

The AI Evals Roadmap I Wish I Had
From vibe checking to trusted agents in production

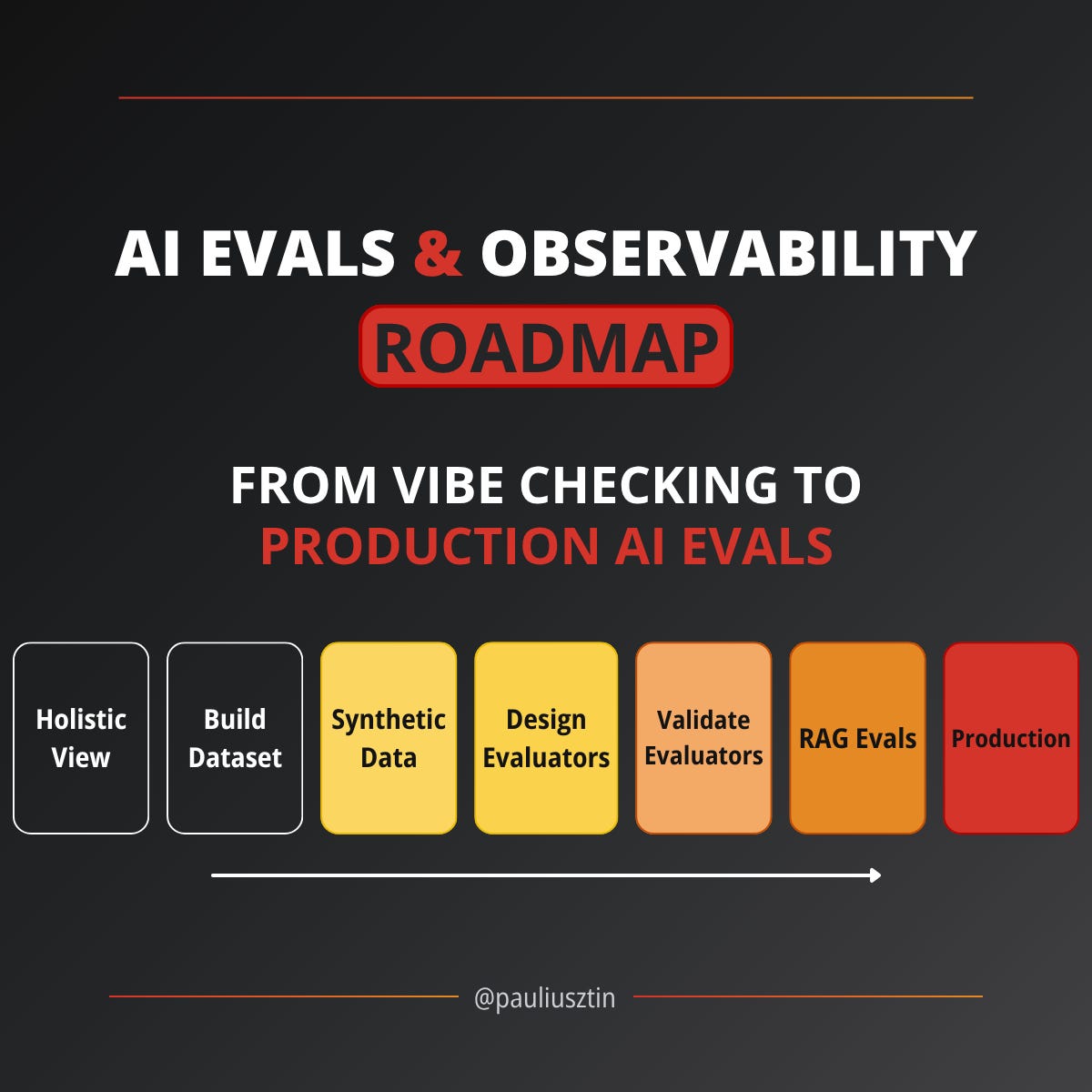
Welcome to the AI Evals & Observability series: A 7-part journey from shipping AI apps to systematically improving them. Made by busy people. For busy people.
AI Evals is the topic most AI engineers know they should invest in, but do not know where to start. I remember struggling with this myself.
I did not know how to properly integrate evals into my app until I understood there are three core layers: optimization during development, regression testing before merging, and production monitoring on live traffic. Once that clicked, everything else fell into place.
