

You're Not Building Agents: Learn the Fundamentals From Scratch
Why planning is the missing piece between tool loops and true AI agents.

Welcome to the AI Agents Foundations series—a 9-part journey from Python developer to AI Engineer. Made by busy people. For busy people.
Everyone’s talking about AI agents. But what actually is an agent? When do we need them? How do they plan and use tools? How do we pick the correct AI tools and agentic architecture? …and most importantly, where do we even start?
To answer all these questions (and more!), We’ve started a 9-article straight-to-the-point series to build the skills and mental models to ship real AI agents in production.
We will write everything from scratch, jumping directly into the building blocks that will teach you “how to fish”.
What’s ahead:
Planning: ReAct & Plan-and-Execute ← You are here
By the end, you’ll have a deep understanding of how to design agents that think, plan, and execute—and most importantly, how to integrate them in your AI apps without being overly reliant on any AI framework.
Let’s get started.
Opik: Open-Source LLMOps Platform (Sponsored)
This AI Agents Foundations series is brought to you by Opik - the LLMOps open-source platform used by Uber, Etsy, Netflix and more.
But most importantly, we are incredibly grateful to be supported by a tool that we personally love and keep returning to for all our open-source courses and real-world AI products. Why? Because it makes escaping the PoC purgatory possible!

Here is how Opik helps us ship AI workflows and agents to production:
We see everything - Visualize complete traces of LLM calls with costs and latency breakdown at each reasoning step.
Easily optimize our system - Measure our performance using custom LLM judges, run experiments, compare results and pick the best configuration.
Catch issues fast - Plug in the LLM Judge metrics into the production traces and get on-demand alarms.
Stop manual prompt engineering - Their prompt versioning and optimization features allow us to track and improve our system automatically. The future of AutoAI.
Opik is fully open-source and works with custom code or most AI frameworks. You can also use the managed version for free (w/ 25K spans/month on their generous free tier).
Planning: ReAct & Plan-and-Execute Patterns
Let me tell you a secret: so far in this series, we have not built any real agents. We have assembled the fundamentals, such as understanding the autonomy slider, context engineering, and tools. But what truly makes an agent an agent?
I have often seen people running tools in a loop and calling that an agent, but that is only half the story. That approach fails when running multiple tools or in complex scenarios. Why? Because it is missing planning, which is the special sauce that enables the transition from a simple workflow to a true agent.
I experienced that myself. One year ago, in the early days of ZTRON, our financial services vertical AI agent, we built an agentic RAG system from scratch. We had all our retrieval tools in place, such as semantic, text and document search. Thus, we thought that simply calling these tools in a loop, where the LLM decides which tool to call next until it gathers all the necessary information to answer the user's query, was sufficient. But oh, man, we were so wrong!
After debugging for a while, the problem was clear. The agent lacked structure. It lacked planning. It was reacting to each observation without a clear strategy or goal decomposition. This is what happens when you give an LLM tools and run them in a loop without proper planning mechanisms.
Then we finally understood that the secret sauce to building successful agents is to mix tools and planning while running everything in a loop.
But how does planning actually work? How does it connect to tools and loops? These questions confused me when I first started building agents. That is why in previous articles, we slowly built all the necessary blocks to fully grasp how everything connects into the popular “AI Agent” construct.
So, how do we implement planning? We first need to separate planning from execution. Then, we will present the two core methods behind planning: ReAct and Plan-and-Execute. Let’s start by understanding what separating planning and execution actually means.
The Foundations: Separating Planning from Taking Action
As we have established, planning inside a loop is the biggest leap from a workflow to an agent. The first thing you must understand about planning is the separation of the planning process from the action of calling tools.
An early attempt at mimicking planning was through chain-of-thought (CoT) prompting. You might remember it as the classic “think step by step” instruction.
The biggest issue with this strategy is the lack of a clear separation of concerns between what is “planning” and what is “action.” It couples thinking and execution into a single LLM output, making it a nightmare to distinguish one from the other [6]. This lack of separation means we cannot easily build an iterative loop where the agent acts on one step, observes the result, and uses that observation to inform the next step.
To achieve that level of control and build a truly adaptive agent, we need to properly separate the two processes.
The core idea is simple: ask the model to first plan or reason, and then, as a distinct step, produce a final answer or take an action in the form of tools. This decoupling is the cornerstone of modern agent design.
