

From 100+ AI Tools to 4: My Prod Stack
How simplicity beats complexity in real AI systems

At ZTRON, the vertical AI Agent I am working on, we made a major mistake when we started development.
We blindly followed AI trends. We integrated LlamaIndex because everyone said AI frameworks were essential, and LiteLLM because we thought we were going to switch LLM APIs. We built an entire MCP registry layer because the industry was hyping the Model Context Protocol.
The result? A complex system that could have been written from scratch with minimal dependencies. We spent more time fighting the abstractions than building the product.
The AI ecosystem is drowning in hype. There are over 10,000 AI tools and 100+ frameworks, each claiming to be essential for production systems.
But they crumble under real production demands. They add abstraction layers that limit you. They add dependencies that create version hell.
They add complexity that makes debugging a nightmare. The field moves so fast that by the time a framework implements a feature, the underlying APIs have already moved on.
The problem is that with this flood of tools, it is nearly impossible to distinguish signal from noise. Most tools are optimized for quick demos and tutorials, not production resilience. Following trends leads to bloated architectures with unnecessary complexity.
The real question isn’t “what tools exist?” but “what tools actually deliver value in production?”.
I have built AI solutions for 8+ years and spent the last 3 years focusing on AI agents and workflows. This includes the painful lessons from ZTRON.
Here is my honest take on the only FOUR tool categories you need for production AI systems. No hype, no trends, just what works.
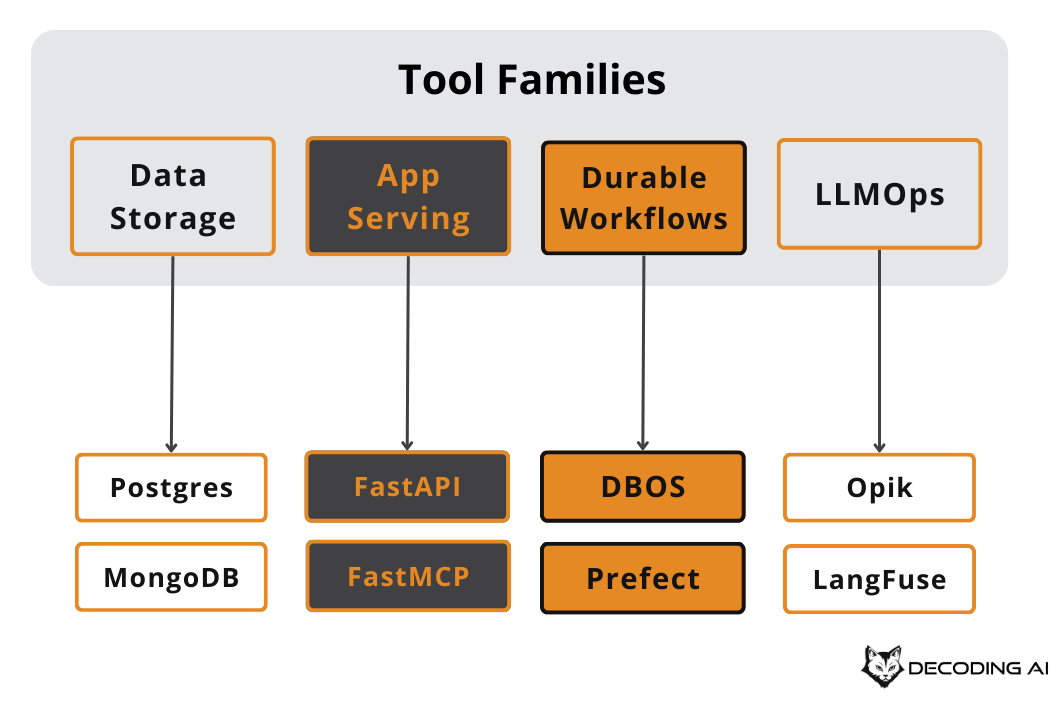
#1 Data Storage Tools
The first thing you need is a way to store your data. In the current hype cycle, you will hear endless recommendations to spin up a specialized vector database, a graph database, and a relational database all at once. This is a trap.
