

Tool Calling From Scratch to Production: The Complete Guide
Master the fundamentals through a deep research agent to learn to properly implement, use, and debug tools in any AI system.

Welcome to the AI Agents Foundations series—a 9-part journey from Python developer to AI Engineer. Made by busy people. For busy people.
Everyone’s talking about AI agents. But what actually is an agent? When do we need them? How do they plan and use tools? How do we pick the correct AI tools and agentic architecture? …and most importantly, where do we even start?
To answer all these questions (and more!), We’ve started a 9-article straight-to-the-point series to build the skills and mental models to ship real AI agents in production.
We will write everything from scratch, jumping directly into the building blocks that will teach you “how to fish”.
What’s ahead:
Tool Calling From Scratch ← You are here
By the end, you’ll have a deep understanding of how to design agents that think, plan, and execute—and most importantly, how to integrate them in your AI apps without being overly reliant on any AI framework.
Let’s get started.
Opik: Open-Source LLMOps Platform (Sponsored)
This AI Agents Foundations series is brought to you by Opik - the LLMOps open-source platform used by Uber, Etsy, Netflix and more.
But most importantly, we are incredibly grateful to be supported by a tool that we personally love and keep returning to for all our open-source courses and real-world AI products. Why? Because it makes escaping the PoC purgatory possible!

Here is how Opik helps us ship AI workflows and agents to production:
We see everything - Visualize complete traces of LLM calls with costs and latency breakdown at each reasoning step.
Easily optimize our system - Measure our performance using custom LLM judges, run experiments, compare results and pick the best configuration.
Catch issues fast - Plug in the LLM Judge metrics into the production traces and get on-demand alarms.
Stop manual prompt engineering - Their prompt versioning and optimization features allow us to track and improve our system automatically. The future of AutoAI.
Opik is fully open-source and works with custom code or most AI frameworks. You can also use the managed version for free (w/ 25K spans/month on their generous free tier).
Writing Tool Calls From Scratch
Often, we use frameworks like LangGraph or AgentSDK to implement tools, hook up to smart MCP servers and ultimately use APIs like Gemini or OpenAI to call them.
But how do tools actually work under the hood? That’s a fundamental question to answer to be able to optimize agents to use tools exactly how we want. To understand how to properly define tools, how many tools to give to your agent to avoid tool confusion and what types of tools are even worth using. To answer these questions, the best approach is to build tool calling from scratch.
Recently, while building Nova, the research agent as one of the projects for the AI agents course I’m teaching with Towards AI, I ran into a frustrating problem. The agent could produce impressive research queries to call the Perplexity API, but it wasn’t flexible enough to gather context outside of that, such as YouTube transcripts, GitHub repositories or random sites. I needed this context to properly guide the research.
Thus, I realized it’s time to plug in specialized tools to pull these data sources. Then, based on the user input, before starting doing Perplexity queries, to specialize my context, the agent understood what GitHub repositories or what YouTube transcripts to pull.
The idea is that even the smartest LLM is ultimately just a sophisticated text generator. That’s why current chatbot applications such as ChatGPT or Gemini are limited by how you can provide them the proper context. Ultimately, most vertical AI applications solve this particular problem. They integrate with the right tools to provide you the right context, at the right time. Tools sit as the cornerstone of this transition.
In this article, we will first explain in more depth why LLMs need tools. Then, we will implement tool definition and calling from scratch before showing how to achieve the same result with a production API like Gemini. Finally, we will build an intuition on the most essential tool categories you need to know to build your own agents.
So… Let’s start with a better understanding of why tools are so important.
Why Agents Need Tools
LLMs have a fundamental limitation: they are trained on static datasets and cannot update their knowledge or interact with the external world on their own [1], [2]. Their knowledge is fixed at the time of training, which means they are disconnected from real-time information and cannot perform actions beyond generating text [3]. To bridge this gap, we need strategies such as Retrieval-Augmented Generation (RAG) or other memory techniques. But all require one essential component: tools.
Now let’s see how this relates to agents.