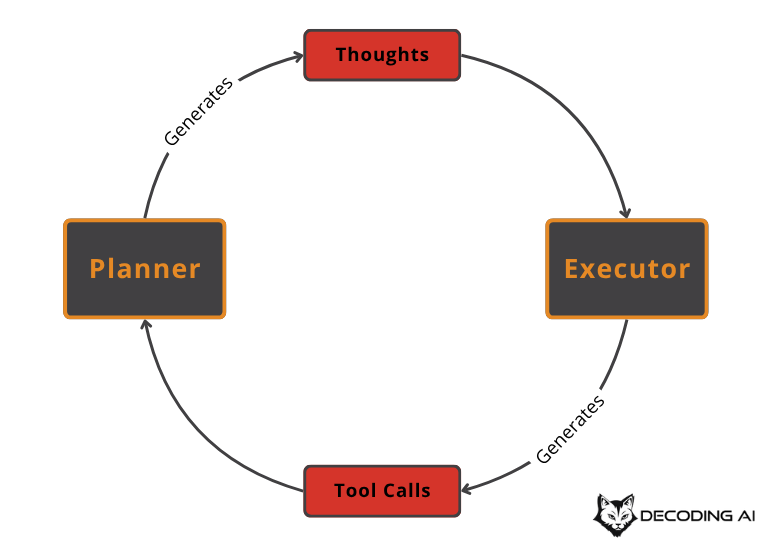
This separation gives us control and interpretability. It enables iterative loops where observations from the environment (tool outputs) can update the plan. This principle is what enables the two foundational agentic patterns:
ReAct interleaves Thought → Action → Observation in a tight loop.
Plan-and-Execute separates a comprehensive Planning phase from a distinct Execution phase.
First, let’s see how this applies to ReAct in more depth.
The Birth of AI Agents: The ReAct Loop
The ReAct (Reason + Act) framework was introduced to bridge the gap between pure reasoning (like CoT) and action. Instead of thinking once and then acting, ReAct interleaves reasoning, acting, and observing feedback from the environment in a continuous cycle [5], [7].
This allows the agent to dynamically adjust its plan based on new information, much like how humans tackle problems by thinking, doing something, seeing what happens, and then thinking again. This iterative nature is what gives ReAct its power and flexibility, making it a foundational pattern for building agents that can navigate complex and unpredictable environments.
The loop is straightforward: the agent forms a Thought (a reasoning step), takes an Action (calls a tool), gets an Observation (the tool’s output), and uses that observation to form the next thought. This continues until it has enough information to generate a Final Answer.
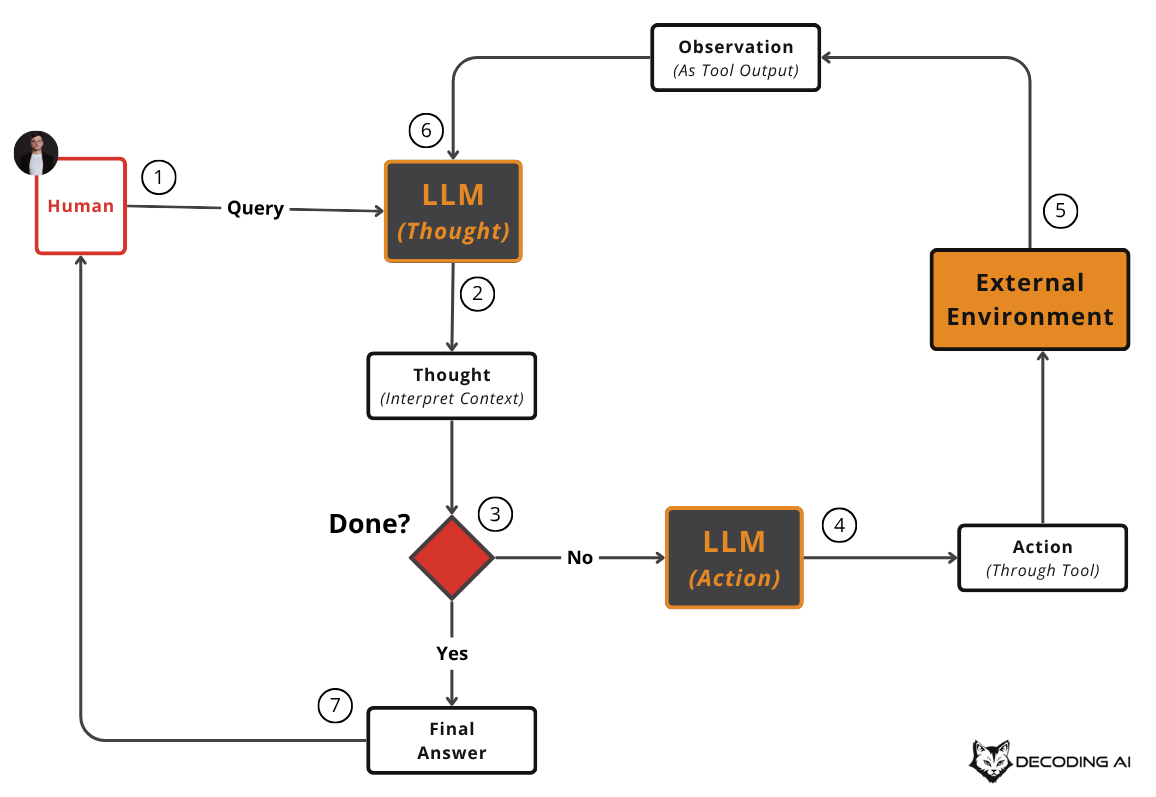
Let’s illustrate this with a deep research agent example, inspired by one of the capstone projects of our AI Agents course. We called the deep research agent Nova.