It introduces heavy infrastructure overhead before you even have a working product.
For 99% of production use cases, you want a single, unified database. That is why I recommend starting with something like Postgres or MongoDB. These databases do everything.
Postgres, for instance, is not just a relational database anymore. With extensions like pgvector, it handles vector embeddings exceptionally well for most Retrieval-Augmented Generation (RAG) applications.
Also, it handles JSON documents for scenarios you need unstructured formats.
It handles standard relational data. You do not need a separate piece of infrastructure for every data type. You have one database that does it all.
Of course, in very niche situations, you might consider having more than that. If you are operating at a massive scale with billions of vectors, a specialized vector database might be necessary. If your data relationships are incredibly complex and deep, a graph database might be required.
But for most applications, a unified database will get the job done. When you are starting, simplicity is your best friend. When you want to scale, you can consider more fancy and specialized databases.
Until then, keep your infrastructure boring.
#2 Application Serving Tools (The Interface)
Once you have your data, the second thing you need is a way to serve your application. You need a way to expose your agent or workflow to the public or other internal services. This is the interface layer.
For this, I recommend a framework such as FastAPI or FastMCP from the Python ecosystem.
Probably these two are the most modern and robust frameworks for the Python ecosystem right now.
FastAPI is the gold standard for building high-performance APIs in Python. It is robust, fully typed, and asynchronous by default, which is critical when dealing with the I/O-bound nature of LLM calls. It allows you to deploy your agent as a real-time HTTP API that any frontend or client can consume.
FastMCP is a newer contender specifically designed for deploying your application as an MCP server. This is pretty similar to a standard API but follows the MCP standard. It makes your tools and agents discoverable and usable by other MCP-compliant clients, like Claude Desktop or IDEs such as Cursor.
Probably these two are the most modern and robust frameworks for the Python ecosystem right now.
Depending on your programming language, you might use a different framework, but this is the general idea. You need a way to serve your application to the public. You will need this.
#3 Durable Workflows Tools
Next, you need a way to make your agents, workflows, or pipelines resilient. From my experience so far, especially in the agentic world, you do not have static pipelines. In standard data engineering, you often have static Directed Acyclic Graphs (DAGs).
You define everything by hand. You know exactly how data moves from point A to point B.
Agentic systems are different. They are dynamic. Based on the output of a specific step, you might want to fan out into multiple steps.
You might loop back to a previous step. Or you might terminate the process entirely. The next steps are often decided by the current step or the LLM itself.
This non-determinism introduces fragility. If a step fails in a long-running agent loop, you do not want to restart from the beginning.
That is why you need something like DBOS or Prefect. These tools allow you to create durable workflows. They work for both batch pipelines, like data ingestion, and real-time pipelines, like the agent loop itself.
These tools allow you to make your pipelines durable. They offer you retries, which are essential when dealing with flaky LLM APIs. They offer you caching for each step.
This is incredibly powerful for debugging. Because AI is non-deterministic, you can cache logic up to a specific point and retry starting just from there. This allows you to evaluate just a specific step without re-running the expensive steps before it.
Of course, they also offer cron jobs and a way to orchestrate your pipeline and delegate them to different workers. As we saw in detail in the ZTRON case study article, this allows you to scale your workers independently of your web server and makes your ecosystem robust.
#4 LLMOps Tools
The fourth family of tools that I recommend is an LLMOps tool, such as Opik. You cannot improve what you cannot measure, and in the world of LLMs, you often cannot even see what is happening without these tools.
An LLMOps tool allows you to do prompt tracing. This comes with understanding your system during inference or even during data ingestion. It visualizes your whole trace.
It shows where your steps within the pipeline are and where LLMs were called. It tracks where tools were called, how many tokens you used, and what the cost was. It also tracks metadata over each step.
