

Structured Outputs: The Silent Hero of Production AI
How to master LLM outputs for reliable AI systems

Welcome to the AI Agents Foundations series—a 9-part journey from Python developer to AI Engineer. Made by busy people. For busy people.
Everyone’s talking about AI agents. But what actually is an agent? When do we need them? How do they plan and use tools? How do we pick the correct AI tools and agentic architecture? …and most importantly, where do we even start?
To answer all these questions (and more!), We’ve started a 9-article straight-to-the-point series to build the skills and mental models to ship real AI agents in production.
We will write everything from scratch, jumping directly into the building blocks that will teach you “how to fish”.
What’s ahead:
Structured Outputs ← You are here
By the end, you’ll have a deep understanding of how to design agents that think, plan, and execute—and most importantly, how to integrate them in your AI apps without being overly reliant on any AI framework.
Let’s get started.
Opik: Open-Source LLMOps Platform (Sponsored)
This AI Agents Foundations series is brought to you by Opik - the LLMOps open-source platform that we keep returning to in all our open-source courses and real-world AI products. Why? Because it makes our AI products actually work in production.

Opik is the observability platform for AI engineers who need answers, not dashboards:
See every decision - Complete traces of LLM calls with costs and latency breakdown at each reasoning step
Catch issues fast - Automated AI Evals plugged into your production traces
Optimize your system - Run experiments using LLM judges, compare results and pick your best configuration
Stop manual prompt engineering - Agent Optimizer handles prompt optimization automatically
Opik is fully open-source and works with custom code or any agent framework. You can also use the managed version for free (w/ 25K spans/month on their generous free tier).
Structured Outputs
In a recent project I am working on, our production AI system crashed right before an important demo. Why? Because we were not using structured outputs consistently across our Large Language Model (LLM) workflows.
Our staging environment had been working fine with simple regex parsing of LLM responses, but when we deployed to production, everything fell apart. Our regex patterns failed to match slightly different response formats, data types were inconsistent, and downstream processes couldn’t handle the unpredictable data, causing cascading failures. When demo day arrived, our system was completely unusable.
The problem was clear: we had been relying on fragile string parsing, hoping the LLM would always respond in the exact same format. But in production, especially with AI systems, users will always enter inputs you never expect. Without structured outputs, we had no data validation, no type checking, and no real control over how the output should look. Just like lock files ensure consistent dependencies, structured outputs ensure consistent AI data contracts by defining the expected structure for LLM responses.
In our previous article from the AI Agents Foundations series, we explored the difference between workflows and agents. Now, we will tackle a fundamental challenge: getting reliable information out of an LLM.
To understand exactly what happens, we will first write everything from scratch and then move to using popular LLM APIs such as Gemini’s GenAI SDK:
From scratch using JSON
From scratch using Pydantic (We love Pydantic!)
Using the Gemini SDK and Pydantic
Understanding why structured outputs are important
Before we start coding, it is important to understand why structured outputs are foundational to building reliable AI applications. When an LLM returns a free-form string, you face the messy task of parsing it. This often involves fragile regular expressions or string-splitting logic that can easily break if the model outputs change slightly [1], [2]. Structured outputs solve this by forcing the model’s response into a predictable format like JSON or Pydantic.
This approach offers several key benefits. First, structured outputs are easy to parse and manipulate programmatically. Instead of wrestling with raw text, you work with clean Python objects, making your code more predictable and easier to debug. Using libraries like Pydantic adds a layer of data and type validation [3], [4]. If the LLM returns a string where an integer is expected, your application raises a clear validation error immediately, preventing bad data from propagating.