So… Suppose we give Nova the following task: “How can I evaluate AI Agents using LLM Judges?”
This is how it will work when using the ReAct pattern to implement the deep research agent.
Round 1: Initial Broad Research
Thought: “I need to understand the current landscape. Let me generate initial research queries covering different aspects.”
Action:
generate_queries(task=”How can I evaluate AI Agents using LLM Judges?”, n_queries=3)Observation: Generated queries:
“What are the best practices for using LLMs as judges for AI agent evaluation?”
“What frameworks and tools exist for LLM-based evaluation of agents?”
“What are common pitfalls when using LLM judges for agent evaluation?”
Thought: “Now I’ll search for answers using Perplexity to get high-quality sources with citations.”
Action:
perplexity_search(queries=[”What are the best practices for using LLMs as judges for AI agent evaluation?”, ...])Observation: Returns 3 results with 15 total source URLs (academic papers, blog posts, documentation).
Thought: “The Perplexity results mention several key concepts and sources. Let me scrape the most relevant URLs for full content.”
Action:
scrape_urls(urls=[”https://arxiv.org/paper123”, “https://anthropic.com/blog/llm-judges”, ...], max_sources=5)Observation: Scraped 5 articles covering: evaluation frameworks, bias in LLM judges, pairwise vs scoring methods.
Thought: “One article mentions ‘AgentBench’ and links to a GitHub repo with evaluation code. Let me fetch that.”
Action:
process_github_urls(urls=[”https://github.com/example/agentbench”])Observation: Extracted repo with evaluation scripts, metrics implementation, and benchmark datasets.
Round 2: Refined Specific Research
Thought: “Now I have context on frameworks and bias concerns. I notice a gap: how do practitioners handle disagreement between human and LLM judges? Let me generate more targeted queries.”
Action:
generate_queries(task=”Given context on LLM judge frameworks and bias, find information on handling judge disagreements”, n_queries=2, context=previous_findings)Observation: Generated queries:
“How to measure inter-rater reliability between human and LLM judges in agent evaluation?”
“What are calibration techniques for LLM judges to align with human preferences?”
Thought: “These are more specific. Let me search for technical details and implementation examples.”
Action:
perplexity_search(queries=[”How to measure inter-rater reliability between human and LLM judges...”, ...])Observation: Returns 2 results with 8 source URLs, including research papers on calibration and Cohen’s Kappa for LLM judges.
Thought: “One source mentions an open-source calibration toolkit. Let me scrape that and get the code.”
Action:
scrape_urls(urls=[”https://paper-with-calibration-method.com”])Observation: Detailed methodology for calibrating LLM judges using few-shot examples.
Action:
process_github_urls(urls=[”https://github.com/calibration-toolkit”])Observation: Extracted calibration code, test cases, and evaluation metrics implementation.
Thought: “I now have comprehensive coverage: frameworks, bias mitigation, calibration techniques, and code examples. Time to synthesize.”
Final Answer: A structured research report based on all gathered sources.
Here is a high-level Python code showing how this loop works.
