

Agentic Harness Engineering
Building systems that transform the LLM into the new operating system

At the AI start-up I’ve been working at, building a financial personal assistant, we implemented LlamaIndex, added the Model Context Protocol (MCP), and built complex Retrieval-Augmented Generation (RAG) pipelines. Each piece added complexity without adding direct business value.
When we stripped everything back to plain Python, simple API calls, and a custom ReAct engine, things finally worked. What we accidentally built was a harness featuring specialized financial tools, domain-specific guardrails, and purpose-built context engineering.
We did not know the term yet, but the lesson was clear. The model was never the problem. The system and infrastructure around it were.
Most engineering teams obsess over which model to use. They debate GPT-4o versus Claude Opus versus Gemini. They chase LLM benchmark scores and swap models, hoping for better results.
But the model is only half the equation. The system and infrastructure around it determine whether your agent actually works in production.
TerminalBench 2.0 proved this. Changing only the harness moved the DeepAgent from LangChain from outside the top 30 to the top 5 [1].

This is what usually happens. You have a powerful model. You gave it tools and a prompt. It works in demos.
But shipping it to production means solving problems the model cannot solve alone. You must bridge context windows, recover from failures, serve multiple interfaces, and manage state across sessions.
The solution is harness engineering. This is the discipline of building the infrastructure around the model so it can do useful work reliably. As Mitchell Hashimoto noted, harness engineering is the practice of engineering a solution every time an agent makes a mistake, ensuring it never makes that specific mistake again [2].
By the end of this article, you will learn:
What an agent harness actually is.
The core components powering production AI systems.
How the planning loop dictates agent actions.
The design principles behind an effective toolset.
How to manage memory using the filesystem.
Before we look at all its components and how they fit together, we must first define what a harness actually is.
Your Path to Agentic AI Engineering for Production (Product)