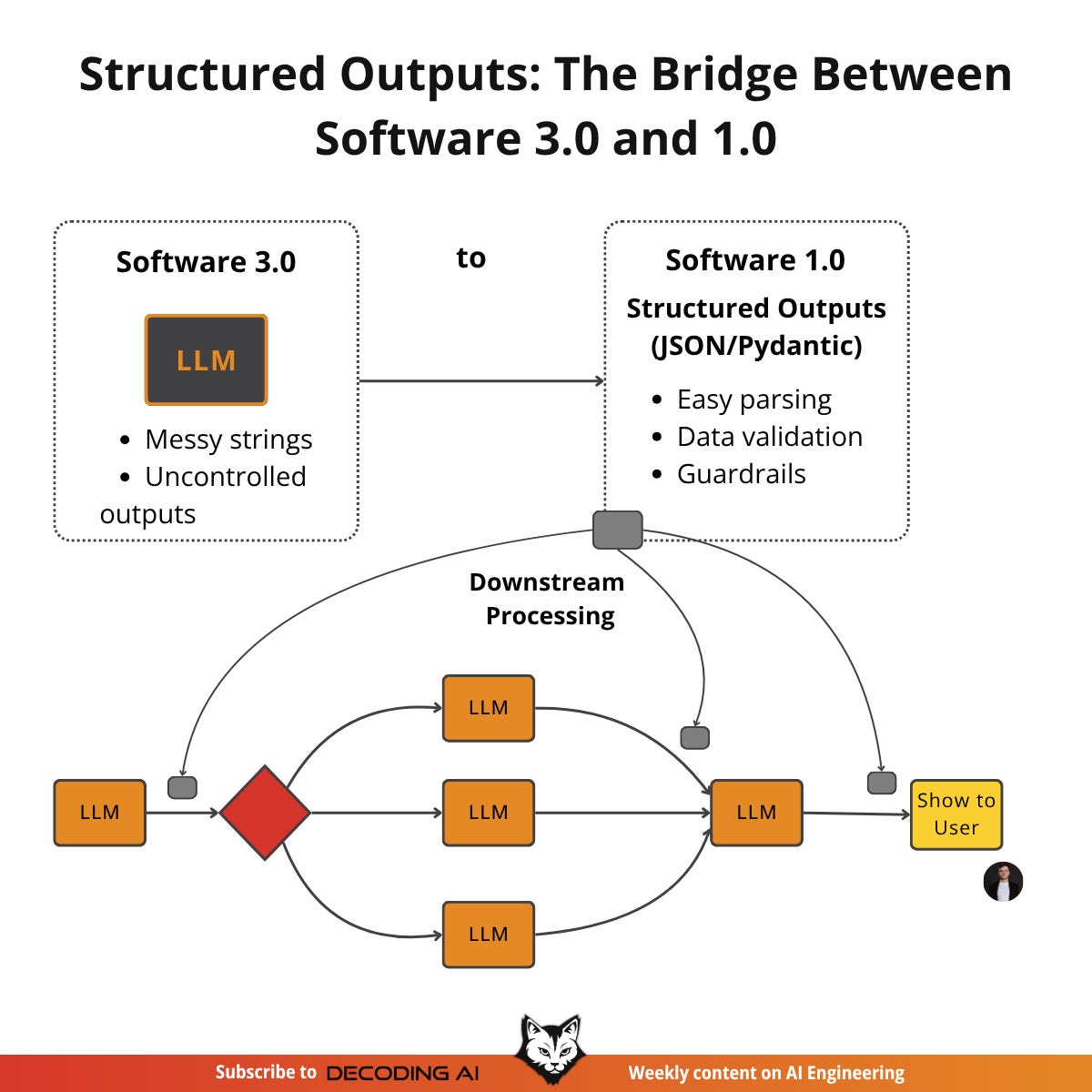
Furthermore, structured outputs are easier to orchestrate between steps in a workflow. When you know what information you have available, it is much simpler to pass it to the next LLM call or a downstream system like a database or API [5], [6]. This control also reduces costs. By ensuring the LLM generates only the necessary data without useless artifacts (e.g., “Here is the output you requested...”), you reduce the number of output tokens.
💡 Quick Tip: You can easily compute the costs of running your workflows or agent by plugging in an LLMOps open-source tool such as Opik.
Ultimately, structured outputs create a formal contract between the LLM (Software 3.0) and your application code (Software 1.0). They are the standard method for modeling domain objects in AI engineering, connecting the probabilistic nature of LLMs with deterministic code.
Implementing Structured Outputs From Scratch Using JSON
To understand how modern LLM APIs such as OpenAI and Gemini work under the hood, we will first implement structured outputs from scratch.