First, we define our mocked tools for the research agent.
def generate_queries(task: str, n_queries: int, context: str = “”) -> list[str]:
return [f”query_{i+1}_for_{task.replace(’ ‘, ‘_’)}” for i in range(n_queries)]
def perplexity_search(queries: list[str]) -> dict:
return {q: [f”http://example.com/{q}_result_{i}” for i in range(3)] for q in queries}
def scrape_urls(urls: list[str], max_sources: int) -> list[str]:
return [f”scraped_content_from_{url}” for url in urls[:max_sources]]
def process_github_urls(urls: list[str]) -> list[str]:
return [f”processed_repo_from_{url}” for url in urls]
TOOLS = {
“generate_queries”: generate_queries,
“perplexity_search”: perplexity_search,
“scrape_urls”: scrape_urls,
“process_github_urls”: process_github_urls,
}Next, we define our
ReActAgentclass. The core logic resides in therunmethod, which implements the thought-action-observation loop.class ReActAgent: def __init__(self, model, tools): self.model = model self.tools = tools self.thought_history = [] self.observation_history = [] def run(self, task: str, max_steps: int = 10): for step in range(max_steps): # 1. THOUGHT: First LLM call to reason about the current state thought = self._generate_thought(task) self.thought_history.append(thought) # Check if we have reached the final answer if self._is_task_complete(thought): return thought # 2. ACTION: Second LLM call to select which tool to use action = self._select_action(task, thought) # 3. OBSERVATION: Execute the tool and capture the result observation = self._execute_action(action) self.observation_history.append(observation) return “Max steps reached. Unable to complete the task.”def _generate_thought(self, task): “”“First LLM call: Generate reasoning about what to do next”“” context = self._build_context() prompt = f"""Task: {task} Previous context: {context} Based on the task and your previous thoughts and observations, reason about what you should do next.""" response = self.model.generate_content(prompt) return response.text def _select_action(self, task, current_thought): “”“Second LLM call: Decide which tool to call based on the thought”“” tools_description = json.dumps(list(self.tools.keys())) prompt = f"""Task: {task} Current thought: {current_thought} Available tools: {tools_description} Based on your thought, which tool should you use? Return JSON: {{“name”: “tool_name”, “args”: {{“param”: “value”}}}}""" response = self.model.generate_content(prompt) return json.loads(response.text) def _execute_action(self, action): “”“Execute the selected tool and return the observation”“” tool_name = action[”name”] tool_args = action[”args”] tool_function = self.tools[tool_name] return tool_function(**tool_args) def _is_task_complete(self, thought): “”“Check if the thought indicates task completion”“” return “Final Answer” in thought or “DONE” in thought def _build_context(self): “”“Build context from thought and observation history”“” context_parts = [] for i, (thought, obs) in enumerate(zip(self.thought_history, self.observation_history)): context_parts.append(f”Step {i+1}:”) context_parts.append(f” Thought: {thought}”) context_parts.append(f” Observation: {obs}”) return “\n”.join(context_parts)
💡 Tip: Because an LLM does planning, it can always go sideways. Not today, not tomorrow, but at some point while you are in production.
That’s why monitoring your traces becomes even more critical when developing AI Agents. When pushing them to production, this allows you to debug and analyze your point of failure properly.
For example, imagine that one of your users complains that he asked for a report on Hybrid RAG, and instead, the agent provided a generic example. If you haven’t properly tracked everything, how could you debug this? For simple examples, some simple logs will get you out of the way, but AI Agents usually have dozens, if not hundreds, of steps, as you can see in the video below.
That’s why you need to implement proper monitoring with open-source tools such as Opik.
(I am not recommending them just because they sponsor this article. They are my go-to tool in all my projects.)
Also, as a huge bonus, you can easily track costs, token count latency, what models were called where, evaluate specific traces, etc. In this way, you can easily perform error analysis across multiple dimensions and iteratively optimize your AI system.
The ReAct pattern offers high interpretability and allows for natural error recovery through observations, making it well-suited for exploratory tasks. However, it can be slower due to its sequential nature and requires robust tooling and loop control to prevent infinite loops or getting stuck.
That’s why, in reality, ReAct is not that often used in its purest form in any production application. Still, it’s extremely important to understand how it works, as every modern agentic pattern is based on these same principles.
Thus, for tasks that require multi-step planning or parallel execution, the Plan-and-Execute pattern can be a more efficient option. Let’s dig into it.