Most engineers know the theory behind agents, context engineering, and RAG. What they lack is the confidence to architect, evaluate, and deploy these systems in production. The Agentic AI Engineering course, built in partnership with Towards AI, closes that gap across 34 lessons (articles, videos, and a lot of code).
By the end, you will have gone from “I built a demo” to “I shipped a production-grade multi-agent system with evals, observability, and CI/CD.” Three portfolio projects, a certificate to back them up in interviews, and a Discord community with direct access to industry experts.
Rated 5/5 ⭐️ by 300+ early students saying “Every AI Engineer needs a course like this” and that is “An excellent bridge from experimental LLM projects to real-world AI engineering.”
Start learning today. The first 6 lessons are free:
So... What the Heck Is a Harness?
While talking with Jonathan Gennick from Manning, he said that the first time he heard about the term “harness” was in the context of horses. Let me explain. A horse is powerful on its own, but useless for farming without a harness. The straps and reins let you direct its strength toward useful work. The same applies to LLMs.
The model has intelligence. But without tools, memory, state, guardrails, and orchestration, you cannot put it to work reliably.
LangChain offers the clearest definition. An agent equals a model plus a harness. The harness is every piece of code, configuration, and execution logic that is not the model itself [1].
A basic agent, as we know it so far, is just a model, a prompt, tools, and a planning loop. A harness extends this by adding memory systems, guardrails, advanced orchestration, context engineering, and multi-agent coordination.
Usually, it also includes a serving layer that connects the agent to various user interfaces, such as terminal apps, web dashboards, IDE plugins, and messaging apps like Telegram.
Ultimately, a harness is a term for building real software applications using LLMs or other models as the operating system. Applications like Claude Code, OpenCode, OpenClaw, and Codex are all harnesses. You could swap the model inside them, but the real engineering value lives in the harness itself.
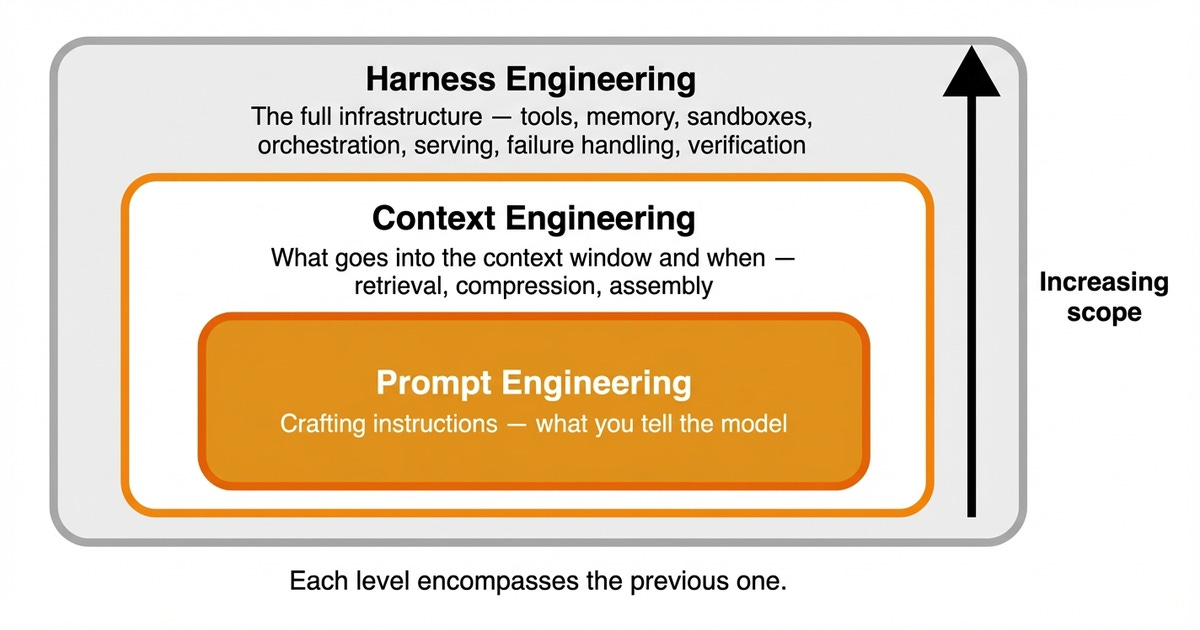
This introduces three distinct levels of engineering. Prompt engineering crafts the instructions. Context engineering dictates what goes into the context window and when.
Harness engineering is the full application and infrastructure. It controls when context loads, which tools are available, which actions are allowed, and how failures are handled. Each level encompasses the previous one [3].
Now that you understand what a harness is, the next step is to explore the internal architecture and see how these pieces connect.
The Anatomy of a Harness
A complete harness consists of the LLM, tools, a planning loop, context engineering, a sandbox, memory, an orchestration layer, and a serving layer. In other words, everything that has been hovering within the AI space is finally falling into one beautiful system.

One of the most distinctive features of modern harnesses is the multi-surface architecture. OpenClaw serves the same agent across a command-line interface (known as TUI), a web UI, desktop apps, Slack and Telegram/WhatsApp through a centralized Gateway using a typed WebSocket protocol.
Codex evolved from a simple terminal tool to an App Server using JSON-RPC over standard input and output. OpenCode uses a Bun JS HTTP server where any client connects via HTTP, utilizing an Event Bus to broadcast results in real-time [4], [5], [6].
This architecture introduces challenges. Multiple messages arrive in parallel from different clients. Users ask questions while the model is still processing.
To solve this, systems use priority queues and message buses. OpenClaw uses a lane-aware FIFO queue to ensure only one active run per session while allowing parallelism across different sessions.
At the core of all this infrastructure, the filesystem is king. As the most foundational harness primitive, it enables durable storage, workspace management, multi-agent collaboration, and versioning.
You heard me right, there is no fancy vector database in place. With AI, we are going back to basics, and nothing is purer than the filesystem itself.
Every production harness uses the filesystem as its primary state mechanism [1].
You might wonder if this is just traditional orchestration like Airflow. It is different in three key ways. The agent loop is non-deterministic, context management is a first-class concern, and the programmer inside the loop is the LLM itself. It is common to add durability to the harness using tools such as Prefect, Temporal or DBOS that natively support dynamic pipelines rather than predefined, rigid DAGs.
Let us zoom in on the first and most fundamental component: the planning loop.
How the Agent Decides What to Do Next
The most common pattern for the planning loop is ReAct, which stands for Reasoning and Acting. The model receives the current state, reasons about what to do next, takes an action via a tool call, and observes the result. This cycle repeats continuously until a strict stopping condition is met [5].
Consider a concrete example. A user asks the agent to fix a failing test. First, the model reads the test output, reasons that the import path is wrong, and edits the file through a tool.
Second, it re-runs the tests, sees a new type mismatch error, and fixes it. Third, it runs the tests again.
They pass, the model reasons the job is done, and it stops. The harness orchestrates this loop, while the model reasons and picks actions.