Our goal is to prompt a model to return a JSON object and then parse it into a Python dictionary. We will use an “LLM-as-judge” evaluation as our example, where we ask an LLM to compare a generated text against a ground-truth document and score it based on predefined criteria. This is a great use case, as it requires extracting specific, structured information from a large context.
First, we define our sample documents for the evaluation. These will serve as the input for our LLM judge:
GENERATED_DOCUMENT = “”“
# Q3 2023 Financial Performance Analysis
The Q3 earnings report shows a 20% increase in revenue and a 15% growth in user engagement,
beating market expectations. These impressive results reflect our successful product strategy
and strong market positioning.
Our core business segments demonstrated remarkable resilience, with digital services leading
the growth at 25% year-over-year. The expansion into new markets has proven particularly
successful, contributing to 30% of the total revenue increase.
Customer acquisition costs decreased by 10% while retention rates improved to 92%,
marking our best performance to date. These metrics, combined with our healthy cash flow
position, provide a strong foundation for continued growth into Q4 and beyond.
“”“
GROUND_TRUTH_DOCUMENT = “”“
# Q3 2023 Financial Performance Analysis
The Q3 earnings report shows a 18% increase in revenue and a 15% growth in user engagement,
slightly below market expectations. These results reflect our product strategy adjustments
and competitive market positioning challenges.
Our core business segments showed mixed performance, with digital services growing at
22% year-over-year. The expansion into new markets has been challenging, contributing
to only 15% of the total revenue increase.
Customer acquisition costs increased by 5% while retention rates remained at 88%,
indicating areas for improvement. These metrics, combined with our cash flow position,
suggest we need strategic adjustments for Q4 growth.
“”“Next, we craft a prompt that instructs the LLM to evaluate the generated document against the ground truth and format the output as JSON. We provide a clear example of the desired structure and use XML tags like
<document>to separate inputs from instructions. This is an effective prompt engineering technique for improving clarity and guiding the model’s output [7], [8]. The key is to be explicit about the format, keys, and value types you expect:
prompt = f”“”
You are an expert evaluator. Compare the generated document with the ground truth document and provide a score for each criterion.
The output must be a single, valid JSON object with the following structure:
{{
“scores”: [
{{
“criterion”: “revenue_forecast”,
“score”: 0 or 1,
“reason”: “Your reasoning here.”
}},
{{
“criterion”: “user_growth”,
“score”: 0 or 1,
“reason”: “Your reasoning here.”
}},
{{
“criterion”: “facts”,
“score”: 0 or 1,
“reason”: “Your reasoning here.”
}}
]
}}
Here are the documents:
<generated_document>
{GENERATED_DOCUMENT}
</generated_document>
<ground_truth_document>
{GROUND_TRUTH_DOCUMENT}
</ground_truth_document>
“”“We send the prompt to the model and inspect the raw response. As expected, the model returns a JSON object, wrapped in Markdown ```json code blocks:
from google import genai
client = genai.Client()
response = client.models.generate_content(model=”gemini-2.5-flash”, contents=prompt)It outputs:
```json
{
“scores”: [
{
“criterion”: “revenue_forecast”,
“score”: 0,
“reason”: “The generated document claims a 20% revenue increase, while the ground truth states an 18% increase, which is slightly below expectations. The forecast is factually incorrect.”
},
{
“criterion”: “user_growth”,
“score”: 1,
“reason”: “Both documents report a 15% growth in user engagement, so this fact is correctly stated in the generated document.”
},
{
“criterion”: “facts”,
“score”: 0,
“reason”: “The generated document contains several factual inaccuracies regarding revenue, market expansion contribution, customer acquisition costs, and retention rates when compared to the ground truth.”
}
]
}To handle this, we create a helper function to strip the Markdown tags, leaving a clean JSON string that can be safely parsed:
def extract_json_from_response(response: str) -> dict:
“”“
Extracts JSON from a response string that is wrapped in ```json tags.
“”“
response = response.replace(”```json”, “”).replace(”```”, “”)
return json.loads(response)Finally, we parse the string into a Python dictionary, which can now be used in our application:
parsed_response = extract_json_from_response(response.text)It outputs:
{
“scores”: [
{
“criterion”: “revenue_forecast”,
“score”: 0,
“reason”: “The generated document claims a 20% revenue increase, ...”
