

Stop Converting Documents to Text. You're Doing It Wrong.
How to work with multimodal agents: images, PDFs, audio, and... text.

Welcome to the AI Agents Foundations series: A 9-part journey from Python developer to AI Engineer. Made by busy people. For busy people.
Everyone’s talking about AI agents. But what actually is an agent? When do we need them? How do they plan and use tools? How do we pick the correct AI tools and agentic architecture? …and most importantly, where do we even start?
To answer all these questions (and more!), We’ve started a 9-article straight-to-the-point series to build the skills and mental models to ship real AI agents in production.
We will write everything from scratch, jumping directly into the building blocks that will teach you “how to fish”.
What’s ahead:
Multimodal Agents ← You are here
By the end, you’ll have a deep understanding of how to design agents that think, plan, and execute—and most importantly, how to integrate them in your AI apps without being overly reliant on any AI framework.
Let’s get started.
Opik: Open-Source LLMOps Platform (Sponsored)
This AI Agents Foundations series is brought to you by Opik (created by Comet), the LLMOps open-source platform used by Uber, Etsy, Netflix, and more.
Comet, through its free events, is dedicated to helping the AI community keep up on the state-of-the-art LLMOps topics, such as:
Detecting hallucinations in huge context windows.
Defining custom AI eval metrics for your business use case
Building LLM judges that don’t return entirely different results each run.
These are old problems… But applying them in production isn’t! Because the reality is that it’s tough to make them work at scale. All problems Opik can help you with (at least it helps us).

Still… That’s why Comet constantly offers free, hands-on events on how to solve LLMOps problems in production, so you can properly move from theory to shipping AI apps.
Check out their free events on LLM evaluation and observability here:
Here is what’s next on their list, hosted by Claire Longo:
And more events are added each month!
Multimodal Agents
When I first started building AI agents, I hit a frustrating wall. I was comfortable manipulating text, but the moment I had to integrate multimodal data, such as images, audio, and especially documents like PDFs, my elegant architectures turned into messy hacks. I spent weeks building complex pipelines that tried to force everything into text. I chained OCR engines to scrape PDFs, layout detection models to identify tables, and separate classifiers to handle images. It was a brittle, slow, and expensive solution that broke every time a document layout changed.
The breakthrough came when I realized I was solving the wrong problem. I didn’t need to convert documents to text. I needed to treat them as images. Once I understood that every PDF page is effectively an image and that modern LLMs can “see” just as well as they can read, the complexity vanished. I could completely skip the OCR purgatory and focus on the three core inputs of an LLM: text, images, and audio.
This shift is essential because real-world AI applications rarely exist in a text-only vacuum. As human beings, we process information visually and audibly. Enterprise applications mirror this reality. They need to manipulate private data from warehouses and lakes that is inherently multimodal: financial reports with complex charts, technical diagrams, building sketches, and audio logs.
The old approach of normalizing everything to text it’s lossy. When you translate a complex diagram or a chart into text, you lose the spatial relationships, the colors, and the context. You lose the information that matters most. By processing data in its native format, we preserve this rich visual information, resulting in systems that are faster, cheaper, and significantly more performant.
Ultimately, as data is made for humans, you want the LLM to process the data as close as a human would, which often is visually.
Here is what we will cover:
Foundations of Multimodal LLMs: An intuition on how models process visual and textual tokens together.
Practical Implementation: How to work with images and PDFs using the Gemini API.
Multimodal State Management: How to structure agent memory for mixed modalities.
Building the Agent: A step-by-step guide to building a multimodal ReAct agent.
The Need for Multimodal AI
We want to process multimodal data to access our surroundings. However, the rise of multimodal LLMs is driven by a more subtle force: enterprise requirements. Enterprise applications work heavily with documents. The most critical example illustrating the need for multimodal data is processing PDF documents. Once we walk through this example, you will see how this core problem maps to other modalities like image, audio, or video.
Previously, we tried to normalize everything to text before passing it into an AI model. This approach has many flaws because we lose a substantial amount of information during translation. For example, when encountering diagrams, charts, or sketches in a document, it is impossible to fully reproduce them in text.
The traditional document processing workflow, often used for invoices, documentation, or reports, relies on the following four essential steps:
Document Preprocessing (e.g., Noise Removal)
Layout Detection (Text, Tables, Diagrams)
OCR Models (for Text) & Specialized Models (for Tables, Diagrams)
Output Structured Data (JSON/Metadata)
This workflow has too many moving pieces. We need layout detection models, OCR models for text, and specialized models for each expected data structure, such as tables or charts. This makes the system rigid. If a document contains a chart type we don’t have a model for, the pipeline fails. It is also slow and costly because we have to chain multiple model calls.