When tasks are too complex for a single agent, harnesses use orchestrator-worker patterns. The orchestrator decomposes a task, delegates subtasks to specialized workers, and aggregates the results.
In OpenCode, a dedicated task tool spawns subagents. Each subagent gets its own session, context window, and restricted tool set [7].
For tasks that span multiple context windows, Claude Code implements Ralph Loops. This harness mechanism intercepts the model’s attempt to exit via a hook. It reinjects the original prompt in a clean context window, forcing the agent to continue against a completion goal using the state persisted on the filesystem [1].
While automating my business with agents, I learned a hard lesson about orchestration. I initially built five specialized agents, each handling one step.
I eventually found that a single agent with memory and smart context engineering outperformed the whole swarm. Always start with one well-harnessed agent before reaching for multi-agent complexity.
Here is a deep dive into planning:

While the planning loop decides the next step, the agent still needs a way to interact with its environment.
The Tools That Let Agents Act
This interaction happens through a specific toolkit designed for autonomous execution.
First, Bash is a general-purpose tool. The agent can run any shell command to execute tests, linters, or builds. This gives the model code execution capabilities so it can design its own tools on the fly rather than being constrained by fixed options.
For example, the agent runs Python code and executes it through python -c "...", generates a script and runs it through python main.py or runs your code as python -m my_module.main.
Second, specialized filesystem tools handle common operations like reading, writing, editing, and searching. Doing file operations via Bash is slow and error-prone.
Specialized tools include safety checks. For instance, a read tool enforces absolute paths and line limits, while an edit tool validates the uniqueness of replacement strings.
Third, state management tools track session-scoped tasks. These give the agent working memory within a single session. For example, OpenCode has ToDoAdd and ToDoRead tools that add/read tasks from a queue to keep track of the plan it has to execute.
Finally, orchestration tools launch subagents with their own isolated prompts and context windows, such as OpenCode’s task tool or Claude Code’s agent tool.

Feedback loops are the most important principle around tooling. Boris Cherny, the creator of Claude Code, noted that giving the model a way to verify its work improves quality by two to three times. For example, OpenCode integrates the Language Server Protocol (LSP) to get real-time code definitions and diagnostics.
Undefined variables and type errors are fed back to the LLM for immediate correction. These tools do not act on the world. They feed vital information back to the planning loop.
Harnesses also enforce tool access control. In OpenCode, the planning agent cannot call edit tools. This prevents exploratory agents from accidentally modifying your code [5].
Here is a deep dive into tool calling:

Once the agent has its tools, it needs a secure place to use them. In production, this requires strict isolation.
Where Agents Run
Agents execute code, and that code can fail, crash, or delete all your files. I know I want my precious notes protected. Sandboxes isolate agent execution so failures do not affect the host system or other agents. The cherry on top is that they also enable horizontal scaling across parallel environments.
There is a strict tradeoff between security and capability. Not every harness uses the same approach. Codex uses a hard sandbox.
Each task runs in an isolated cloud container preloaded with the repository. This provides maximum safety, but the agent cannot access the host filesystem [6].
Conversely, OpenClaw uses a soft sandbox. The workspace is the default working directory. This grants maximum capability but introduces more risk.
OpenClaw deliberately avoids hard sandboxing to preserve full filesystem access. Most production harnesses sit somewhere between these extremes, depending on the trust model.
When you submit a task to Codex, the harness spins up a fresh cloud container. The agent works inside this container to read files, run tests, and install packages.
It cannot touch your local machine. When the job finishes, the results are extracted, and the container is destroyed.
Along with security, a major benefit of cloud sandbox environments is that they give the agent access to powerful computing resources. For example, if you want to train a model using a GPU, you can ask the agent to implement and run a training pipeline hosted in a sandbox powered by a GPU.
This is similar to manually SSHing to different VMs and running the code manually there. Based on the same principles, you can easily spin up multiple cloud sandboxes and run your agents in parallel.
On the other side of the spectrum, you can also run sandbox environments locally through Docker containers or isolated processes, similar to what Cursor does. Super useful when you want to try something out and give the agent full permissions to avoid having to supervise it.
While sandboxes provide a safe space for execution, they are ephemeral by design.
Memory Is Just the Filesystem
To survive across sessions and context windows, every harness manages state across three distinct memory layers. The first layer is the filesystem. This is the long-term memory.
It is durable and persistent, surviving across sessions. This is where progress files, git history, and session transcripts live.
The second layer is the RAM. This is the short-term memory, also known as the working memory. It holds the conversation history and tool results during an active session. It is fast but volatile.
The third layer is the context window. This is what the model actually sees. It is the strictest constraint, as everything the model knows about the current task must fit here.
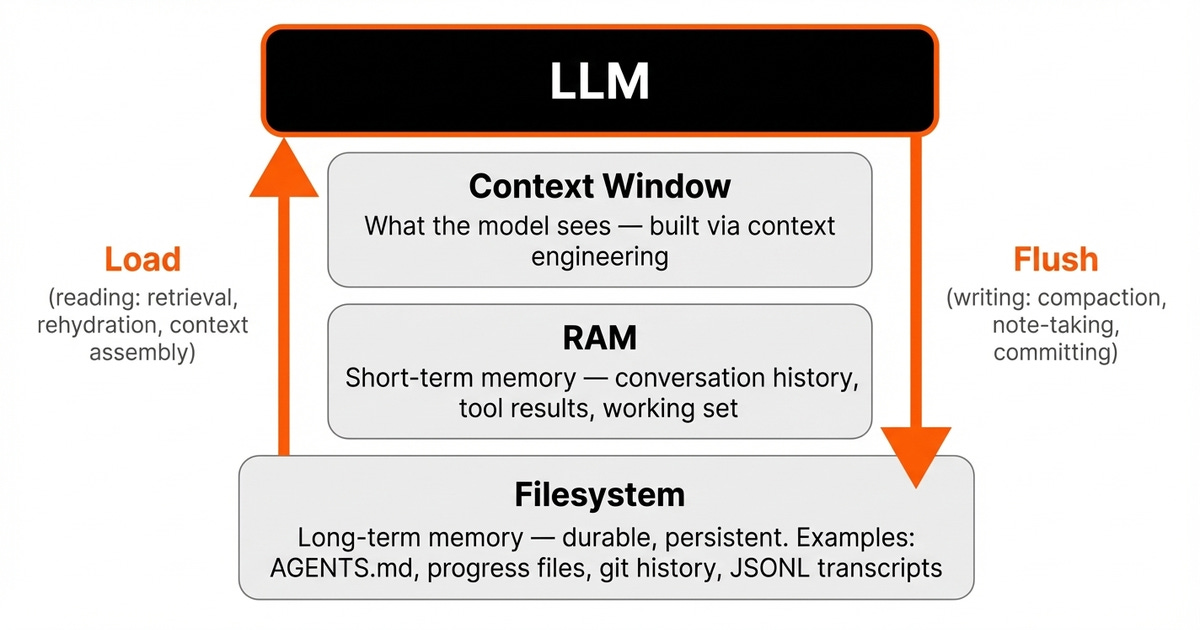
The harness orchestrates the dynamics between these layers. On the read path, the harness selectively loads relevant state from the disk into the RAM.
It then assembles the context window using context engineering techniques such as compaction, progressive disclosure, and just-in-time retrieval. On the write path, the harness persists important state back to the disk after processing.
OpenClaw enforces a strict invariant that memory is always flushed to disk before being discarded from context. Rehydration is treated as a tool-shaped action, where the agent searches and then retrieves specific data, rather than dumping everything into the context window [8].
Context engineering makes this possible. When token counts exceed ninety percent of the limit, OpenCode automatically summarizes the conversation. Codex assembles prompts from multiple sources and exploits prompt caching.
Anthropic recommends using structured note-taking files and sub-agent architectures to isolate context [5], [6], [9].
In Anthropic’s long-running agent pattern, an initializer agent creates a script, a progress file, and a feature list. The coding agent reads the git logs and progress files at the start of each session and updates the progress file as it progresses.
The beauty? There is no database or vector store. It is just the filesystem [10].
Here is a deep dive into memory:
Now that you have seen all the pieces, from planning and tools to sandboxes and memory, the question is what this means for how you build software.
What’s Next
We are witnessing a new way of building software. Instead of software engineers building traditional frontend and backend applications, the next generation of production software will be harnesses. Harness engineering is merging software engineering with AI, moving it one level up [3].
Popular tools like Claude Code are just the beginning. In the long run, no company will want to depend entirely on proprietary harnesses. Even open-source solutions like OpenCode will not cover every specific use case.
Companies will inevitably build their own. As we experienced at ZTRON, custom systems and infrastructure are what finally make an agent work in production.
However, we must be honest about current limitations. Memory still breaks across long sessions. Validation loops still miss edge cases. Furthermore, orchestrating hundreds of parallel agents on shared codebases remains an open research problem.
Harness engineering is real engineering. Your harness becomes its own product with its own bugs, its own drift, and its own maintenance burden.
What’s your opinion? Do you agree, disagree, or is there something I missed?
Enjoyed the article? The most sincere compliment is to share our work.
Go Deeper
Go from zero to production-grade AI agents with the Agentic AI Engineering self-paced course. Built in partnership with Towards AI.
Across 34 lessons (articles, videos, and a lot of code), you’ll design, build, evaluate, and deploy production-grade AI agents end to end. By the final lesson, you’ll have built a multi-agent system and a capstone project where you apply everything you’ve learned on your own.
Three portfolio projects and a certificate to showcase in interviews. Plus a Discord community where you have direct access to other industry experts and me.
Rated 4.9/5 ⭐️ by 300+ students saying “Every AI Engineer needs a course like this.”
Not ready to commit? We also prepared a free 6-day email course to reveal the 6 critical mistakes that silently destroy agentic systems. Get the free email course.
References
LangChain. (2026, March 21). The Anatomy of an Agent Harness. LangChain Blog. https://blog.langchain.com/the-anatomy-of-an-agent-harness/
Hashimoto, M. (2026, March 25). My AI Adoption Journey. Mitchell Hashimoto. https://mitchellh.com/writing/my-ai-adoption-journey
Bouchard, L. (2026, March 25). What Harness Engineering Actually Means. What’s AI by Louis-François Bouchard. https://youtube.com/watch?v=zYerCzIexCg
Govindarajan, V. (2026, March 21). OpenClaw Architecture Part 1 - The Agent Stack. The Agent Stack. https://theagentstack.substack.com/p/openclaw-architecture-part-1-control
Abboud, M. (2026, March 17). How Coding Agents Actually Work: Inside OpenCode. Moncef Abboud. https://cefboud.com/posts/coding-agents-internals-opencode-deepdive/
ByteByteGo. (2026, March 26). How OpenAI Codex Works. ByteByteGo. https://blog.bytebytego.com/p/how-openai-codex-works
Anthropic. (2025, December 24). Building Effective AI Agents. Anthropic. https://www.anthropic.com/research/building-effective-agents
Govindarajan, V. (2026, March 24). OpenClaw Architecture Part 3: Memory and State Ownership. The Agent Stack. https://theagentstack.substack.com/p/openclaw-architecture-part-3-memory
Anthropic. (2025, October 22). Effective Context Engineering for AI Agents. Anthropic. https://www.anthropic.com/engineering/effective-context-engineering
Anthropic. (2026, March 25). Effective Harnesses for Long-Running Agents. Anthropic. https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
Images
If not otherwise stated, all images are created by the author.
really timely article. it’s super interesting to see Anthropics approach’s to harnessing with this recent leak.
looks like a lot of people suddenly became more aware of these techniques. i think we are going to see more attention in this area, and articles like this are super useful.
Re sandboxes. Do remember that AIs aren't bad at escaping sandboxes. They've done it before.
And since agents are inherently unreliable, deterministic procedures must be in place to control and monitor them as part of - perhaps the major part of - the harness engineering.