I did not know how to build LLM judges and evaluators that I could actually trust and use. Every guide I found either hand-waved the details or dumped a generic “helpfulness” metric and moved on. Instead, I needed evaluators grounded in my actual business requirements.
I did not know how to gather custom datasets without wasting too much time. I tried generating hundreds of synthetic test cases up front, but the real unlock came from learning how to organically grow a high-quality dataset from production data, starting small and letting the error-analysis flywheel do the heavy lifting.
The information was scattered across blog posts, talks, and vendor docs. Most of it focused on isolated techniques without showing how everything connects. I built this series as the structured, end-to-end guide I wish I had.
This 7-lesson series breaks it all down from first principles. By the end, you will know how to integrate AI evaluations that actually track and improve your product's performance. No vibe checking required.
The series follows a natural progression. You start by understanding where evals fit. Then, you build the dataset.
Next, you design and validate the evaluators. Finally, you handle specialized domains like RAG and see how it all works in production.
You can read front-to-back for the full journey. Alternatively, jump to the lesson that matches your current pain point. Each lesson stands on its own but references the others.
Without more yada, yada, here are the 7 lessons of the series:
(Scroll down to find more about each lesson individually.)
Everything is completely free, without any hidden costs, thanks to our sponsor, Opik ↓
Opik: Open-Source LLMOps Platform (Sponsored)
This AI Evals & Observability series is brought to you by Opik, the LLMOps open-source platform used by Uber, Etsy, Netflix, and more.
We use Opik daily across our courses and AI products. Not just for observability, but as our end-to-end evaluation harness, all from the same platform.

This series teaches you how to build evals from scratch (custom datasets, LLM judges, optimization loops, and production monitoring), while Opik gives you the platform to run everything at scale.
Here is how we use it:
Custom LLM judges: Build evaluators by defining your criteria, adding a few-shot examples, and running them across hundreds of traces automatically.
Run experiments, compare results: Test different prompts, models, or parameters from your AI app side by side. Opik scores each variant with your evaluators and shows you which one wins.
Plug evaluators into production: The same LLM judges you design for offline testing run on live traces too. Set up alarms when scores drop below your threshold so you catch regressions before users do.
Opik is fully open-source and works with custom code and with every popular AI framework or tool (including OpenClaw). You can also use the managed version for free (with 25K spans/month on their generous free tier):
↓ Now, let’s move back to the article.
Lesson 1: Integrating AI Evals Into Your AI App
To build a reliable system, you first need to know where evaluation fits into the development lifecycle.
Most teams start by “vibe checking” their AI app. They manually test a few inputs and eyeball whether the outputs look right. That works for the first version.
But the moment you start adding features, onboarding real users, or trying to improve existing capabilities, vibe checking collapses. This first article gives you the holistic map of where AI Evals fit, so you never feel lost again.
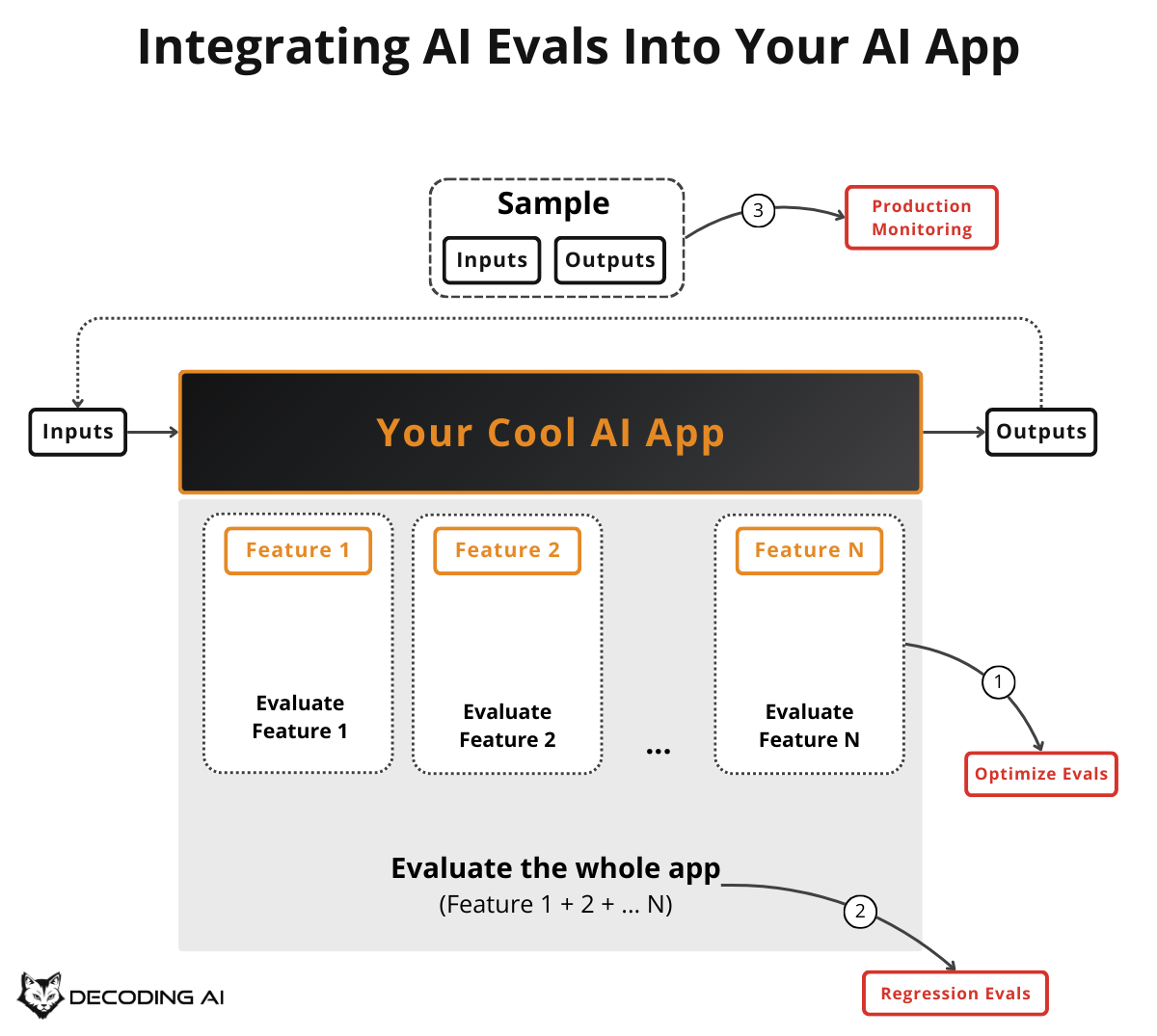
Here is what you will learn:
The three core scenarios where evals matter: optimization during development, regression testing before merging, and production monitoring on live traffic.
The difference between guardrails and evaluators. Confusing them leads to gaps in your system.
The minimum viable tech stack required to start: a custom annotation tool and an LLMOps platform.
Lesson 2: Build an AI Evals Dataset from Scratch
Once you understand where evals fit, the next step is gathering the data required to measure performance.
You cannot evaluate what you cannot measure. You cannot measure without data. Most teams either skip this step entirely or fire off a generic prompt to create 100 test cases and call it done.
This article teaches the error analysis framework. It is a practical flywheel that turns 20-50 real production traces into a growing, high-quality evals dataset.