Most importantly, we face performance challenges. The multi-step nature creates a cascade effect where errors compound at each stage. Advanced OCR engines struggle with handwritten text, poor scans, stylized fonts, or complex layouts like nested tables and building sketches [9], [11].

If we try to translate other data formats to text, we lose information. This is true for any modality:
Audio to Text: We lose tone, pitch, and emotion.
Image to Text: We lose spatial information, color, and context.
Video to Text: We lose temporal dynamics and visual context.
Modern AI solutions use multimodal LLMs, such as Gemini, GPT-4o, Claude or other open-source models. These models can directly interpret text, images, or PDFs as native input. This completely bypasses the unstable OCR workflow.
Thus, let’s understand how multimodal LLMs work.
Foundations of Multimodal LLMs
To use LLMs with images and documents, you need an intuition of how multimodality works. You do not need to understand every research detail. But knowing the architecture helps you deploy, optimize, and monitor them.
There are two common approaches to building multimodal LLMs: the Unified Embedding Decoder Architecture and the Cross-modality Attention Architecture [1].

1. Unified Embedding Decoder Architecture
In this approach, we encode the text and image separately, concatenate their embeddings into a single vector, and pass the resulting vector to the LLM.
Thus, on top of a standard LLM architecture, you need a vision encoder that maps the image to an embedding that’s within the same vector space as the text. So, when the text and image embeddings are merged, the LLM can make sense of both.

2. Cross-modality Attention Architecture
In the second approach, instead of passing the image embeddings along with the text embeddings at the input, we inject them directly into the attention module. We still need an image encoder that projects the image into the same vector space as the text, but we inject it deeper within the architecture.

Image Encoders
Both architectures rely on image encoders. To understand them, we can draw a parallel between text tokenization and image patching. Just as we split text into sub-word tokens, we split images into patches.

The output has the same structure and dimensions as text embeddings. However, they need to be aligned in the vector space. We do this through a linear projection module. Popular image encoder models include CLIP, OpenCLIP, and SigLIP [3].
Importantly, these encoders are also used in Multimodal RAG. They allow us to find semantic similarities between images and text.

You can replicate the same strategy between different modalities, such as text, image, document, and audio vectors, as long as you have an encoder that maps the data in the same vector space.
Trade-offs and Modern Landscape
The Unified Embedding Decoder approach is simpler to implement (you just concatenate tokens) and generally yields higher accuracy in OCR-related tasks. The Cross-modality Attention approach is more computationally efficient for high-resolution images because we don’t have to pass all tokens as an input sequence. Instead, we inject them directly into the attention mechanism. Hybrid approaches exist to combine these benefits.
In 2025, most leading LLMs are multimodal. Open-source examples include Llama, Gemma, and Qwen. Closed-source examples include GPT, Gemini, and Claude.
A quick note on Multimodal LLMs vs. Diffusion Models: Diffusion models (like Midjourney) generate images from noise. Multimodal LLMs (like GPT) understand images and can sometimes generate them, but they are architecturally different. In an agent workflow, diffusion models are typically used as tools, not as the reasoning model.
We had to keep this section super short. Still, if you want to learn more about the architecture of multimodal LLMs, we definitely recommend this article by Sebastian Raschka, PhD, from which we took most of the images in this section.
Now that we understand how LLMs can directly input images or documents, let’s see how this works in practice.
Applying Multimodal LLMs to Images and Documents
To better understand how multimodal LLMs work, let’s write a few examples using Gemini to show you some best practices when working with images and documents, such as PDFs.
There are three core ways to process multimodal data with LLMs:
Raw bytes: The easiest way to work with LLMs. However, when storing the item in a database, it can easily get corrupted as most databases interpret the input as text/strings instead of bytes.
Base64: A way to encode raw bytes as strings. This is useful for storing images or documents directly in a database (e.g., PostgreSQL, MongoDB) without corruption. The downside is that the file size increases by approximately 33%.
URLs: The standard for enterprise scenarios. You store data in a data lake like AWS S3 or GCP Buckets. The LLM downloads the media directly from the bucket. As the file never sees your server, this reduces network latency for your application. This is the most efficient option for scale.
Now, let’s dig into the code. We will show you a couple of simple examples of how to manipulate images and PDFs with these 3 methods using the Google GenAI SDK. In the following sections, we will build a simple agent that combines everything into a single unified layer.