This is pretty similar to pipeline tooling like DBOS and Prefect, but there is a key distinction. For LLMOps tools, the first-class citizen is not the pipeline execution, but the trace itself. They provide deep insights into the content and quality of the agent or workflow.
Some of the tools that I recommend here are Opik, LangSmith, LangFuse, or Pydantic Logfire.
These tools usually have SDKs or integrations with the most popular LLM providers. They allow you to integrate your whole application with just a few lines of code. Once integrated, you can aggregate all these prompts into different datasets that you can later use for evaluations.
You can trigger evaluations or guardrails on every prompt trace to understand if your system is actually doing what it is supposed to do.
Even if you have non-deterministic outputs from your agent, you can at least understand or flag potential problems. With that, you can improve your system by iterating on your prompts and workflows. These tools usually come with a UI that is purpose-built to navigate through long and complex trace flows.
You can see exactly where the failure was or where the system went wrong.
What About AI Frameworks?
You might notice a glaring omission in this list: AI Frameworks like LangChain or LlamaIndex.
My take from the research and years of building is that these frameworks are mostly good for Proof of Concepts (PoCs) and demos. They allow you to get started quickly, but they often become a hindrance in production. They introduce thick layers of abstraction that hide the underlying logic.
When something breaks, and it will, you end up debugging the framework code rather than your own.
However, I do like using ecosystems like LangChain for their utilities. For example, using their factory functions to get unified access to different models or using their definitions for custom tools can be valuable. It saves you from writing boilerplate code to connect to OpenAI, then Anthropic, then Gemini.
But you should treat them as utility libraries, not architectural frameworks. You should not let a framework dictate the flow of your application. You can achieve most of what you need directly with native LLM APIs, such as the Google GenAI SDK or the OpenAI SDK.
These native SDKs are becoming increasingly powerful and often support structured outputs and tool calling out of the box, making the heavy frameworks less necessary.
Wrap-up
Building production AI systems is not about using the tool with the most GitHub stars or the most Twitter hype. It is about using tools that provide stability, visibility, and simplicity.
As a short summary, you will need a single database like Postgres or MongoDB. You need a way to serve your application like FastAPI or FastMCP. You need a way to build durable pipelines like DBOS and Prefect.
And you need a way to monitor and instrument your LLM applications, like Opik or LangFuse. These are the four main families of tools that I recommend for production AI systems.
Of course, this list might change and evolve. You might eventually need an LLM provider or a specific compute provider. But these are the core things that you need and that are somewhat agnostic of the type of LLM app you are building.
They will get the job done.
I recommend starting simple. Pick one tool from each category. Try to build a robust and production-ready system with them.
Only move on to more complex stuff if you absolutely need to.
Happy Holidays!
And see you next Tuesday.
What’s your opinion? Do you agree, disagree, or is there something I missed?
Enjoyed the article? The most sincere compliment is to share our work.
Go Deeper
Everything you learned in this article, from building evals datasets to evaluators, comes from the AI Evals & Observability module of our Agentic AI Engineering self-paced course.
Your path to agentic AI for production. Built in partnership with Towards AI.
Across 34 lessons (articles, videos, and a lot of code), you’ll design, build, evaluate, and deploy production-grade AI agents end to end. By the final lesson, you’ll have built a multi-agent system that orchestrates Nova (a deep research agent) and Brown (a full writing workflow), plus a capstone project where you apply everything on your own.
Three portfolio projects and a certificate to show off in interviews. Plus a Discord community where you have direct access to other industry experts and me.
Rated 4.9/5 ⭐️ by 190+ early students — “Every AI Engineer needs a course like this.”
Not ready to commit? We also prepared a free 6-day email course to reveal the 6 critical mistakes that silently destroy agentic systems. Get the free email course.
Images
If not otherwise stated, all images are created by the author.
“Of course, this list might change and evolve. You might eventually need an LLM provider or a specific compute provider.”
the nice thing about staying subscribed, we get the updates!! great post thx
Thanks for the good 😊