},
{
“criterion”: “user_growth”,
“score”: 1,
“reason”: “Both documents report a 15% growth in user engagement, ...”
},
{
“criterion”: “facts”,
“score”: 0,
“reason”: “The generated document contains several factual ...”
}
]
}This manual method works, but it relies on post-processing and lacks data validation. If the LLM makes a mistake like outputting a string instead of an integer or missing a dictionary key, our application will fail. Next, we will see how Pydantic provides a much more robust solution to this problem.
Implementing Structured Outputs From Scratch Using Pydantic
Forcing JSON output is an improvement, but it still leaves you with a plain Python dictionary. You cannot be sure what is inside it, whether the keys are correct, or if the values have the right type. This uncertainty can lead to bugs and make your code difficult to maintain.
Pydantic solves this problem. It is a data validation library that enforces structure and type hints at runtime, ensuring data integrity from the moment it enters your application [3]. It provides a single, clear definition for your data structure and can automatically generate a JSON Schema from your Python class.
💡 Quick Tip: I personally love Pydantic. I use it to model any data structure in my Python programs, completely dropping other options such as
@dataclassorTypedDict.
When an LLM produces output that does not match your Pydantic model, the library raises a ValidationError that clearly explains what went wrong. This “fail-fast” behavior is essential for building reliable systems, preventing bad data from moving through your application and causing hard-to-debug errors later. This is a major improvement over simple JSON parsing, as it introduces a validation layer that catches errors early.
We define our desired data structure as a Pydantic class, using standard Python type hints to define the expected type for each field:
from typing import Literal
from typing_extensions import Annotated
import pydantic
from pydantic import Ge, Le
class CriterionScore(pydantic.BaseModel):
“”“Model holding the score and reason for a specific criterion.”“”
criterion: Literal[”revenue_forecast”, “user_growth”, “facts”]
score: Annotated[int, Ge(0), Le(1)] = pydantic.Field(description=”Binary score of the section.”)
reason: str = pydantic.Field(description=”The reason for the given score.”)
class Scores(pydantic.BaseModel):
scores: list[CriterionScore]You can also nest Pydantic models to represent more complex, hierarchical data. This allows you to define intricate relationships between different pieces of information. However, it is good practice to keep schemas as simple as possible, as complex nested structures can confuse the LLM and lead to errors.
With our Pydantic model defined, we can automatically generate a JSON Schema from it. A schema is the standard for defining the structure and constraints of your data, acting as a formal contract between your application and the LLM. This contract dictates the expected fields, their types, and any validation rules. Now, instead of providing a fuzzy JSON that explains how our output should look (as we did in the previous section), we provide an explicit schema to the LLM that is compatible with Pydantic. This is similar to the technique used internally by APIs like Gemini and OpenAI to enforce a specific output format [9]:
schema = Scores.model_json_schema()The generated schema is detailed and includes descriptions from the
Fielddefinitions to guide the generation process.
{
“$defs”: {
“CriterionScore”: {
“properties”: {
“criterion”: {
“enum”: [”revenue_forecast”, “user_growth”, “facts”],
“title”: “Criterion”,
“type”: “string”
},
“score”: {
“description”: “Binary score of the section.”,
“exclusiveMaximum”: 1,
“exclusiveMinimum”: 0,
“title”: “Score”,
“type”: “integer”
},
“reason”: {
“description”: “The reason for the given score.”,
“title”: “Reason”,
“type”: “string”
}
},
“required”: [”criterion”, “score”, “reason”],
“title”: “CriterionScore”,
“type”: “object”
}
},
“properties”: {
“scores”: {
“items”: {
“$ref”: “#/$defs/CriterionScore”
},
“title”: “Scores”,
“type”: “array”
}
},
“required”: [”scores”],
“title”: “Scores”,
“type”: “object”
}We update our prompt to include this JSON Schema:
prompt = f”“”
Please analyze the following documents and extract evaluation scores.