First, we set up our client and display a sample image.
from google import genai
from google.genai import types
from PIL import Image
import io
client = genai.Client()
MODEL_ID = “gemini-2.5-flash”We load the image as raw bytes. We use
WEBPformat because it is efficient. For example, we can call the LLM to generate a caption for an image or compare two images.

image_bytes_1 = load_image_as_bytes(”images/image_1.jpeg”, format="WEBP")
image_bytes_2 = load_image_as_bytes(”images/image_2.jpeg”, format=”WEBP”)
# Single image captioning
response = client.models.generate_content(
model=MODEL_ID,
contents=[
types.Part.from_bytes(data=image_bytes_1, mime_type=”image/webp”),
“Tell me what is in this image in one paragraph.”,
],
)
print(f"Caption: {response.text}")
# Comparing multiple images
response = client.models.generate_content(
model=MODEL_ID,
contents=[
types.Part.from_bytes(data=image_bytes_1, mime_type=”image/webp”),
types.Part.from_bytes(data=image_bytes_2, mime_type=”image/webp”),
“What’s the difference between these two images?”,
],
)
print(f"Difference: {response.text}")It outputs:
Caption: An image of a gray kitten and a robot...
Difference: The primary difference between the two images is the nature of the interaction...We can also process the image as a Base64 encoded string. Notice that the logic is similar, but we encode the bytes first.
import base64
image_base64 = base64.b64encode(image_bytes_1).decode(”utf-8”)
response = client.models.generate_content(
model=MODEL_ID,
contents=[
types.Part.from_bytes(data=image_base64, mime_type=”image/webp”),
“Tell me what is in this image.”,
],
)If we compute the difference in size between base64 and bytes, the base64 one will be ~33% larger (but at least the data doesn’t get corrupted).
f”Size increase: {(len(image_base64) - len(image_bytes_1)) / len(image_bytes_1) * 100:.2f}%”For URLs, Gemini works like a charm with GCS Buckets. We used this at ZTRON and it worked like a charm:
response = client.models.generate_content(
model=MODEL_ID,
contents=[
types.Part.from_uri(uri=”gs://gemini-images/image_1.jpeg”, mime_type=”image/webp”),
“Tell me what is in this image.”,
],
)Let’s try a more complex task: Object Detection. We use Pydantic to define the output structure, using the knowledge from Lesson 3.
from pydantic import BaseModel
class BoundingBox(BaseModel):
ymin: float
xmin: float
ymax: float
xmax: float
label: str
class Detections(BaseModel):
bounding_boxes: list[BoundingBox]
prompt = “Detect all prominent items. Return 2d boxes normalized to 0-1000.”
response = client.models.generate_content(
model=MODEL_ID,
contents=[types.Part.from_bytes(data=image_bytes_1, mime_type=”image/webp”), prompt],
config=types.GenerateContentConfig(
response_mime_type=”application/json”,
response_schema=Detections
),
)
print(response.parsed)It outputs:
bounding_boxes=[BoundingBox(ymin=272.0, xmin=28.0, ymax=801.0, xmax=535.0, label=’kitten’), ...]
Now, let’s process PDFs. Because we use a multimodal model, the process is identical to images. We load the PDF as bytes and pass it to the model.

attention_paper.pdf sample

pdf_bytes = open(”pdfs/attention_paper.pdf”, “rb”).read()
response = client.models.generate_content(
model=MODEL_ID,
contents=[
types.Part.from_bytes(data=pdf_bytes, mime_type=”application/pdf”),
“What is this document about? Provide a brief summary.”,
],
)
print(response.text)It outputs:
This document introduces the Transformer, a novel neural network architecture for sequence transduction...We can also process PDFs as public URLs. This is useful for analyzing documents directly from the web without downloading them first. We use the
url_contexttool.
response = client.models.generate_content(
model=MODEL_ID,
contents=”Based on the provided paper as a PDF, tell me how ReAct works: https://arxiv.org/pdf/2210.03629”,
config=types.GenerateContentConfig(tools=[{”url_context”: {}}]),
)
print(response.text)It outputs:
The ReAct (Reasoning and Acting) paradigm is a method that combines verbal reasoning traces with task-specific actions...Finally, we can perform Object Detection on PDF pages. This is powerful for extracting diagrams or tables. We treat the PDF page as an image.
page_image_bytes = load_image_as_bytes(”images/attention_page_1.jpeg”)
prompt = “Detect all the diagrams from the provided image as 2d bounding boxes.”
response = client.models.generate_content(
model=MODEL_ID,
contents=[types.Part.from_bytes(data=page_image_bytes, mime_type=”image/webp”), prompt],
config=types.GenerateContentConfig(
response_mime_type=”application/json”,
response_schema=Detections
),
)
Processing PDFs as images is a concept popularized by the ColPali paper [5], which demonstrated that modern Vision Language Models (VLMs) can retrieve documents more effectively by “looking” at them rather than extracting text.