The AI Agents Pattern: Plan-and-Execute
The Plan-and-Execute pattern is a more structured alternative to ReAct. Instead of deciding one step at a time, the agent produces a complete plan up front and then executes it.
This approach is better for tasks that are more predictable and can be broken down into a clear sequence of steps [8]. It separates the high-level reasoning from the low-level execution, allowing for more efficient, batch-style processing. This makes it particularly powerful for complex workflows where multiple actions can be performed in parallel, reducing latency and cost.
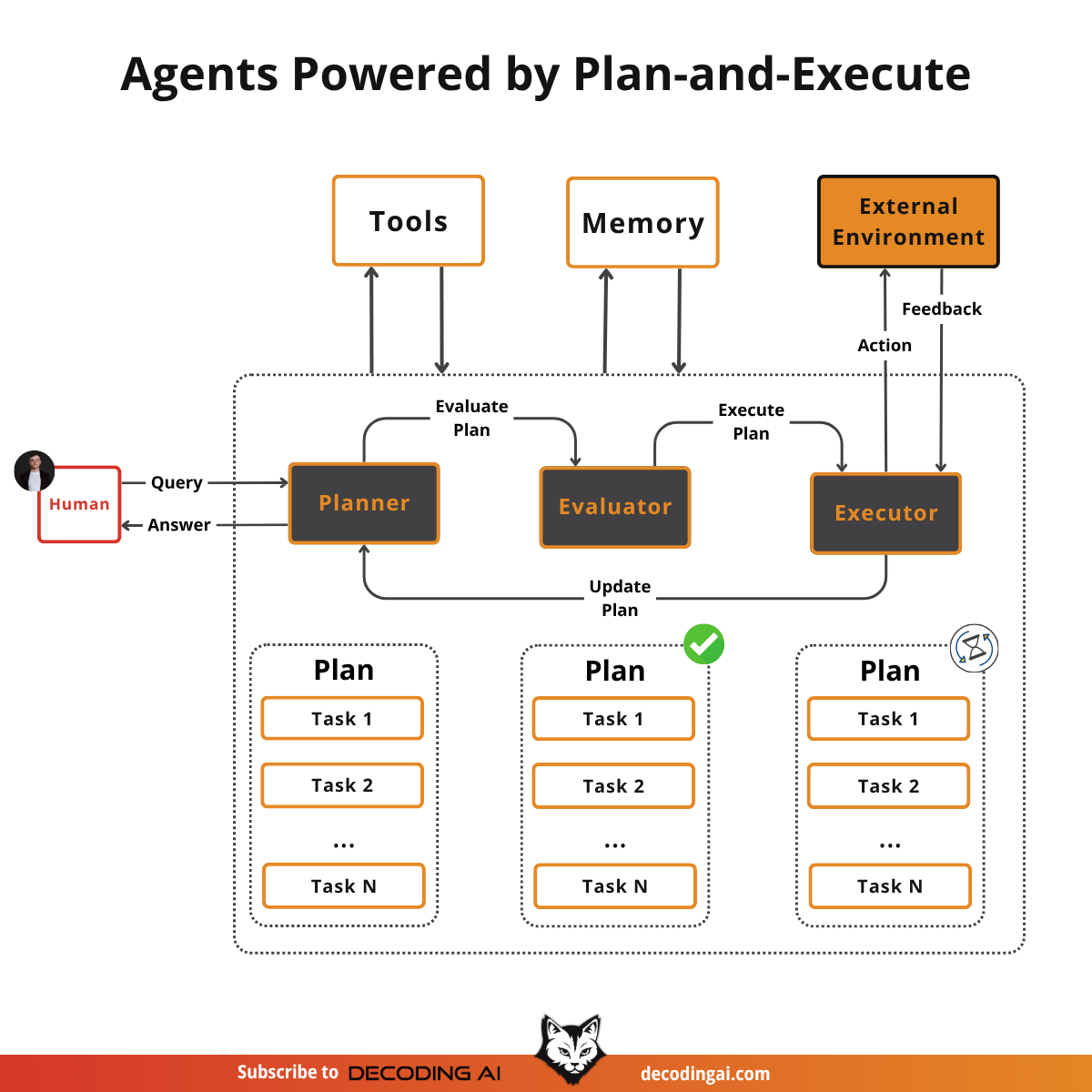
This pattern consists of three core components:
Planner: This is the strategic brain of the agent. It takes the high-level goal and decomposes it into a detailed, multi-step plan. A sophisticated planner can identify dependencies between steps and flag opportunities for parallel execution to optimize the workflow.