In any agentic system, we have two core components: the agent and the environment. The agent uses its internal knowledge to take actions in the environment, interprets the output from those actions, updates its state, and then decides on the next action. Tools are the mechanism that allows the agent to “see” what’s happening in the environment or take actions within it. The LLM acts as the brain, while the tools are its “hands and senses,” allowing it to perceive and act in the world.
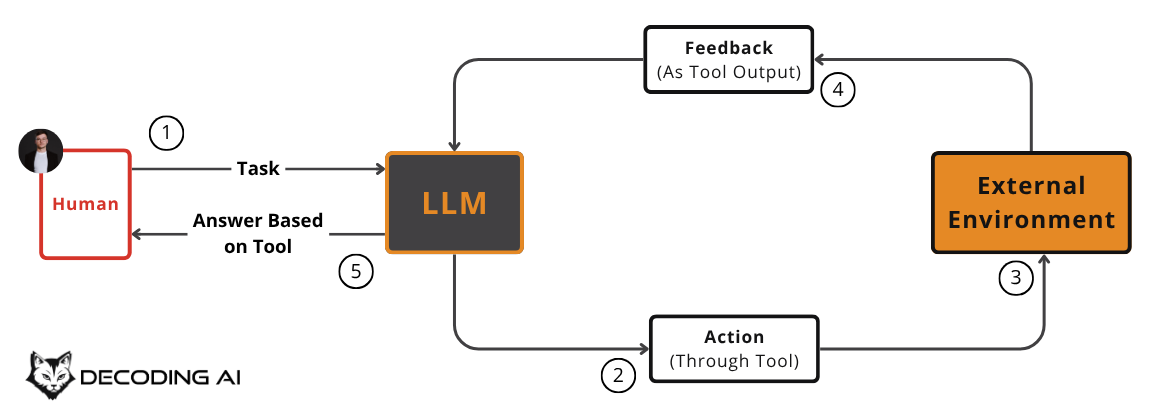
Most tools can be broadly categorized into two buckets:
Accessing External Information (Read Actions): These tools allow an agent to gather information to pass into its context window. This includes accessing real-time data through APIs (e.g., weather, news) or querying databases (e.g., PostgreSQL, Snowflake). These are often present when implementing RAG or the memory layer in general [4], [5].
Taking Actions (Write Actions): These tools give the agent the ability to affect the external world. This can involve executing code, sending emails, creating calendar events, or writing to a database. These actions carry more risk and must be handled with care as their actions are often irreversible [6], [7].
Implementing Tool Calls From Scratch
The best way to understand how tools work is to implement them yourself. We will build a simple framework to see how a tool is defined, how an LLM discovers it, and how the entire call-and-response cycle works.
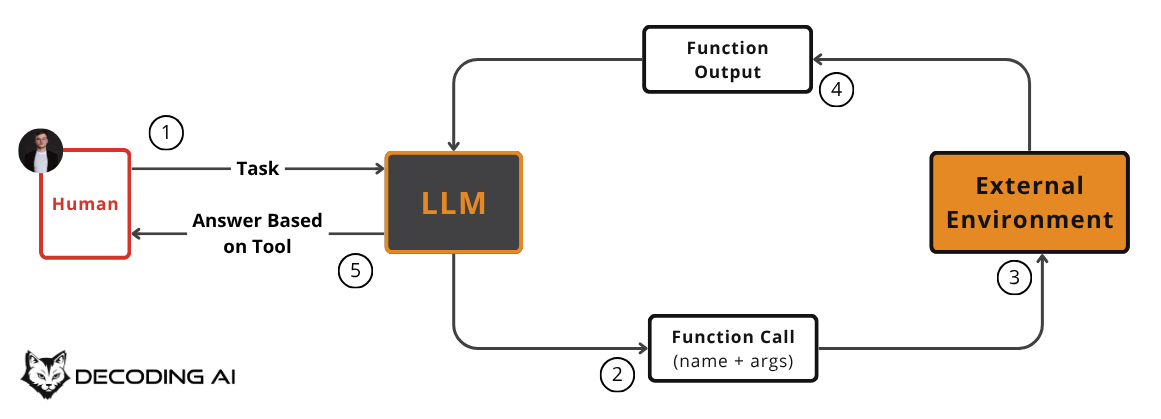
The high-level process of calling a tool involves five steps [8]:
You: Send the LLM your task, a prompt and a list of available tools with their definitions (schemas).