Foundations of Multimodal AI Agents
What if we want to use these methods within an Agent?
Agents manage their internal state, the short-term memory, as a list of messages. This usually translates to a list of dictionaries or JSON objects. When transitioning from text-only to multimodal, the structure changes slightly. We need a way to flag the data type and model the data using the formats we just discussed (URL, Base64, Binary).
We move from a list of text-only JSONs to a list of JSONs containing a mix of modalities. Each item can be text, an image, or audio. As long as the LLM can process these modalities, our job is to properly manage them in short-term memory, retrieve them from long-term memory, and pass them in the right encoding.
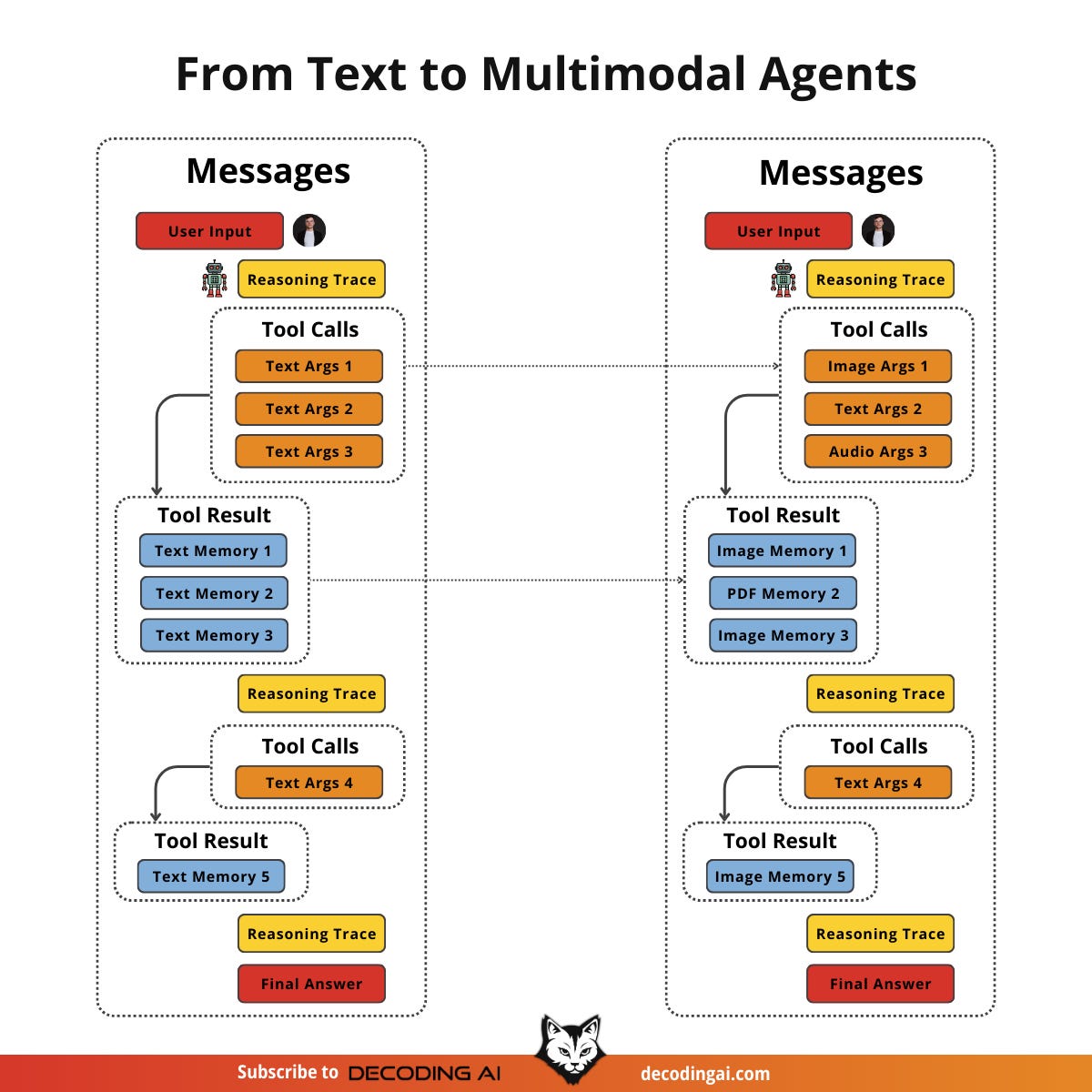
Retrieval becomes more interesting in this context. We still query our long-term memory, but now we can use multimodal similarities. We can use an image from short-term memory to query for similar images, documents, or audio chunks.