Evaluator: Before any action is taken, the evaluator validates the plan generated by the planner. It checks for logical consistency, feasibility, and alignment with the overall goal. If the plan is flawed, it is sent back to the planner for revision, preventing wasted resources on a faulty strategy.
Executor: This is the workhorse of the system. It takes the validated plan and carries out the specified actions by calling the necessary tools. The executor can run tasks sequentially or in parallel, as dictated by the plan, and is responsible for reporting the outcomes of each action back to the system.
All three components have access to tools and memory.
The cycle is: Planner creates a plan → Evaluator validates it → Executor runs it → Planner assesses the results and decides whether the task is complete or if another round of planning is needed.
Let’s see how our Nova research agent would behave using the Plan-and-Execute strategy. We will ask her the same task: “How can I evaluate AI Agents using LLM Judges?”
Round 1: Plan → Evaluate → Execute → Decide
PLANNING: The Planner generates a multi-step plan:
Generate 3 broad research queries.
Execute Perplexity searches for all 3 queries (parallel).
Scrape the top 5 URLs from the results (parallel).
Search GitHub for relevant frameworks (parallel).
Summarize all findings.
EVALUATION: The Evaluator reviews the plan and approves it for execution.
EXECUTION: The Executor runs all steps, leveraging parallelization for speed. It gathers articles, code repos, and produces a summary.
DECISION: The Planner assesses the results. It finds that the basics are covered but identifies gaps: no information on handling judge disagreements or calibration techniques. It decides a second round is needed.
Round 2: Replan → Evaluate → Execute → Complete
REPLANNING: The Planner creates a new plan focused on the identified gaps:
Generate 2 targeted queries on inter-rater reliability and calibration.
Execute Perplexity searches (parallel).
Scrape URLs on calibration methods (parallel).
Synthesize findings from both rounds.
EVALUATION: The Evaluator approves the new, more targeted plan.
EXECUTION: The Executor runs the new plan steps.
DECISION: The Planner reviews the final results, confirms all gaps are addressed, and decides the task is complete, delivering the final report.
The key difference is that ReAct is making one decision at a time, while Plan-and-Execute is creating a batch plan and executing it efficiently. You can think of ReAct as a special case of Plan-and-Execute where the plan only ever contains a single step. That’s why, for ReAct, it doesn’t really make sense to have the evaluation step.
Here is a simple example of how the Plan-and-Execute pattern looks in Python.
First, we define the
Planner,Evaluator, andExecutorcomponents.
class Planner:
def __init__(self, model):
self.model = model
def generate_plan(self, task, history=”“):
prompt = f”Task: {task}\nHistory: {history}\nGenerate a detailed, step-by-step plan.”
plan_str = self.model.generate_content(prompt).text
return plan_str.split(”\n”)
class Evaluator:
def __init__(self, model):
self.model = model
def validate_plan(self, plan):
prompt = f”Is this a good plan?\n\n{plan}\n\nRespond with ‘YES’ or ‘NO’.”
response = self.model.generate_content(prompt).text
return “YES” in response
class Executor:
def __init__(self, tools):
self.tools = tools
def run_plan(self, plan):
results = []
for step in plan:
# Simplified parsing of “TOOL(ARG1=VAL1, ...)”
tool_name = step.split(”(”)[0]
# ... argument parsing logic ...
result = self.tools[tool_name](**args)
results.append(result)
return resultsThe main workflow loop coordinates these components.
def plan_and_execute_agent(task: str):
model = genai.Client(”gemini-2.5-flash”)
planner = Planner(model)
evaluator = Evaluator(model)
executor = Executor(TOOLS)
history = “”
while True:
plan = planner.generate_plan(task, history)
if not evaluator.validate_plan(plan):
history += f”\nRejected Plan: {plan}”
continue # Re-plan
execution_results = executor.run_plan(plan)
history += f”\nExecuted Plan: {plan}\nResults: {execution_results}”
# Another LLM call to decide if the task is done
is_done_prompt = f”Task: {task}\nHistory: {history}\nIs the task complete?”
if “YES” in model.generate_content(is_done_prompt).text:
break
return historyThe upfront structure of Plan-and-Execute improves efficiency and reliability for well-defined tasks, making it easier to control costs and latency. However, this pattern is less flexible for highly exploratory problems where the path forward is uncertain. It also carries the risk of rigidly adhering to an imperfect initial plan, which may require frequent and costly re-planning cycles if the environment changes unexpectedly.