LLM: Responds with a
function_callrequest, specifying the tool’s name and the arguments to use.You: Parse this request and execute the corresponding function in your code.
You: Send the function’s output back to the LLM as a new message.
LLM: Uses the tool’s output to generate a final, user-facing response.
As seen in Image 3, actions are mapped to function calls, while the feedback from the environment is mapped to function outputs.
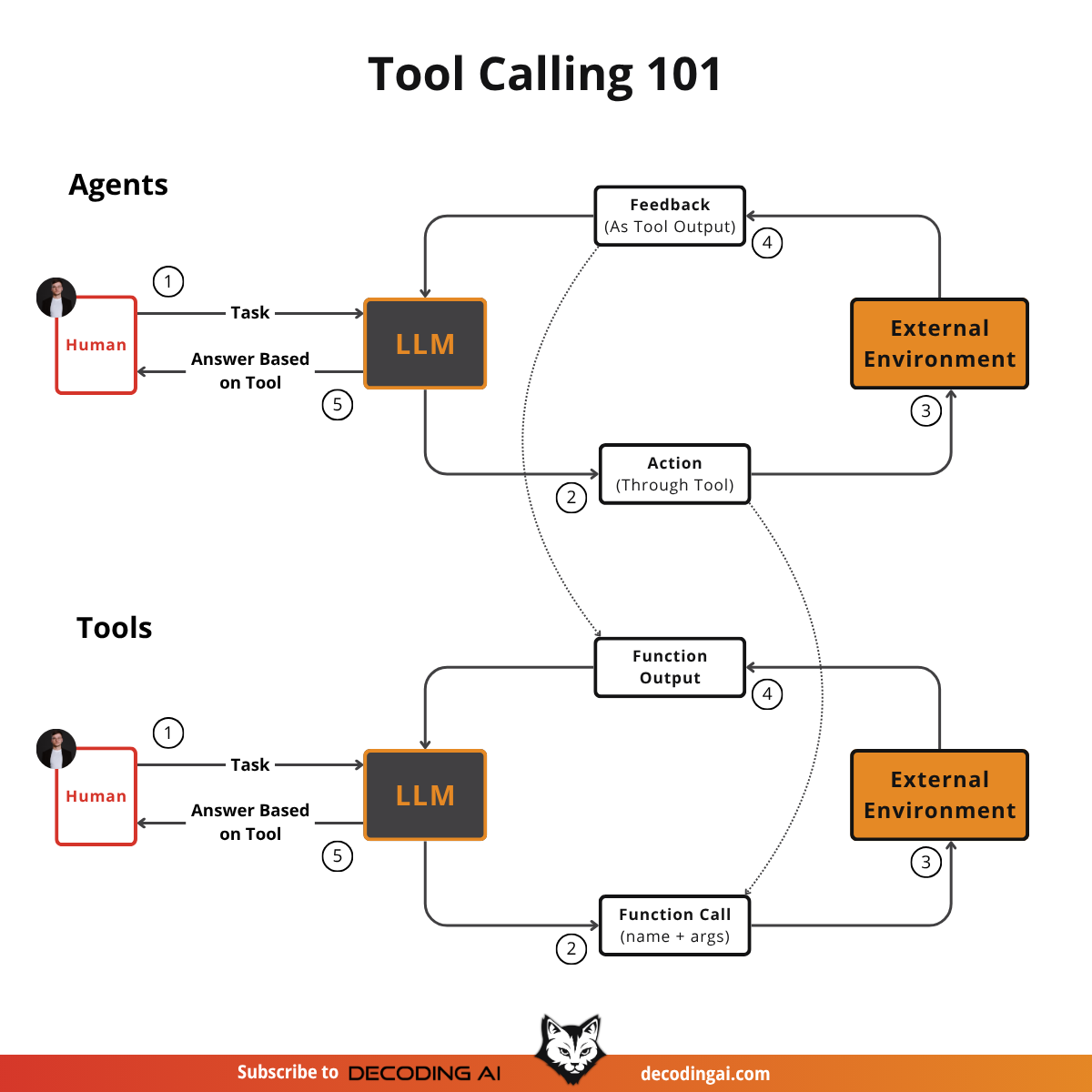
This request-execute-respond flow is the foundation of tool use in AI agents.