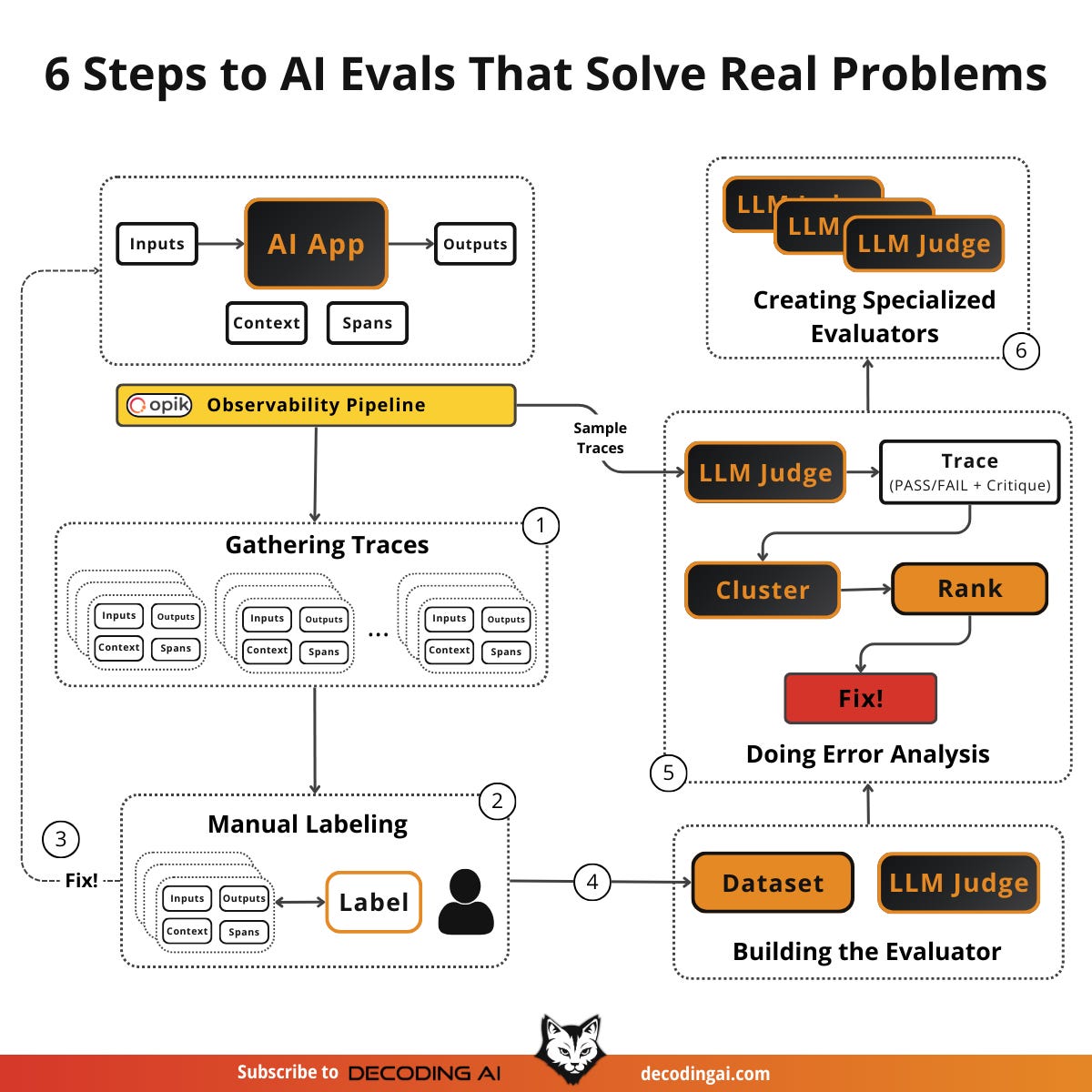
Here is what you will learn:
The error analysis flywheel: sample traces, label manually, build evaluators iteratively, perform error analysis, and create specialized evaluators.
Why one “benevolent dictator” should own labeling consistency across your team.
How to graduate from generic to specialized evaluators as your understanding deepens.
Lesson 3: Generate Synthetic Datasets for AI Evals
Production traces alone have limits. You need traffic to get data, and that traffic rarely covers every scenario. What about before you have users?
What about rare failure modes you have never seen in production? Yet! Synthetic data solves the cold start problem and fills coverage gaps.

Here is what you will learn:
Why you should generate only inputs, not outputs, and let your real app produce the outputs.
How to think in dimensions like persona, feature, scenario, and input modality to avoid mode collapse.
Tester agents for simulating multi-turn conversations.
The reverse workflow for RAG: generate questions from your knowledge base, not the other way around.
Lesson 4: How to Design Evaluators
You have the dataset. Now you need evaluators who can actually tell you whether your app is working. This is where most teams make their biggest mistake.
They grab a generic helpfulness metric off the shelf and call it done. This article teaches you how to design evaluators grounded in your actual business requirements.

Here is what you will learn:
The evaluation harness: the infrastructure that automates running evaluators across your dataset.
When to use fast, deterministic code-based evaluators versus flexible, nuanced LLM judges.
Common design mistakes
Advanced designs for multi-turn conversations and agentic workflows.
Lesson 5: How to Evaluate the Evaluator
You built an evaluator. It says everything is great. But is it?