That’s why in reality, your job as an AI Engineer is to decide what is the best method to design your planning engine. In most scenarios, you will end up writing a custom planning solution that works for your given domain and use case.
Still, at their roots, these patterns power real-world systems like deep research, coding assistants, and vertical AI agents. Before we wrap up, let’s look at one final trick: how modern LLMs integrate planning and execution into a single API call.
Planning and Executing with Modern Reasoning LLMs
Modern LLMs, more exactly reasoning LLMs, have started to provide a “thinking” feature which is equivalent to the planning phase from both patterns. This simplifies the implementation of ReAct or Plan-and-Execute agents, but conceptually, nothing changes.
Planning and executing are still separated into two steps, but this time the model first “thinks” or “reasons” in an internal trace managed by the API, which is entirely separate from the final output it generates. In other words, this internal chatter (the planning) is not part of the final output. Which means, there is a clear separation between the planning and executing phase [9].
The biggest benefit is that we can couple “thinking” and “taking action” into a single API call, which makes the system faster, cheaper, and simplifies the codebase.
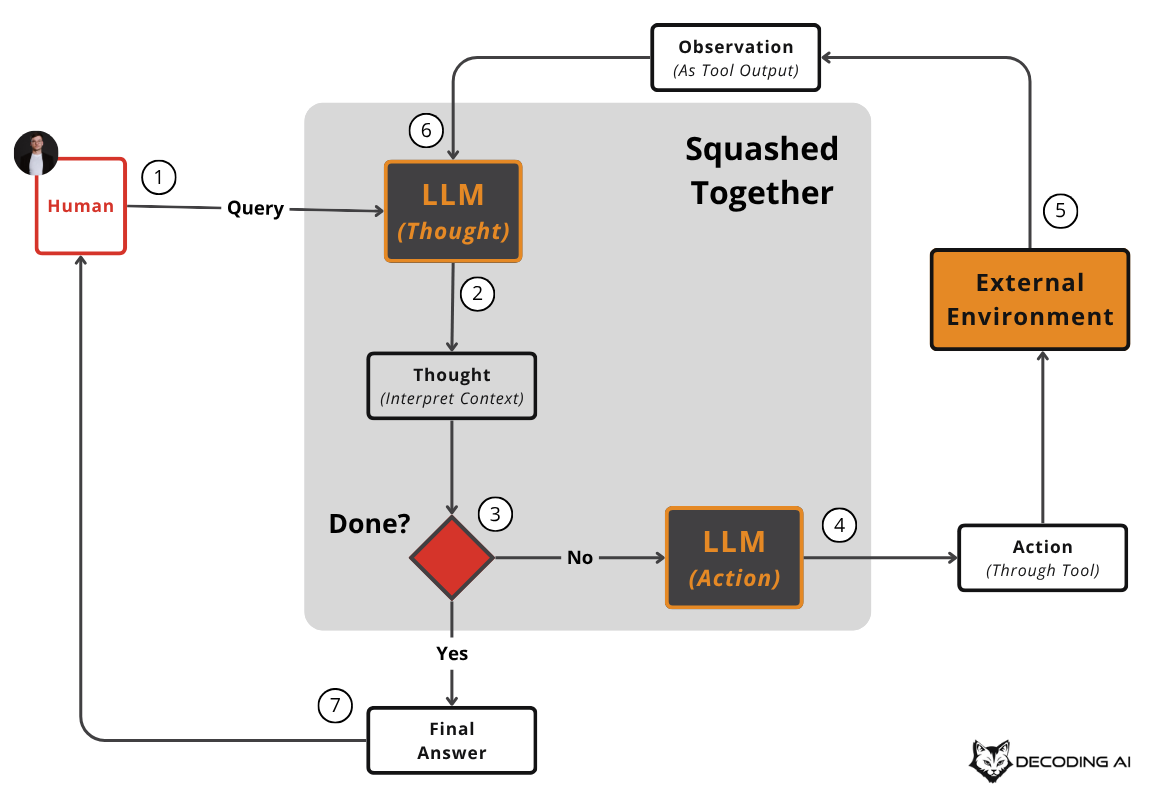
Everything else remains the same. More exactly, we input the task, the model does the thinking into a different scope, then it outputs tool calls ready to be parsed. Modern reasoning models have simply squashed the planning and execution steps into one.