Now, let’s implement this flow. We will define some mocked tools for our research agent use case: google_search, perplexity_search, and scrape_url.
First, we define our mock Python functions. The function signature and docstrings are important, as they provide the information the LLM will use to understand what each tool does.
def google_search(query: str) -> dict:
“”“
Tool used to perform Google web searches and return ranked results.
Args:
query (str): The search query.
Returns:
dict: A dictionary of search results.
“”“
return {”results”: “https://example.com/random/url”}
def perplexity_search(query: str) -> dict:
“”“
Tool used to perform AI-powered Perplexity searches with source citations.
Args:
query (str): The search query.
Returns:
dict: A dictionary with an AI-generated answer and sources.
“”“
return {”answer”: f”Mock Perplexity answer for: {query}”, “sources”: []}
def scrape_url(url: str) -> str:
“”“
Tool used to scrape and clean HTML content from a web URL.
Args:
url (str): The URL to scrape.
Returns:
str: The cleaned text content of the page.
“”“
return f”Mock scraped content from: {url}”Next, we define a JSON schema for each tool. This schema tells the LLM the tool’s
name,description, andparameters. This is the industry-standard format used by APIs from OpenAI, Google, and others [9].
google_search_schema = {
“name”: “google_search”,
“description”: “Tool used to perform Google web searches and return ranked results.”,
“parameters”: {
“type”: “object”,
“properties”: {
“query”: {
“type”: “string”,
“description”: “The search query.”,
}
},
“required”: [”query”],
},
}
perplexity_search_schema = {
“name”: “perplexity_search”,
“description”: “Tool used to perform AI-powered Perplexity searches with source citations.”,
“parameters”: {
“type”: “object”,
“properties”: {
“query”: {
“type”: “string”,
“description”: “The search query.”,
}
},
“required”: [”query”],
},
}
scrape_url_schema = {
“name”: “scrape_url”,
“description”: “Tool used to scrape and clean HTML content from a web URL.”,
“parameters”: {
“type”: “object”,
“properties”: {
“url”: {
“type”: “string”,
“description”: “The URL to scrape.”,
}
},
“required”: [”url”],
},
}We create a tool registry to map tool names to their handlers and schemas.
TOOLS = {
“google_search”: {
“handler”: google_search,
“declaration”: google_search_schema,
},
“perplexity_search”: {
“handler”: perplexity_search,
“declaration”: perplexity_search_schema,
},
“scrape_url”: {
“handler”: scrape_url,
“declaration”: scrape_url_schema,
},
}
TOOLS_BY_NAME = {tool_name: tool[”handler”] for tool_name, tool in TOOLS.items()}
TOOLS_SCHEMA = [tool[”declaration”] for tool in TOOLS.values()]The TOOLS_BY_NAME mapping looks like this:
{’google_search’: <function google_search at 0x...>, ‘perplexity_search’: <function perplexity_search at 0x...>, ‘scrape_url’: <function scrape_url at 0x...>}And here is an example schema from TOOLS_SCHEMA:
{
“name”: “google_search”,
“description”: “Tool used to perform Google web searches and return ranked results.”,
“parameters”: {
“type”: “object”,
“properties”: {
“query”: {
“type”: “string”,
“description”: “The search query.”
}
},
“required”: [
“query”
]
}
}Now, we create a system prompt to instruct the LLM on how to use these tools. This prompt includes usage guidelines and the schemas of all available tools.
TOOL_CALLING_SYSTEM_PROMPT = “”“
You are a helpful AI assistant with access to tools.