From an architectural point of view, a multimodal agentic RAG looks like any other agentic RAG system. However, this is where you will feel the real need for semantic search. With text, you can get far with keyword filters or SQL. But with images or audio, you cannot rely on keywords. You must use vector similarity to find relationships between data types.
Let’s see how we can model this bag of mixed messages with an example.
Building Multimodal AI Agents
Let’s take this further and design an agentic RAG system. We assume we have a vector database filled with images, audio data, PDFs (converted to images), and text. We also assume we have a multimodal embedding model that supports text-to-image, image-to-audio, and text-to-audio embeddings.
For simplicity, we will mock the retrieval tools that access our vector database and other MCP servers for Google Drive or local screenshots.
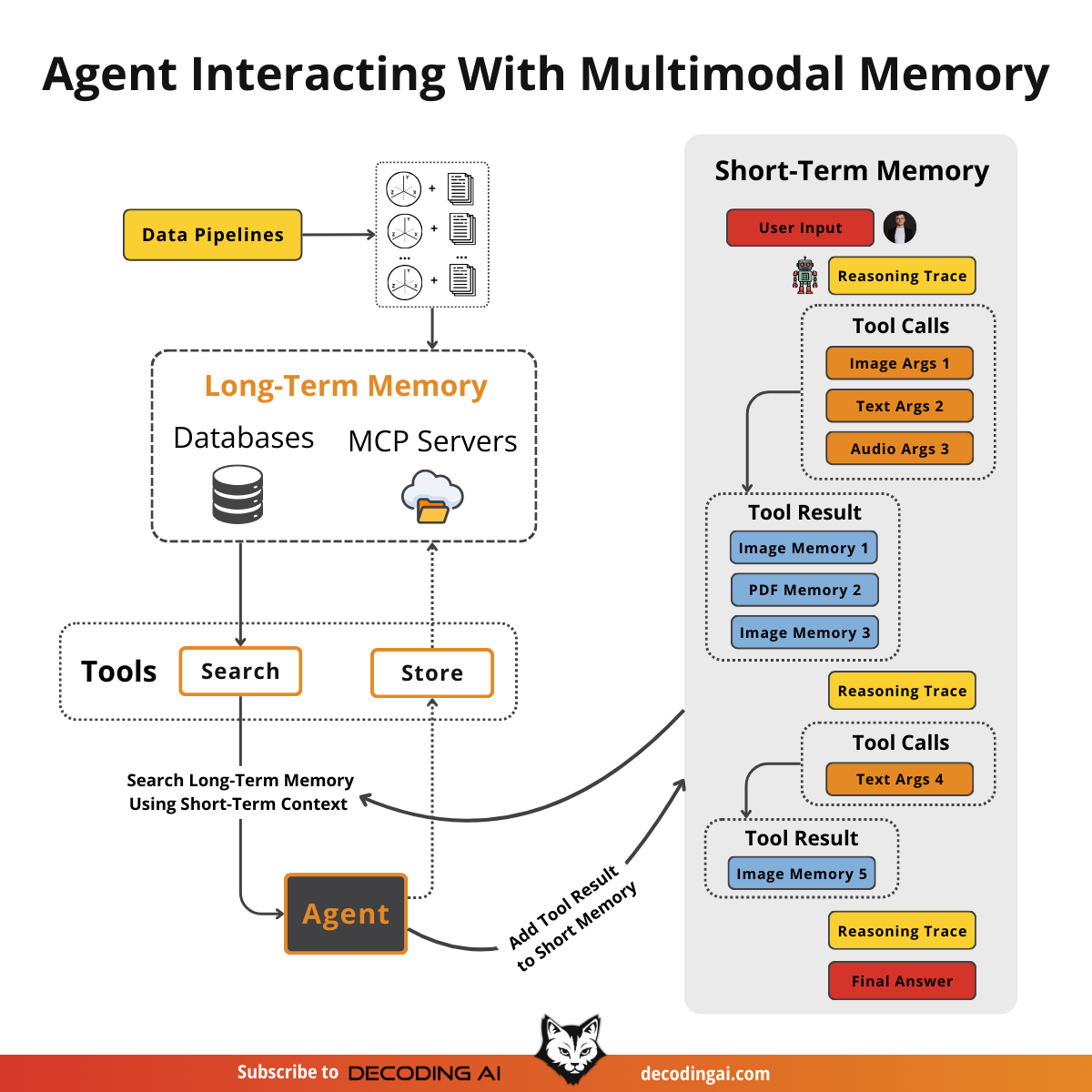
Our main focus is on managing the short-term memory as a list of mixed-modality JSONs. We want the agent to retrieve context from its current multimodal state, leveraging its multimodal retrieval tools, provide an answer, and repeat until the task is complete.