The output must be a single, valid JSON object that conforms to the following JSON Schema:
{json.dumps(schema, indent=2)}
Here are the documents:
<generated_document>
{GENERATED_DOCUMENT}
</generated_document>
<ground_truth_document>
{GROUND_TRUTH_DOCUMENT}
</ground_truth_document>
“”“We call the model and extract the JSON string as before.
response = client.models.generate_content(model=MODEL_ID, contents=prompt)
parsed_response = extract_json_from_response(response.text)It outputs:
{
“scores”: [
{
“criterion”: “revenue_forecast”,
“score”: 0,
“reason”: “The generated document overstates revenue growth ...”
},
{
“criterion”: “user_growth”,
“score”: 1,
“reason”: “The 15% user engagement growth is correctly reported ....”
},
{
“criterion”: “facts”,
“score”: 0,
“reason”: “The generated document contains multiple factual ....”
}
]
}But now, the biggest difference, is that we can load the output dictionary into our Pydantic model and validate it:
try:
scores = Scores.model_validate(parsed_response)
print(”Validation successful!”)
except Exception as e:
print(f”Validation failed!”)It outputs:
Validation successful!The scores Pydantic object can now be safely used throughout your application. This is the main advantage: you move from unclear dictionaries to clean, predictable Python objects.
While Python’s built-in dataclasses or TypedDict can define structure, they only provide type hints for static analysis and do not perform runtime validation [3], [4]. If the LLM returns a string where an integer is expected, these tools will not catch the error.
To conclude, Pydantic’s runtime validation, type constraints, and clear schema definitions make it our favorite way for structuring and validating all our domain data structures from our AI apps.
Implementing Structured Outputs Using Gemini and Pydantic
While Pydantic brings structure and validation, we still had to construct the prompts and handle responses manually. When working with modern APIs such as Gemini and OpenAI, the recommended way to generate structured outputs is by using their native features. This approach is simpler, more accurate, and often more cost-effective than manual prompt engineering, as the vendor will always handle the optimization on top of their models better than your manual prompting [9], [10], [11].
Let’s see how to achieve the same result for our LLM-as-judge example using the Gemini API’s native capabilities. The process becomes much simpler.
We define a
GenerateContentConfigobject, instructing the Gemini API to set theresponse_mime_typeto“application/json”and theresponse_schemato ourScoresPydantic model. This configures the model to output JSON that is then automatically converted to the given Pydantic model. This single configuration step replaces the manual schema injection and parsing we did earlier:
from google.genai import types
config = types.GenerateContentConfig(
response_mime_type=”application/json”,
response_schema=Scores
)This configuration makes our prompt significantly shorter and cleaner, eliminating the need to manually inject any type of schema. We simply ask the model to perform the task, as the output format is guided directly by the config:
prompt = f”“”
You are an expert evaluator. Compare the generated document with the ground truth document and provide a score for each criterion.
Here are the documents:
<generated_document>
{GENERATED_DOCUMENT}
</generated_document>
<ground_truth_document>
{GROUND_TRUTH_DOCUMENT}
</ground_truth_document>
“”“Now, we call the model, passing our simplified prompt and the new configuration object. The API handles the rest, ensuring the output adheres to the schema.
response = client.models.generate_content(
model=MODEL_ID,
contents=prompt,
config=config
)The Gemini client automatically parses the output for us. By accessing the
response.parsedattribute, we receive a ready-to-use instance of ourScoresPydantic model:
scores = response.parsed
print(f”Type of the response: `{type(scores)}`”)It outputs:
Type of the response: `<class ‘__main__.Scores’>`Similar patterns apply to all modern LLM APIs.
This native approach is robust, efficient, and requires less code. While it is the recommended way for closed-source APIs or AI frameworks, the “from scratch” method remains useful for open-source models that may not have this built-in functionality or when you do not have access to any AI framework.
The Best Model for Structured Outputs
A final thought on what’s the best model for structured outputs: In general, all the latest LLMs support generating JSON, indirectly supporting Pydantic structures.
However, when building AI systems, there is never the problem of what’s the best model, but what’s the best model for your given use case. Almost always, you cannot tell which model is better until you actually test them. That’s why, when building AI systems, you should ALWAYS adopt a scientific method to find the optimal model (and its configuration):
Configure different parameters (e.g., different models).
Run experiments for each configuration.
Compute business metrics of interest (e.g., using an LLM-as-judge).