## Tool Usage Guidelines
- When you need to perform actions or retrieve information, choose the most appropriate tool.
- Choose different tools based on their descriptions.
- Provide all required parameters with accurate values.
## Tool Call Format
When you need to use a tool, output ONLY the tool call in this exact format:
<tool_call>
{{”name”: “tool_name”, “args”: {{”param1”: “value1”}}}}
</tool_call>
## Available Tools
<tool_definitions>
{tools}
</tool_definitions>
“”“The LLM, which has been instruction-tuned for function calling, uses the
descriptionfield in the schema to decide which tool is appropriate for a user’s query. This is why clear and distinct tool descriptions are essential. For example,Tool used to perform Google web searchesis much better thanTool used to find information, as it prevents confusion with other search tools. The model then generates the function name and arguments as a structured JSON output.Let’s test it. We send a user prompt along with our system prompt to the model.
from google import genai
client = genai.Client()
USER_PROMPT = “Use Google Search to find recent articles about AI agents.”
messages = [TOOL_CALLING_SYSTEM_PROMPT.format(tools=str(TOOLS_SCHEMA)), USER_PROMPT]
response = client.generate_content(
model=”gemini-2.5-flash”,
contents=messages,
)The LLM correctly identifies the google_search tool and generates the required arguments:
<tool_call>
{”name”: “google_search”, “args”: {”query”: “recent articles about AI agents”}}
</tool_call>Let’s try a more complex query that implies a sequence of actions.
USER_PROMPT = “Use Google Search to find the latest news on AI agents, then scrape the top result.”
messages = [TOOL_CALLING_SYSTEM_PROMPT.format(tools=str(TOOLS_SCHEMA)), USER_PROMPT]
response = client.generate_content(
model=”gemini-2.5-flash”,
contents=messages,
)The model correctly identifies the first step and calls the appropriate tool:
<tool_call>
{”name”: “google_search”, “args”: {”query”: “latest news on AI agents”}}
</tool_call>To move on to the scraping tool, which we expect based on the user prompt, we first have to execute the Google Search tool.
To do that, we create a helper function to extract the JSON string and another to handle the entire tool call process.
def extract_tool_call(response_text: str) -> str:
“”“Extracts the tool call JSON from the response text.”“”
return response_text.split(”<tool_call>”)[1].split(”</tool_call>”)[0].strip()
def call_tool(response_text: str, tools_by_name: dict):
“”“Parses the LLM response and executes the requested tool.”“”
tool_call_str = extract_tool_call(response_text)
tool_call = json.loads(tool_call_str)
tool_name = tool_call[”name”]
tool_args = tool_call[”args”]
tool_handler = tools_by_name[tool_name]
return tool_handler(**tool_args)
tool_result = call_tool(response.text, tools_by_name=TOOLS_BY_NAME)The tool_result is the output from our mock google_search function:
{”results”: “https://example.com/random/url”}Now, we send this result back to the LLM so it can decide on the next action. Remember, our original query was to search AND scrape the top result.
messages.append(f”Tool result from google_search: {json.dumps(tool_result, indent=2)}”)
response = client.generate_content(
model=”gemini-2.5-flash”,
contents=messages,
)The LLM recognizes that it needs to complete the second part of the task and calls the scraping tool:
<tool_call>
{”name”: “scrape_url”, “args”: {”url”: “https://example.com/random/url”}}
</tool_call>We execute the scraping tool using the same helper function and send the final result back to the LLM.
tool_result = call_tool(response.text, tools_by_name=TOOLS_BY_NAME)
# The tool_result would be something like:
# {’content’: ‘Mock scraped content from: https://example.com/random/url’}
# Send the final tool result back to the LLM
messages.append(f”Create a summary of all the scraped articles: {json.dumps(tool_result, indent=2)}”)
response = client.generate_content(
model=”gemini-2.5-flash”,
contents=messages,
)The LLM now provides a comprehensive final response synthesizing the scraped article.