First, we define our multimodal tools. In a real application, these would query a vector DB like Qdrant or Pinecone using a multimodal embedding model.
def text_image_search_tool(query: str):
“”“Search for images using text description.”“”
pass
def image_to_image_search_tool(image_data: str):
“”“Find images visually similar to the input image.”“”
pass
def image_audio_search_tool(image_data: str):
“”“Find audio clips relevant to the image content.”“”
pass
def image_document_search_tool(image_data: str):
“”“Find documents visually similar to the image.”“”
pass
def google_drive_document_search_tool(image_data: str):
“”“Search Google Drive for documents related to the image.”“”
pass
def computer_screen_shoot_tool():
“”“Take a screenshot of the user’s screen.”“”
return “<base64_image_string>”We define the
build_react_agentfunction that creates ReAct agents using LangGraph. We use a system prompt that explicitly instructs the agent to handle multimodal inputs.
from langgraph.prebuilt import create_react_agent
from langchain_google_genai import ChatGoogleGenerativeAI
def build_react_agent():
system_prompt = “”“You are a multimodal AI assistant.
You can see images, read documents, and listen to audio.
When asked about visual content, use your tools to retrieve relevant context.
Always analyze the visual features (colors, objects) or audio features (pitch, tone) in your search results.”“”
model = ChatGoogleGenerativeAI(model=”gemini-2.5-pro”)
tools = [
text_image_search_tool,
image_to_image_search_tool,
image_audio_search_tool,
image_document_search_tool,
google_drive_document_search_tool,
computer_screen_shoot_tool,
]
agent = create_react_agent(model, tools, system_prompt)
return agentWe build the
react_agentand run it with a query that requires multimodal reasoning: “Based on what I am looking at, retrieve all relevant images, audio, and documents.”
agent = build_react_agent()
response = agent.invoke({”messages”: [”Based on what I am looking at, retrieve all relevant images, audio and documents”]})Let’s look at a potential reasoning trace on how the agent would call various tools to answer this question. Then we will show how the list of JSON messages grows with each step, using the Gemini API structure.
Turn 1 (Reasoning): The agent analyzes the user request and decides to call
computer_screen_shoot_tool.Turn 1 (Observation): The tool executes and returns a Base64 image. This is appended to the message history as a tool response containing
inline_data.
{
“role”: “tool”,
“name”: “computer_screen_shoot_tool”,
“parts”: [
{
“inline_data”: {
“mime_type”: “image/jpeg”,
“data”: “/9j/4AAQSkZJRg...”
}
}
]
}Turn 2 (Reasoning): The agent now has the image in its context. It analyzes the visual content (a gray kitten) and decides to call the following retrieval tools in parallel, passing the image data from the previous turn:
function_calls = [
{
“tool_name”: “image_to_image_search_tool”,
“tool_args”: {
“image_data”: “<base64_image_from_previous_turn>”
}
},
{
“tool_name”: “image_audio_search_tool”,
“tool_args”: {
“image_data”: “<base64_image_from_previous_turn>”
}
},
{
“tool_name”: “image_document_search_tool”,
“tool_args”: {
“image_data”: “<base64_image_from_previous_turn>”
}
},
{
“tool_name”: “google_drive_document_search_tool”,
“tool_args”: {
“image_data”: “<base64_image_from_previous_turn>”
}
}
]Turn 2 (Observation): The tools execute and return mixed modalities. The state is updated with these new observations, adding audio, images, and document pages to the context.
[
{
“role”: “tool”,
“name”: “image_to_image_search_tool”,
“parts”: [
{ “text”: “Found 3 similar images:” },
{
“inline_data”: {
“mime_type”: “image/jpeg”,
“data”: “/9j/4AAQSkZJRg...”
}
},
{
“inline_data”: {
“mime_type”: “image/jpeg”,
“data”: “/9j/4AAQSkZJRg...”
}
},
{
“inline_data”: {
“mime_type”: “image/jpeg”,
“data”: “/9j/4AAQSkZJRg...”