Use an LLMOps tool such as Opik to analyze the results.
Pick the best configuration and iterate if needed.

This high-level strategy works for tweaking any model, config or even feature of an AI system.
Structured Outputs Are Everywhere
The thing is that structured outputs are everywhere! They are a fundamental pattern in AI engineering, connecting the probabilistic nature of LLMs with the deterministic world of software. Whether you are building a simple summarization workflow or a complex research agent, you will use structured outputs to ensure reliability and control.
Remember that this article is part of a longer series of 9 pieces on the AI Agents Foundations that will give you the tools to morph from a Python developer to an AI Engineer.
Here’s our roadmap:
Structured Outputs ← You just finished this one.
The 5 Workflow Patterns ← Move to this one.
See you next week.
What’s your take on today’s topic? Do you agree, disagree, or is there something I missed?
If you enjoyed this article, the ultimate compliment is to share our work.
Whenever you’re ready, here is how I can help you
Go from agent user to agent builder. Master the foundations of AI agents and turn fragile demo code into reliable, production-ready systems with my course, Agent Engineering: Building Multi-Agent Systems (made with Towards AI).
35 lessons. Pure foundations from scratch. 4 mini-projects. 2 production systems. A certificate and direct access to me & industry experts in our Discord.
Built for software and data professionals transitioning into AI engineering. Rated 5/5 with 300+ students. The first 7 lessons are free:
Not ready to commit? Start with our free Agent AI Engineering Guide, a 6-day email course on the mistakes that silently break AI agents in production.
Thanks again to Opik for sponsoring the series and keeping it free!

If you want to monitor, evaluate and optimize your AI workflows and agents:
References
Ntinopoulos, V., Biefer, H. R. C., Tudorache, I., Papadopoulos, N., Odavic, D., Risteski, P., Haeussler, A., & Dzemali, O. (2024). Large language models for data extraction from unstructured and semi-structured electronic health records: a multiple model performance evaluation. BMJ Health & Care Informatics, 32(1), e101139. https://pmc.ncbi.nlm.nih.gov/articles/PMC11751965/
(n.d.). Evaluation of LLM-based Strategies for the Extraction of Food Product Information from Online Shops. arXiv. https://arxiv.org/html/2506.21585v1
Speakeasy Team. (2024, August 29). Type Safety in Python: Pydantic vs. Data Classes vs. Annotations vs. TypedDicts. Speakeasy. https://www.speakeasy.com/blog/pydantic-vs-dataclasses
(n.d.). Validators approach in Python - Pydantic vs. Dataclasses. Codetain. https://codetain.com/blog/validators-approach-in-python-pydantic-vs-dataclasses/
(n.d.). Automating Knowledge Graphs with LLM Outputs. Prompts.ai. https://www.prompts.ai/en/blog-details/automating-knowledge-graphs-with-llm-outputs
Kelly, C. (2024, February 13). Structured Outputs: everything you should know. Humanloop. https://humanloop.com/blog/structured-outputs
(2024, June 26). Structured data response with Amazon Bedrock: Prompt Engineering and Tool Use. Amazon Web Services. https://aws.amazon.com/blogs/machine-learning/structured-data-response-with-amazon-bedrock-prompt-engineering-and-tool-use/
(n.d.). Best practices for prompt engineering with the OpenAI API. OpenAI Help Center. https://help.openai.com/en/articles/6654000-best-practices-for-prompt-engineering-with-the-openai-api
(n.d.). Structured output. Google AI for Developers. https://ai.google.dev/gemini-api/docs/structured-output
Sharma, A. (2024, October 10). When should I use function calling, structured outputs or JSON mode? Vellum AI Blog. https://www.vellum.ai/blog/when-should-i-use-function-calling-structured-outputs-or-json-mode
(n.d.). Structured Output in vertexAI BatchPredictionJob. Google Cloud Community. https://www.googlecloudcommunity.com/gc/AI-ML/Structured-Output-in-vertexAI-BatchPredictionJob/m-p/866640
Images
If not otherwise stated, all images are created by the author.
Great post! Structured outputs are so important. What do you think about Pydantic AI?
Graceful culmination of technology advancement and services industry for the good 😊