Here is a simple conceptual example using Gemini of how you might interact with such a feature.
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model=”gemini-2.5-pro”,
contents=”Provide a list of 3 famous physicists and their key contributions”,
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(thinking_budget=1024)
# Turn off thinking:
# thinking_config=types.ThinkingConfig(thinking_budget=0)
# Turn on dynamic thinking:
# thinking_config=types.ThinkingConfig(thinking_budget=-1)
),
)
# Access thought (planning)
print(response.thought)
# Access final output (action)
print(response.text)We won’t go into more depth into reasoning models, but it’s important to know this detail as all modern agentic implementations use this optimization.
Connecting Point A to B
By introducing “planning”, we are giving the LLM a lot of autonomy. We specify only the start, point A, and the expected end, point B. Then, we let the LLM figure out on its own how to connect point A to B through planning, executing, and observing based on feedback from the environment until it reaches point B.
As we’ve seen in the workflow patterns article, where most of the decision-making was hardcoded into code, here all the actions are taken through tools which are dynamically picked by the agent. We let the agent figure out how to connect the tools through its planning engine to reach a desired task. Based on our autonomy slider article, this is considered a “full agentic” design.
To conclude ReAct and Plan-and-Execute are the foundational patterns of every AI agent. Most modern solutions use some derivative of them. As long as you understand these two, you are well-equipped to build your own custom solutions or understand others’.
Remember that this article is part of a longer series of 9 pieces on the AI Agents Foundations that will give you the tools to morph from a Python developer to an AI Engineer.
Here’s our roadmap:
Planning: ReAct & Plan-and-Execute ← You just finished this one.
ReAct Agents From Scratch ← Move to this one
See you next week.
What’s your take on today’s topic? Do you agree, disagree, or is there something I missed?
If you enjoyed this article, the ultimate compliment is to share our work.
Go Deeper
Everything you learned in this article, from building evals datasets to evaluators, comes from the AI Evals & Observability module of our Agentic AI Engineering self-paced course.
Your path to agentic AI for production. Built in partnership with Towards AI.
Across 34 lessons (articles, videos, and a lot of code), you’ll design, build, evaluate, and deploy production-grade AI agents end to end. By the final lesson, you’ll have built a multi-agent system that orchestrates Nova (a deep research agent) and Brown (a full writing workflow), plus a capstone project where you apply everything on your own.
Three portfolio projects and a certificate to show off in interviews. Plus a Discord community where you have direct access to other industry experts and me.
Rated 4.9/5 ⭐️ by 190+ early students — “Every AI Engineer needs a course like this.”
Not ready to commit? We also prepared a free 6-day email course to reveal the 6 critical mistakes that silently destroy agentic systems. Get the free email course.
Thanks again to Opik for sponsoring the series and keeping it free!

If you want to monitor, evaluate and optimize your AI workflows and agents:
References
(n.d.). Agentic Reasoning. IBM. https://www.ibm.com/think/topics/agentic-reasoning
(n.d.). AI Agent Orchestration. IBM. https://www.ibm.com/think/topics/ai-agent-orchestration
(n.d.). What is a ReAct agent?. IBM. https://www.ibm.com/think/topics/react-agent
Schluntz, E., & Zhang, B. (n.d.). Building effective agents. Anthropic. https://www.anthropic.com/engineering/building-effective-agents
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). ReAct: Synergizing reasoning and acting in language models. arXiv. https://arxiv.org/pdf/2210.03629
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E., Le, Q., & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. arXiv. https://arxiv.org/abs/2201.11903
(n.d.). What is Chain of Thought Prompting?. ORQ.ai. https://orq.ai/blog/what-is-chain-of-thought-prompting
(n.d.). Plan-and-Execute vs. ReAct Agents for LLM-Powered Workflows. LangChain Blog. https://blog.langchain.com/planning-agents/
(n.d.). Using extended thinking. AWS Bedrock User Guide. https://docs.aws.amazon.com/bedrock/latest/userguide/claude-messages-extended-thinking.html
Images
If not otherwise stated, all images are created by the author.
Great breakdown! Planning truly is the bridge between simple tool loops and real agentic behavior. Separating planning from execution is the step most devs miss, and understanding ReAct vs. Plan-and-Execute is essential for building reliable AI agents.
AI agents are the mooooooooooooove