}
}
]
},
{
“role”: “tool”,
“name”: “image_audio_search_tool”,
“parts”: [
{ “text”: “Found similar audio clip (as binary data):” },
{
“inline_data”: {
“mime_type”: “audio/mp3”,
“data”: “<binary_audio_bytes>”
}
}
]
},
{
“role”: “tool”,
“name”: “image_document_search_tool”,
“parts”: [
{ “text”: “Found relevant PDF page (as base64 image):” },
{
“inline_data”: {
“mime_type”: “image/png”,
“data”: “iVBORw0KGgo...”
}
}
]
},
{
“role”: “tool”,
“name”: “google_drive_document_search_tool”,
“parts”: [
{ “text”: “Found document from Google Drive (stored in GCS bucket):” },
{
“file_data”: {
“mime_type”: “application/pdf”,
“file_uri”: “gs://my-bucket/documents/british-shorthair-guide.pdf”
}
}
]
}
]The agent compiles this into a final answer.
I analyzed your screen and found you are looking at a gray kitten.
Based on this, I retrieved:
1. 3 similar images of gray kittens (from image_to_image_search_tool, as base64).
2. An audio clip of a cat purring (from image_audio_search_tool, as binary data).
3. A PDF page about cat breeds (from image_document_search_tool, as base64 image).
4. A document from Google Drive about British Shorthair cats (from google_drive_document_search_tool, stored as URL in GCS bucket).We can now ask a follow-up question: “What is the color of my kitten?”
response = agent.invoke({”messages”: [”What is the color of my kitten?”]})Because the agent has the image in its short-term memory (the state), it does not need to use tools again. It simply looks at the Base64 data from Step 1 and answers.
At the time the agent is asked about this question, this is how its whole short-term memory looks. This is the first part up to thecomputer_screen_shoot_tooltool call.
[
{
“role”: “user”,
“parts”: [{ “text”: “Based on what I am looking at...” }]
},
{
“role”: “model”,
“parts”: [{ “function_call”: { “name”: “computer_screen_shoot_tool”, “args”: {} } }]
},
{
“role”: “tool”,
“name”: “computer_screen_shoot_tool”,
“parts”: [{ “inline_data”: { “mime_type”: “image/jpeg”, “data”: “...” } }]
}
]Here is the subsequent part of the state, showing the parallel tool calls and their multimodal outputs.
[
{
“role”: “model”,
“parts”: [
{ “function_call”: { “name”: “image_to_image_search_tool”, “args”: { “image_data”: “<base64_image_from_previous_turn>” } } },
{ “function_call”: { “name”: “image_audio_search_tool”, “args”: { “image_data”: “<base64_image_from_previous_turn>” } } },
{ “function_call”: { “name”: “image_document_search_tool”, “args”: { “image_data”: “<base64_image_from_previous_turn>” } } },
{ “function_call”: { “name”: “google_drive_document_search_tool”, “args”: { “image_data”: “<base64_image_from_previous_turn>” } } }
]
},
{
“role”: “tool”,
“name”: “image_to_image_search_tool”,
“parts”: [
{ “text”: “Found 3 similar images:” },
{ “inline_data”: { “mime_type”: “image/jpeg”, “data”: “...” } },
{ “inline_data”: { “mime_type”: “image/jpeg”, “data”: “...” } },
{ “inline_data”: { “mime_type”: “image/jpeg”, “data”: “...” } }
]
},
{
“role”: “tool”,
“name”: “image_audio_search_tool”,
“parts”: [
{ “text”: “Found similar audio clip (as binary data):” },
{ “inline_data”: { “mime_type”: “audio/mp3”, “data”: “<binary_audio_bytes>” } }
]
},
{
“role”: “tool”,
“name”: “image_document_search_tool”,
“parts”: [
{ “text”: “Found relevant PDF page (as base64 image):” },
{ “inline_data”: { “mime_type”: “image/png”, “data”: “...” } }
]
},
{
“role”: “tool”,
“name”: “google_drive_document_search_tool”,
“parts”: [
{ “text”: “Found document from Google Drive (stored in GCS bucket):” },
{ “file_data”: { “mime_type”: “application/pdf”, “file_uri”: “gs://my-bucket/documents/british-shorthair-guide.pdf” } }
]
}
]Here is the end of the state, showing the document results and the final Q&A:
[
,
{
“role”: “model”,
“parts”: [{ “text”: “I analyzed your screen...” }]
},
{
“role”: “user”,
“parts”: [{ “text”: “What is the color of my kitten?” }]
}
]And finally the model responds:
Your kitten is gray.We should probably use these LLMs for something more meaningful than just chatting about our pets. But hey, who doesn’t like a good cat/dog video? 😂
Nothing fundamental has changed in how we structure our data when switching from text-only to multimodal agents. We simply reflect the data types within the JSONs. The key is that our LLM knows how to process that data. The hard part is retrieving the correct multimodal data from our databases and indexing it properly.