I found the latest news on AI agents and scraped the top result...You could further start optimizing this code by writing a decorator that automatically translates a function’s signature and docs to its schema to avoid manually copying anything. This is what happens when you see @tool decorators from frameworks such as LangGraph. The decorator would look something like this:
import inspect
TOOLS_SCHEMA = []
TOOLS_BY_NAME = {}
def tool(func):
“”“Decorator that automatically registers a function as a tool.”“”
signature = inspect.signature(func)
# Generate schema from function
schema = {
“name”: func.__name__,
“description”: func.__doc__.strip() if func.__doc__ else “”,
“parameters”: {}
}
# Extract parameters from function signature
for param_name, param in signature.parameters.items():
param_type = param.annotation.__name__ if param.annotation != inspect.Parameter.empty else “string”
schema[”parameters”][param_name] = {”type”: param_type}
# Register the tool
TOOLS_SCHEMA.append(schema)
TOOLS_BY_NAME[func.__name__] = func
return funcNow simply decorate your functions to populate your TOOLS_SCHEMA and TOOLS_BY_NAME registries:
@tool
def google_search(query: str) -> dict:
“”“Searches Google for the given query.”“”
return {”results”: “https://example.com/random/url”}
@tool
def scrape_url(url: str) -> dict:
“”“Scrapes content from a given URL.”“”
return {”content”: f”Mock scraped content from: {url}”}But as you can see, the underlying mechanism is the same: the function’s signature and docstring are used to generate an input schema for the LLM [11]. It’s not fancy, but that’s the most important thing you should care about when defining tools. It sits at the core of making sure the LLM doesn’t confuse tools with each other and knows which tool to pick when.
You can intuitively see it as the “system prompt” of the tool.
This manual process reveals the core mechanics of tool calling. However, we want to avoid manually keeping track of function schemas or complex tool calling system prompts. Thus, for production systems, modern APIs offer a much simpler and more robust approach.
Implementing Production-Level Tool Calls
Modern LLM APIs like Google’s Gemini allow you to declare tools directly in the API call. This is more efficient, modern and reliable, as the only thing you should care about is defining well-documented functions.
Also, because you don’t have to define the schemas or write the tool calling system prompt yourself, the provider always takes care of optimizing them for every specific model. If you want to do it yourself, for example, with open-source models, it can quickly become a big burden.
Let’s see how to achieve the same result using Gemini’s native tool-calling capabilities.
The
google-genaiPython SDK can automatically generate the required schema from a Python function’s signature, type hints, and docstring. We can pass our functions directly to theGenerateContentConfigobject.
from google.genai import types
config = types.GenerateContentConfig(
tools=[google_search, perplexity_search, scrape_url]
)This single step replaces all the manual schema definition and prompt engineering we did before.
With the configuration defined, our prompt becomes much simpler. We no longer need to provide tool-usage guidelines or schemas.
USER_PROMPT = “Use Google Search to find recent articles about AI agents.”
response = client.generate_content(
model=”gemini-2.5-flash”,
contents=USER_PROMPT,
generation_config=config,
)The Gemini client automatically parses the output. The
response.candidates[0].content.parts[0]contains afunction_callobject with the tool name and arguments.
function_call = response.candidates[0].content.parts[0].function_callThis object contains everything we need:
name: “google_search”
args: {”query”: “recent articles about AI agents”}We can then create a simplified
call_toolfunction to execute the call.
def call_tool(function_call) -> any:
tool_name = function_call.name
tool_args = {key: value for key, value in function_call.args.items()}
tool_handler = TOOLS_BY_NAME[tool_name]
return tool_handler(**tool_args)
tool_result = call_tool(function_call)The output is the same as our manual implementation. By leveraging the native SDK, we reduced dozens of lines of code to just a few, creating a more robust and maintainable system. Other popular APIs from OpenAI and Anthropic follow a similar logic, making these concepts easily transferable [10].
In production, your agents often don’t call one or two tools, but 10, 20 or up to hundreds, depending on the use case. That’s why you need LLMOps tools, such as Opik, where you can easily monitor all the tool calls made by your agent. This includes tracking latency, token usage, cost, the model used to trigger the tool, and the inputs and outputs for each call. This visibility is essential for debugging and optimization.