An evaluator that validates every output is worse than no evaluator at all. It gives you false confidence. This article teaches you how to validate your evaluator against human judgment and close the gap when they disagree.

Here is what you will learn:
The iterative refinement loop: measure alignment, diagnose disagreements, adjust few-shot examples, and re-measure.
Dealing with non-determinism: why LLM judges give different answers on the same input, and how to stabilize them.
Lesson 6: RAG Evaluation: The Only 6 Metrics You Need
After mastering general evaluators, you can apply these principles to specific architectures like RAG.
RAG evaluation feels overwhelming because everyone proposes different metrics. But it does not have to be complicated. This article proves that there are exactly three variables in any RAG system: Question, Context, and Answer.
There are exactly six possible relationships between them. That is it. Every RAG metric maps to one of these six relationships.

Here is what you will learn:
The three RAG variables and six exhaustive relationships.
Tier 1: Retrieval metrics. If retrieval is broken, nothing else matters.
Tier 2: The three core RAG metrics you always need.
Tier 3: When core metrics cannot explain the failure.
Lesson 7: Lessons from 6 Months of Evals on a Production AI Companion
Theory and isolated metrics are useful. But the ultimate test is running this entire system on live user traffic.
The first six articles teach you how to build the system. This final article shows you what it looks like after six months of running it in production.
Written as a guest post by Alejandro Aboy, Senior Data Engineer at Workpath, it shares the real lessons. We cover what worked, what failed, and what they wish they had known from the start.
Here is what you will learn:
The three observability problems most teams hit: falling for generic metrics, skipping manual annotation, and not treating AI agents as data products.
How to use Opik’s architecture, including traces, spans, threads, and prompt versioning, for production monitoring and evals.
How to reverse-engineer evaluation criteria from real traces instead of guessing upfront.
How to Take the Course?
After completing these seven articles, you will have the complete mental model for AI Evals. You will understand everything from strategy to production.
As the course is 100% free, with no hidden costs or registration required, taking it is a no-brainer.
Each lesson is a free article hosted on the Decoding AI Magazine.
Just open each lesson in the order provided by us, and you are good to go:
Each lesson will guide you through the required steps.
Enjoy!
Now What?
After completing these lessons, if you want the information to stick, you have to put everything into practice by building a cool project!
I am sorry to say there is no other way to make learning worthwhile. Pick one problem and get your hands dirty with a project.
💡 Want to share your work on my socials with my 140k+ audience? If you build a project you are excited about, I will be too. Trust me! I love seeing people build cool stuff. To share it, you can contact me here.
See you next Tuesday.
What’s your opinion? Do you agree, disagree, or is there something I missed?
Enjoyed the article? The most sincere compliment is to share our work.
Go Deeper
Go from zero to production-grade AI agents with the Agentic AI Engineering self-paced course. Built in partnership with Towards AI.
Across 34 lessons (articles, videos, and a lot of code), you’ll design, build, evaluate, and deploy production-grade AI agents end to end. By the final lesson, you’ll have built a multi-agent system and a capstone project where you apply everything you've learned on your own.
Three portfolio projects and a certificate to showcase in interviews. Plus a Discord community where you have direct access to other industry experts and me.
Rated 4.9/5 ⭐️ by 300+ students — “Every AI Engineer needs a course like this.”
Not ready to commit? We also prepared a free 6-day email course to reveal the 6 critical mistakes that silently destroy agentic systems. Get the free email course.
Thanks again to Opik for sponsoring the series and keeping it free!

If you want to monitor, evaluate and optimize your AI workflows and agents:
Images
If not otherwise stated, all images are created by the author.
looks like a great course of materials. i think the llm judge eval and the future of that science is fascinating.
The three-layer framing is the thing I keep trying to explain to teams - development evals, regression before merge, production monitoring. They sound like the same thing until you actually build them and realize each layer catches completely different failure modes.
The part about trusting your LLM judges is where most teams quietly give up. Generic helpfulness metrics are easy to instrument and meaningless in practice. The hard work is writing evaluators grounded in what your product actually needs to do - and that requires somebody to first articulate what good looks like, which turns out to be a PM problem as much as an engineering one.
Looking forward to the production monitoring installment. That is where the interesting edge cases live.