Conclusion
Working with multimodal data is a fundamental skill for AI engineers. Modern AI applications rarely exist in a text-only vacuum. They interact with the complex, visual, and auditory reality of the world.
In this lesson, we moved away from the unstable, multi-step OCR pipelines of the past. We learned that modern LLMs can natively process images and documents, preserving rich context that was previously lost. We explored how to handle data as bytes, Base64, and URLs, and how to build agents that can reason across these modalities.
This concludes our AI Agents Foundations series. We started by understanding the difference between workflows and agents, mastered context engineering and structured outputs, built robust planning capabilities with ReAct, and finally gave our agents eyes and ears. You now have the foundational blocks to build production-ready AI systems.
Still, if you missed our roadmap, remember that this article is part of a longer series of 9 pieces on the AI Agents Foundations that will give you the tools to morph from a Python developer to an AI Engineer.
Here’s our roadmap:
Multimodal Agents ← You just finished this one.
🔔 P.S. I would love to see what you built after reading this series. Thus, I encourage you to message me on Substack with how this helped you. If you are excited about what you created, I will be too and share it on my socials.
See you next Tuesday.
What’s your take on today’s topic? Do you agree, disagree, or is there something I missed?
If you enjoyed this article, the ultimate compliment is to share our work.
Whenever you’re ready, here is how I can help you
Go from agent user to agent builder. Master the foundations of AI agents and turn fragile demo code into reliable, production-ready systems with my course, Agent Engineering: Building Multi-Agent Systems (made with Towards AI).
35 lessons. Pure foundations from scratch. 4 mini-projects. 2 production systems. A certificate and direct access to me & industry experts in our Discord.
Built for software and data professionals transitioning into AI engineering. Rated 5/5 with 300+ students. The first 7 lessons are free:
Not ready to commit? Start with our free Agent AI Engineering Guide, a 6-day email course on the mistakes that silently break AI agents in production.
Thanks again to Opik for sponsoring the series and keeping it free!

If you want to monitor, evaluate and optimize your AI workflows and agents:
References
Raschka, S. (2024, October 21). Understanding multimodal LLMS. Sebastian Raschka. article
Vision language models. (n.d.). NVIDIA. https://www.nvidia.com/en-us/glossary/vision-language-models/
Talebi, S. (2024, November 13). Multimodal embeddings: An introduction. Medium. https://towardsdatascience.com/multimodal-embeddings-an-introduction-5dc36975966f/
Multi-modal ML with OpenAI’s CLIP. (n.d.). Pinecone. https://www.pinecone.io/learn/series/image-search/clip/
Fostiropoulos, I., et al. (2024). ColPali: Efficient Document Retrieval with Vision Language Models. arXiv. https://arxiv.org/pdf/2407.01449v6
Image understanding. (n.d.). Google AI for Developers. https://ai.google.dev/gemini-api/docs/image-understanding
Google generative AI embeddings. (n.d.). LangChain. https://python.langchain.com/docs/integrations/text_embedding/google_generative_ai/
Agents. (n.d.). LangChain. https://langchain-ai.github.io/langgraph/agents/agents/
Complex Document Recognition: OCR Doesn’t Work and Here’s How You Fix It. (n.d.). HackerNoon. https://hackernoon.com/complex-document-recognition-ocr-doesnt-work-and-heres-how-you-fix-it
What are some real-world applications of multimodal AI? (n.d.). Milvus. https://milvus.io/ai-quick-reference/what-are-some-realworld-applications-of-multimodal-ai
Liu, J. (2025, February 24). OlmOCR-bench review: Insights and pitfalls on an OCR benchmark. LlamaIndex. https://www.llamaindex.ai/blog/olmocr-bench-review-insights-and-pitfalls-on-an-ocr-benchmark
Vectorize.io. (2024, October 26). Multimodal RAG Patterns. Vectorize.io Blog. https://vectorize.io/blog/multimodal-rag-patterns
Images
If not otherwise stated, all images are created by the author.
Great breakdown! Treating PDFs and images as native inputs is such a practical shift. Makes multimodal agents far more reliable and efficient. Multimodal memory management and native modality handling are the real differentiators for production-grade agentic systems.
Each page exported as image+embed - for one shots pixeltable is overkill, but if you need storage and some kind of versioning for more realistic workloads, pixeltable sounds interesting.
If you want to deep dive on the raw implementation you can just use any vision API and setup a pipeline that saves structured outputs for subsequent embeddings, I am trying to discover if pixeltable adds any value to this or not yet. Still getting my idea around it since the demo always shines 😅