In the video below, you can see how Opik helps us easily monitor a trace with over 100 steps using our full-fledged research agent, Nova.
💡 Tip: LLMOps platforms, such as Opik, can also help you A/B test different configurations of your AI app by running and comparing multiple experiments. This allows you to find the best model (e.g., GPT-4 vs. Claude vs. Gemini), hyperparameters or prompts for your use case while balancing accuracy, speed, and cost.
As the cherry on top, using Opik, you can even use their Agent Optimization feature to automatically refine your prompts or tool schemas to maximize your business metrics. For people who come from DS/ML/DL, this is similar to hyperoptimization tuning using tools such as Optuna, but for your prompts instead of hyperparameters.
The Popular Tools You Need to Know
Now that you understand how tools work, what kinds of tools are most common in production agents? They generally fall into two categories.
1) Tools that Access External Information (Read Actions):
Knowledge & Memory Access: These tools are the foundation of Retrieval-Augmented Generation (RAG). They query vector databases, document stores, or graph databases to fetch relevant context for the agent [14], [15]. We will explore memory in more depth in future articles of this series.
Web Search & Browsing: Essential for chatbots and research agents, these tools connect to search APIs like Google, Bing, or Perplexity to access up-to-date information from the internet [16], [17]. Similar to our mocked examples.
Database Queries: Text-to-SQL tools translate natural language questions into SQL or NoSQL queries to retrieve data from structured databases [18].
Knowledge Graph Queries: Tools like GraphRAG access knowledge graphs to uncover relationships between entities, which helps the agent better understand a query and refine its context.
File System Reads: These tools allow an agent to read local files and list directories, giving it access to its immediate environment. These are often used in coding agents like Claude Code to retrieve the right files using
grepcommands.
2) Tools that Take Actions (Write Actions):
Code Execution: A Python or JavaScript interpreter lets an agent write and run code in a sandboxed environment. This is invaluable for calculations, data manipulation, and visualization. However, it introduces significant security risks like arbitrary code execution and resource exhaustion, requiring robust sandboxing strategies like using Docker containers or gVisor [19], [20].
External API Actions: Common in enterprise AI, these tools interact with external services to send emails, schedule meetings, or create tasks in project management systems [21].
Database Writes: These tools allow an agent to insert, update, or delete records in a database.
File System Writes: Used in productivity apps, these tools can create, modify, or delete files on a local system.
⚠️ Always think twice before implementing any write actions, as these are often irreversible. For example, while I was running Claude Code over my Obsidian Second Brain it overwrote some of my beloved notes without having a way to access them back.
Conclusion
Tool calling is at the core of what makes an AI agent useful. Understanding how to build, monitor, and debug tool interactions is one of the most important skills for an AI Engineer. By giving an LLM the ability to interact with the outside world, you transform it from a passive text generator into an active problem-solver.
Interestingly, tools are not just for agents. They are a fundamental pattern that can also power structured workflows. In the orchestrator-worker pattern, you can leverage the current tool infrastructure provided by all the AI frameworks or MCP servers to generate tool calls that can be executed in parallel later on in your code as you see fit. Ultimately, you should not be limited by labels. Your imagination is the only constraint.
Remember that this article is part of a longer series of 9 pieces on the AI Agents Foundations that will give you the tools to morph from a Python developer to an AI Engineer.
Here’s our roadmap:
Tool Calling From Scratch ← You just finished this one.
Planning: ReAct & Plan-and-Execute ← Move to this one
See you next week.
What’s your take on today’s topic? Do you agree, disagree, or is there something I missed?
If you enjoyed this article, the ultimate compliment is to share our work.
Go Deeper
Everything you learned in this article, from building evals datasets to evaluators, comes from the AI Evals & Observability module of our Agentic AI Engineering self-paced course.
Your path to agentic AI for production. Built in partnership with Towards AI.
Across 34 lessons (articles, videos, and a lot of code), you’ll design, build, evaluate, and deploy production-grade AI agents end to end. By the final lesson, you’ll have built a multi-agent system that orchestrates Nova (a deep research agent) and Brown (a full writing workflow), plus a capstone project where you apply everything on your own.
