this architecture. By storing past successful or failed thinking patterns into the memory, the agent can one-shot future similar requests or at least know not to repeat similar mistakes.”
this was really interesting. great real all around, i really enjoyed how deep you went in the weeds with this one. thanks.
Seeing the same compression happen at the small business AI level. Owners who understand even a loose mental model of the pipeline get dramatically better results with AI automation than those who just use the output. Which skill do you think becomes non-negotiable first in this merged role?