Three portfolio projects and a certificate to show off in interviews. Plus a Discord community where you have direct access to other industry experts and me.
Rated 4.9/5 ⭐️ by 190+ early students — “Every AI Engineer needs a course like this.”
Not ready to commit? We also prepared a free 6-day email course to reveal the 6 critical mistakes that silently destroy agentic systems. Get the free email course.
Thanks again to Opik for sponsoring the series and keeping it free!

If you want to monitor, evaluate and optimize your AI workflows and agents:
References
(n.d.). LLM Limitations You Need to Know. ProjectPro. https://www.projectpro.io/article/llm-limitations/1045
(n.d.). Large Language Models (LLMs), Planetary-Scale Realtime Data & Current Limitations. The GDELT Project. https://blog.gdeltproject.org/large-language-models-llms-planetary-scale-realtime-data-current-limitations/
(n.d.). Efficient Tool Use with Chain-of-Abstraction Reasoning. arXiv. https://arxiv.org/html/2412.04503v1
(n.d.). Guide to Integrating Tools and APIs with Language Models. Mercity.ai. https://www.mercity.ai/blog-post/guide-to-integrating-tools-and-apis-with-language-models
(n.d.). LLM Agents Explained: A Complete Guide in 2025. DynamiQ. https://www.getdynamiq.ai/post/llm-agents-explained-complete-guide-in-2025
(n.d.). LLM Integration: A Guide to Connecting LLMs with External Resources & APIs. Mirascope. https://mirascope.com/blog/llm-integration
(n.d.). Guide to Integrating Tools and APIs with Language Models. Mercity.ai. https://www.mercity.ai/blog-post/guide-to-integrating-tools-and-apis-with-language-models
(n.d.). How-to: Function calling. LangChain. https://python.langchain.com/docs/how_to/function_calling/
(n.d.). Function Calling. Prompting Guide. https://www.promptingguide.ai/applications/function_calling
(n.d.). Function calling. OpenAI. https://platform.openai.com/docs/guides/function-calling
(n.d.). Tools. LangChain. https://python.langchain.com/docs/concepts/tools/
(n.d.). Enforce and validate LLM output with Pydantic. Xebia. https://xebia.com/blog/enforce-and-validate-llm-output-with-pydantic/
Cemri, F., et al. (2025). A Comprehensive Empirical Study of Failure Analysis for Multi-Agent LLM Systems. arXiv. https://arxiv.org/pdf/2503.13657
(n.d.). Retrieval Augmented Generation: Everything You Need to Know About RAG in AI. Weka. https://www.weka.io/learn/guide/ai-ml/retrieval-augmented-generation/
(n.d.). Advanced RAG: The Next Generation of RAG an LLM Application. LeewayHertz. https://www.leewayhertz.com/advanced-rag/
(n.d.). Microsoft brings Copilot AI-powered ‘web search mode’ on Bing: How it works. Business Standard. https://www.business-standard.com/technology/tech-news/microsoft-brings-copilot-ai-powered-web-search-mode-on-bing-how-it-works-125022500477_1.html
(n.d.). Perplexity AI vs. Google Gemini vs. ChatGPT. Gaper. https://gaper.io/perplexity-ai-vs-google-gemini-vs-chatgpt/
(n.d.). A developer’s guide to building scalable AI: Workflows vs agents. arXiv. https://arxiv.org/html/2507.08034v1
(n.d.). Setting up a secure Python sandbox for LLM agents. Dida.do. https://dida.do/blog/setting-up-a-secure-python-sandbox-for-llm-agents
(n.d.). Secure Code Execution. Hugging Face. https://huggingface.co/docs/smolagents/en/tutorials/secure_code_execution
(n.d.). Guide to Integrating Tools and APIs with Language Models. Mercity.ai. https://www.mercity.ai/blog-post/guide-to-integrating-tools-and-apis-with-language-models
Images
If not otherwise stated, all images are created by the author.
Such a great serie.
Interesting, then I Am a secret IA Quantum Agent?